
Алфавитное неравномерное двоичное кодирование. Префиксный код. Код Хаффмана
Алфавитное неравномерное двоичное кодирование— кодирование при котором символы некоторого первичного алфавита кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться.
Префиксный код в теории кодирования— код со словом переменной длины, имеющий такое свойство (выполнение условия Фано): если в код входит слово a, то для любой непустой строки b слова ab в коде не существует. Хотя префиксный код состоит из слов разной длины, эти слова можно записывать без разделительного символа.
Например, код, состоящий из слов 0, 10 и 11, является префиксным, и сообщение 01001101110 можно разбить на слова единственным образом:
0 10 0 11 0 11 10
Код, состоящий из слов 0, 10, 11 и 100, префиксным не является, и то же сообщение можно трактовать несколькими способами.
0 10 0 11 0 11 10
0 100 11 0 11 10
Префиксные коды широко используются в различных областях информационных технологий. На них основаны многие алгоритмы сжатия информации. Их используют различные протоколы. К префиксным кодам относятся такие распространённые вещи, как:
• Юникод,
• телефонные номера,
• Код Хаффмана,
• Код Фибоначчи и мн. другие.
Код Хаффмана
Идея, положенная в основу кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код. Это нужно, так как мы хотим, чтобы, когда мы обработали весь ввод, самые частотные символы заняли меньше всего места (и меньше, чем они занимали в оригинале), а самые редкие — побольше (но так как они редкие, это не имеет значения). В данной статье я решил, что символ будет иметь длину 8 бит, то есть, будет соответствовать печатному знаку.
Я мог бы с той же простотой взять символ длиной в 16 бит (то есть, состоящий из двух печатных знаков), равно как и 10 бит, 20 и так далее. Размер символа выбирается, исходя из строки ввода, которую мы ожидаем встретить. Например, если бы я собрался кодировать сырые видеофайлы, я бы приравнял размер символа к размеру пикселя. Помните, что при уменьшении или увеличении размера символа меняется и размер кода для каждого символа, потому что чем больше размер, тем больше символов можно закодировать этим размером кода. Комбинаций нулей и единичек, подходящих для восьми бит, меньше, чем для шестнадцати. Поэтому вы должны подобрать размер символа, исходя из того по какому принципу данные повторяются в вашей последовательности.
Предположим, у нас есть строка «beep boop beer!», для которой, в её текущем виде, на каждый знак тратится по одному байту. Это означает, что вся строка целиком занимает 15*8 = 120 бит памяти. После кодирования строка займёт 40 бит.
Чтобы получить код для каждого символа строки «beep boop beer!»,на основе его частотности, нам надо построить бинарное дерево, такое, что каждый лист этого дерева будет содержать символ (печатный знак из строки).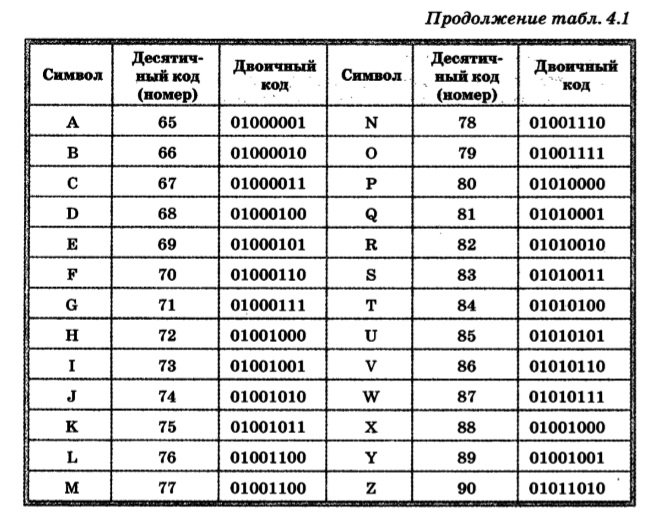 Дерево будет строиться от листьев к корню, в том смысле, что символы с меньшей частотой будут дальше от корня, чем символы с большей. Скоро вы увидите, для чего это нужно.
Дерево будет строиться от листьев к корню, в том смысле, что символы с меньшей частотой будут дальше от корня, чем символы с большей. Скоро вы увидите, для чего это нужно.
Чтобы построить дерево, мы воспользуемся слегка модифицированной очередью с приоритетами — первыми из неё будут извлекаться элементы с наименьшим приоритетом, а не наибольшим. Это нужно, чтобы строить дерево от листьев к корню.
Для начала посчитаем частоты всех символов:
После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета:
Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.
Повторим те же шаги и получим последовательно:
Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево:
Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:
Если мы так сделаем, то получим следующие коды для символов:
Чтобы расшифровать закодированную строку, нам надо, соответственно, просто идти по дереву, сворачивая в соответствующую каждому биту сторону до тех пор, пока мы не достигнем листа.
Важно иметь в виду, что каждый код не является префиксом для кода другого символа. В нашем примере, если 00 — это код для „b“, то 000 не может оказаться чьим-либо кодом, потому что иначе мы получим конфликт. Мы никогда не достигли бы этого символа в дереве, так как останавливались бы ещё на „b“.
Назад: Алфавитное неравномерное двоичное кодирование. Префиксный код. Код Хаффмана
Двоичное кодирование (8 класс) Информатика и ИКТ
В общем случае, чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка. Таких языков тысячи. Каждый язык имеет свой алфавит.
Алфавит — набор отличных друг от друга символов (знаков), используемых для представления информации. Мощность алфавита — это количество входящих в него символов (знаков).
Алфавит, содержащий два символа, называется двоичным алфавитом (см.
Рассмотрим в качестве символов двоичного алфавита цифры 0 и 1.
Покажем, что любой алфавит можно заменить двоичным алфавитом. Прежде всего, присвоим каждому символу рассматриваемого алфавита порядковый номер. Номер представим с помощью двоичного алфавита. Полученный двоичный код будем считать кодом исходного символа.
Если мощность исходного алфавита больше двух, то для кодирования символа этого алфавита потребуется не один, а несколько двоичных символов. Другими словами, порядковому номеру каждого символа исходного алфавита будет поставлена в соответствие цепочка (последовательность) из нескольких двоичных символов.
Правило двоичного кодирования символов алфавита мощности больше двух представим схемой на рисунке ниже.
Двоичные символы (0, 1) здесь берутся в заданном алфавитном порядке и размещаются слева направо.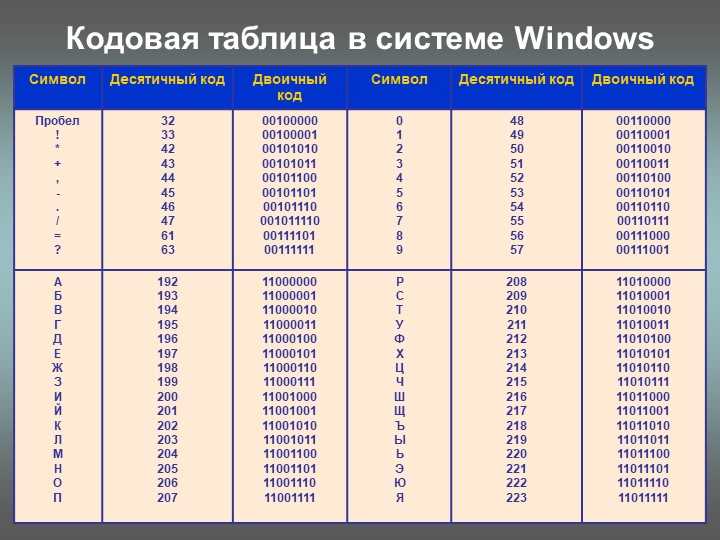 Двоичные коды (цепочки символов) читаются сверху вниз. Все цепочки из двух двоичных символов (кодовые комбинации) позволяют представить четыре различных символа произвольного алфавита:
Двоичные коды (цепочки символов) читаются сверху вниз. Все цепочки из двух двоичных символов (кодовые комбинации) позволяют представить четыре различных символа произвольного алфавита:
Цепочки из трёх двоичных символов получаются дополнением двузначных двоичных кодов справа символом 0 или 1. В итоге трёхзначных двоичных кодовых комбинаций получается 8 – вдвое больше, чем двузначных:
Соответственно, четырёхзначный двоичный код позволяет получить 16 кодовых комбинаций, пятизначный — 32, шестизначный — 64 и т. д.
Длину двоичной цепочки — количество символов в двоичном коде – называют разрядностью двоичного кода.
Обратите внимание, что 2= 2 1, 4 = 22, 8 = 23, 16 = 24, 32 = 25 и т. д.
Если количество кодовых комбинаций обозначить буквой N, а разрядность двоичного кода — буквой i, то выявленная закономерность в общем виде будет записана так: N=2i.
Задача. Вождь племени Мульти поручил своему министру разработать двоичный код и перевести в него всю важную информацию. Какой разрядности потребуется двоичный код, если алфавит, используемый племенем Мульти, содержит 16 символов? Выпишите все кодовые комбинации.
Вождь племени Мульти поручил своему министру разработать двоичный код и перевести в него всю важную информацию. Какой разрядности потребуется двоичный код, если алфавит, используемый племенем Мульти, содержит 16 символов? Выпишите все кодовые комбинации.
Решение. Так как алфавит племени Мульти состоит из 16 символов, то и кодовых комбинаций им нужно 16. В этом случае длина (разрядность) двоичного кода определяется из соотношения: 16 = 2i. Отсюда i=4.
Чтобы выписать все кодовые комбинации из четырёх 0 и 1, воспользуемся схемой на рисунке выше: 0000, 0001, 0010, 0011, 0100, 0101, 0110, 0111, 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111.
Самое главное:
- Чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка.
- Алфавит языка — набор отличных друг от друга символов, используемых для представления информации. Мощность алфавита — это количество входящих в него символов.

- Алфавит, содержащий два символа, называется двоичным алфавитом. Представление информации с помощью двоичного алфавита называют двоичным кодированием.

Вопросы и задания:
- Что такое алфавит языка?
- Что такое мощность алфавита? Может ли алфавит состоять из одного символа?
- Какие символы могут входить в двоичный алфавит?
- Сколько существует различных последовательностей из символов «плюс» и «минус» длиной ровно пять символов?
- Как связаны мощность алфавита и разрядность двоичного кода, достаточного для кодирования всех символов этого алфавита?
- Вождь племени Мульти поручил своему министру разработать двоичный код и перевести в него всю важную информацию. Достаточно ли пятиразрядного двоичного кода, если алфавит, используемый племенем Мульти, содержит 26 символов?
(Решение:
С помощью пятиразрядного двоичного кода можно закодировать 25 = 32 различных символов алфавита. Поэтому для кодирования 26 символов алфавита достаточно пятиразрядного кода. ) - От разведчика была получена следующая шифрованная радиограмма, переданная с использованием азбуки Морзе: — • • — • • — — • • — — — — •
При передаче радиограммы было потеряно разбиение на буквы, но известно, что в радиограмме использовались только следующие буквы:
(Решение:
НАИГАЧ)
 )
)Содержание
| Понравилось? | Нравится | Твитнуть |
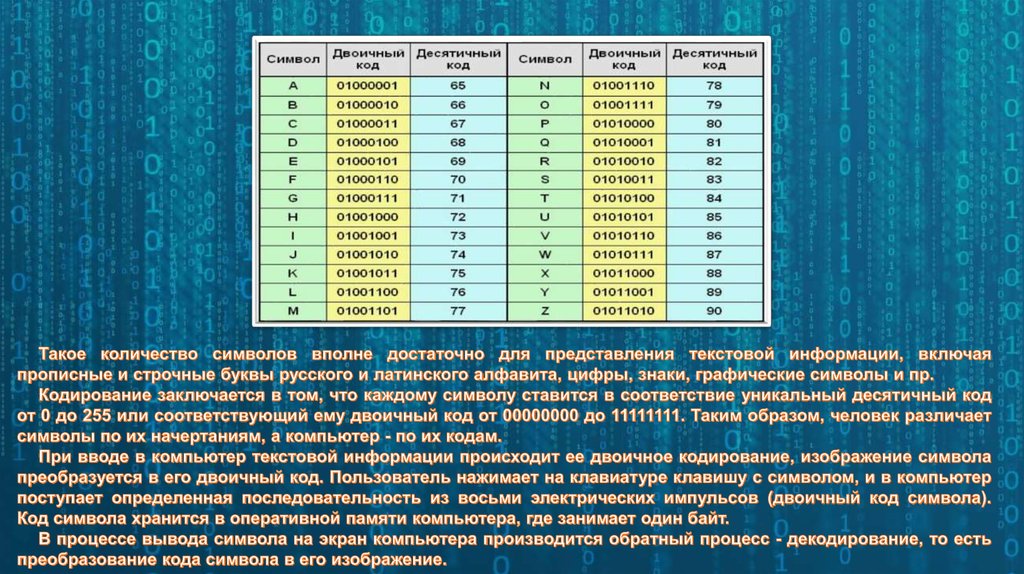
ASCII — Таблица двоичных символов
ASCII — Таблица двоичных символов| Letter | ASCII Code | Binary | Letter | ASCII Code | Binary |
|---|---|---|---|---|---|
| a | 097 | 01100001 | A | 065 | 01000001 |
| b | 098 | 01100010 | Б | 066 | 01000010 |
| в | 099 | 01100011 | C | 067 | 01000011 |
| d | 100 | 01100100 | D | 068 | 01000100 |
| e | 101 | 01100101 | E | 069 | 01000101 |
| f | 102 | 01100110 | F | 070 | 01000110 |
| g | 103 | 01100111 | G | 071 | 01000111 |
| h | 104 | 01101000 | H | 072 | 01001000 |
| i | 105 | 01101001 | I | 073 | 01001001 |
| j | 106 | 01101010 | J | 074 | 01001010 |
| k | 107 | 01101011 | K | 075 | 01001011 |
| l | 108 | 01101100 | L | 076 | 01001100 |
| m | 109 | 01101101 | M | 077 | 01001101 |
| n | 110 | 01101110 | N | 078 | 01001110 |
| o | 111 | 01101111 | O | 079 | 01001111 |
| p | 112 | 01110000 | P | 080 | 01010000 |
| q | 113 | 01110001 | Q | 081 | 01010001 |
| r | 114 | 01110010 | R | 082 | 01010010 |
| S | 115 | 01111119 | S | 9202020202020 29.01010011 | |
| t | 116 | 01110100 | T | 084 | 01010100 |
| u | 117 | 01110101 | U | 085 | 01010101 |
| v | 118 | 01110110 | V | 086 | 01010110 |
| w | 119 | 01110111 | W | 087 | 01010111 |
| x | 120 | 01111000 | X | 088 | 01011000 |
| y | 121 | 01111001 | Y | 089 | 01011001 |
| z | 122 | 01111010 | Z | 090 | 01011010 |
 933339333393339333933393339339339339339339339339339393393393933939339393393933933933933933939339393393933939339393111111111.0021
933339333393339333933393339339339339339339339339339393393393933939339393393933933933933933939339393393933939339393111111111.0021Все буквы алфавита в двоичном коде
На странице Convert Binary вы можете найти буквы латинского алфавита ASCII в их двоичном кодовом представлении.
Вы ищете простой способ преобразования текста в двоичный формат? Для этого у нас есть удобный переводчик. Вы также можете перевести двоичный код в текст на английском или ASCII.
Alphabet in Binary (CAPITAL letters)
| Letter | Binary |
| A | 01000001 |
| B | 01000010 |
| C | 01000011 |
| D | 01000100 |
| E | 01000101 |
| F | 01000110 |
| G | 01000111 |
| H | 01001000 |
| I | 01001001 |
| J | 01001010 |
| K | 01001011 |
| L | 01001100 |
| M | 01001101 |
| N | 01001110 |
| O | 01001111 |
| P | 01010000 |
| Q | 01010001 |
| R | 01010010 |
| S | 01010011 |
| T | 01010100 |
| U | 01010101 |
| V | 01010110 |
| W | 01010111 |
| X | 01011000 |
| Y | 01011001 |
| Z | 01011010 |
Alphabet in Binary (lowercase letters)
| Letter | Binary |
| A | 01100001 |
| B | 01100010 |
| C | 01100011 | 9999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999 0110001118 | .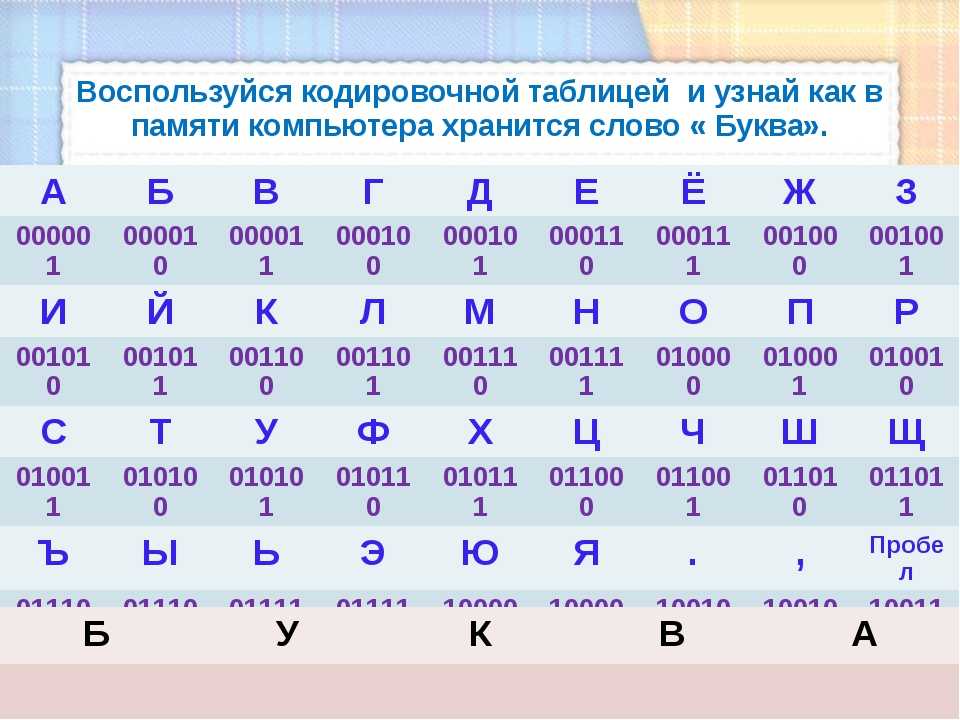 0021 0021 | 01100100 |
| e | 01100101 |
| f | 01100110 |
| g | 01100111 |
| h | 01101000 |
| i | 01101001 |
| j | 01101010 |
| k | 01101011 |
| l | 01101100 |
| m | 01101101 |
| n | 01101110 |
| o | 01101111 |
| p | 01110000 |
| q | 01110001 |
| r | 01110010 |
| s | 01110011 |
| t | 01110100 |
| u | 01110101 |
| v | 01110110 |
| w | 01110111 |
| x | 01111000 |
| Y | 01111001 |
| Z | 01111010 |
Вопросы и ответы об алфавите в двоичном коде
✏️ Как вы переводите двоичный код?
Чтобы преобразовать двоичный код в текст, у вас есть два варианта: вы можете использовать онлайн-переводчик (например, тот, который бесплатно предоставляется ConvertBinary.com, который может перевести любую букву или символ), или вы можете сделать это вручную. .
Если вы хотите научиться преобразовывать двоичный код в текст вручную, вы можете прочитать это руководство или просмотреть соответствующий учебник.
📛 Как записать свое имя в двоичном формате?
Вам нужно преобразовать каждую букву вашего имени в двоичную форму.
Попробуйте конвертер текста в двоичный код на сайте ConvertBinary.com, чтобы мгновенно преобразовать свое имя в двоичный код!
👋 Что такое «привет» в двоичном коде?
Слово «привет» в двоичном коде: 0110100001100101011011000110110001101111 Разделив его на восьмизначные сегменты, легче увидеть двоичный байт, соответствующий каждой букве: 01101000 01100101 011011101 01100389 проверьте это с помощью двоичного транслятора .