
Страдания по IRQ — FAQHard.RU
Начнем с понятия «прерывание».
Прерывание — это событие, которое говорит системе, что что-то произошло, и требует вмешательства.
Такими событиями могут быть: нажатая клавиша на клавиатуре, сигнал от модема, всевозможные ошибки (вроде деления на нуль) и тому подобное.
Как вы наверняка уже слышали, существуют аппаратные и программные прерывания.
Аппаратные (IRQ — Interrupt ReQuest) — те, которые инициируются железом, а программные — софтом, причем механизмы вызова аппаратного или программного прерывания немного различаются, хотя для процессора это в принципе одно и то же.
С программными прерываниями (INT — Interrupt) просто — программа вызывает запрос на прерывание (на языке ассемблера это INT xx, где xx — номер прерывания), после чего процессор сохраняет адрес возврата в программу и флаги состояния процессора, и переходит к обработчику прерывания.
Найти адрес программы-обработчика процессору очень просто (даже думать не приходится) — первый килобайт оперативной памяти содержит адреса этих программ.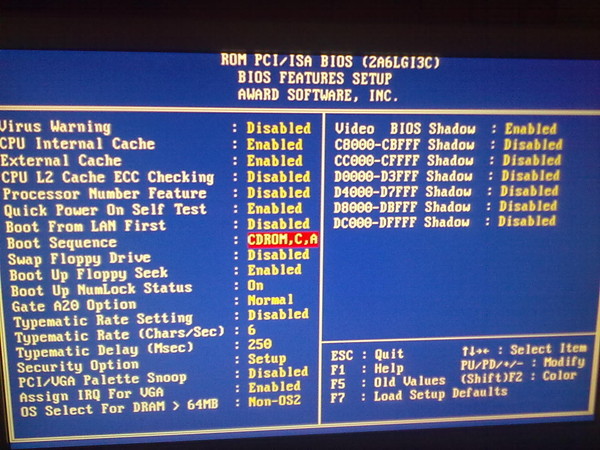
Адрес обработчика нулевого прерывания (прерывания нумеруются с нуля) расположен в самом начале, сразу за ним — адрес обработчика первого прерывания, и так далее до 255-го прерывания.
Выход из обработчика прерывания производится программой-обработчиком, причем управление передается команде, следующей за процедурой вызова прерывания.
Аппаратные прерывания организуются немного сложнее — у каждой шины (PCI, ISA и т. д.) существуют определенные линии (читай — контакты), которые отвечают за прерывания, вызываемые устройствами.
Номера аппаратных прерываний не прямо соответствуют адресам программных, то есть аппаратному IRQ 0 соответствует INT 8, и так далее по таблице.
Зачем, спрашивается, нужны эти IRQ?
Во-первых — постоянно опрашивать все устройства на предмет «а не желаете ли Вы нам что-нибудь этакое передать?» просто непозволительно с точки зрения производительности.
Процессор просто утомится это делать — гораздо легче дать устройству какие-то права, и пусть оно командует.
Во-вторых, сам механизм позволяет программам и процессору абсолютно наплевательски относиться ко всем выступлениям со стороны устройств.
То есть программа даже не замечает, что, пока она работала, произошло 843 IRQ от жестких дисков, клавиатуры, таймера и прочего неотъемлемого барахла из мира внутренностей компьютера.
К тому же, очень важен тот факт, что устройство теоретически может быть обслужено именно в тот момент, когда оно готово что-то сделать или что-то сообщить системе.
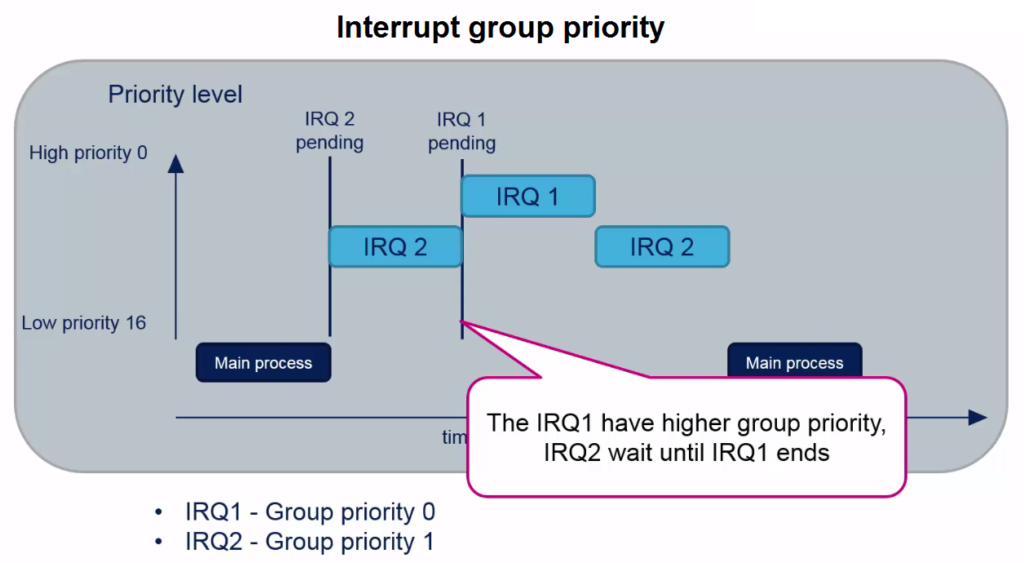
Представьте себе, что на двух разных прерываниях «висят» два устройства — радар слежения за ракетами дальнего действия и чайник.
И вдруг они одновременно вызывают свои прерывания.
Что важнее для вас — чайник или сноп ракет, который может через минуту опуститься вам на голову?
То-то же!
Для разрешения таких ситуаций и существует система приоритетов, исходя из которых процессор выбирает, какое прерывание ему обслужить в первую очередь.
1 2 3 4… 7
Что такое IRQ? | KV.
 by
by| — Да вы, молодёжь, небось, IRQ
от IDDQD не отличаете! — Обижаете! Мы еще и IDKFA помним. (по мотивам bash.org.ru) |
Мы с вами на страницах «Компьютерных вестей» продолжаем знакомиться со значением различных аббревиатур, напрямую или косвенно относящихся к компьютерам и информационным технологиям.
IRQ расшифровывается как «interrupt
request», что по-русски звучит как
«запрос на прерывание». Так
принято называть специальный
сигнал, который сообщает
процессору о необходимости
прервать выполнение текущей
программы, сохранить её состояние в
стеке, и перейти к заранее
заданному адресу памяти. Сам этот
процесс называется прерыванием, и
нередко саму аббревиатуру IRQ для
краткости расшифровывают просто
как «прерывание». Поддержка
прерывания обеспечивается
специальным контроллером
прерываний, давно уже ставшим
частью чипсета. В настоящее время,
конечно, информация о том, что такое
прерывания, имеет даже для
ИТ-специалистов больше
познавательный, нежели
практический характер, однако
некоторое время назад всё было
совершенно иначе.
Нужно отметить, что выделяют два принципиально различных типа прерываний: аппаратные и программные. Аппаратные прерывания вызываются, как несложно догадаться по их названию, различными устройствами и связаны с событиями, которые произошли с этими самыми устройствами. Это, например, прерывания, вызванные нажатиями клавиш на клавиатуре, — такие прерывания называются внешними. Внутренние прерывания вызваны действиями самого центрального процессора (скажем, делением на ноль). Программные прерывания, напротив, связаны не с какими-то событиями в аппаратной части компьютера, а вызываются явно специальными инструкциями в программном обеспечении.
Каждое прерывание имеет собственный специфический номер, который определяет адрес перехода. После того, как вызванная прерыванием процедура отработает, процессор восстанавливает работавшую до вызова прерывания программу из стека, после чего её выполнение продолжается так, будто никакого прерывания и в помине не было.
Прерывания, ко всему прочему,
делятся ещё на маскируемые и
немаскируемые.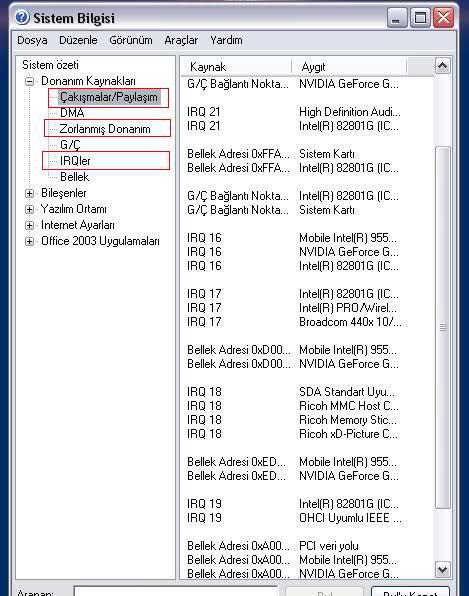 Что это значит?
Маскируемые прерывания — это такие,
которые можно запретить (с помощью
установки специально определённых
для этого случая битов в маске
прерывания — отсюда и их название),
немаскируемые же обрабатываются в
любом случае.
Что это значит?
Маскируемые прерывания — это такие,
которые можно запретить (с помощью
установки специально определённых
для этого случая битов в маске
прерывания — отсюда и их название),
немаскируемые же обрабатываются в
любом случае.
Вадим СТАНКЕВИЧ
Max irq per second что это – Тарифы на сотовую связь
116 пользователя считают данную страницу полезной.
Информация актуальна! Страница была обновлена 16.12.2019
После обновления Windows 10 до версии 1151 у меня внезапно сломался интернет. Причём сломался он весьма противно: он как бы работал, но при этом выгрузка больших объёмов данных страдала. Страдала она не везде, а только на сайтах с HTTPS и Telegram. Симптоматика проста: при выгрузке файла она не начинается вообще, зависая на нуле процентов, либо доходит до определённого состояния и умирает, либо не может завершиться на ста процентах.
Использую Windows 10 версии 1151 и сетевую карту Atheros AR8152. Указываю модель карты, потому что с другим железом (Wi-Fi адаптер, USB-сетевая карта) соединение работает нормально. Откат драйверов, попытка установить их от других систем, подстановка INF и установка из репозиториев «десятки» успехом не завершились.
Задав вопрос на Super User и не получив на него ответа, я решил покопаться в настройках сетевого адаптера и таки добился истины: теперь соединение работает как часы. Спешу рассказать и вам.
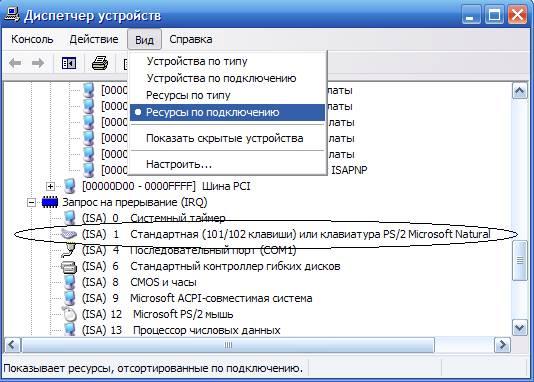
Итак, для начала открываем «Диспетчер устройств». Самый простой способ — нажать Win+R, там ввести devmgmt.msc и нажать Enter. Далее добираемся до нашего адаптера: раскрываем «Сетевые адаптеры» и ищем строчку, содержащую «AR8152»:
Нажимаем на адаптер два раза.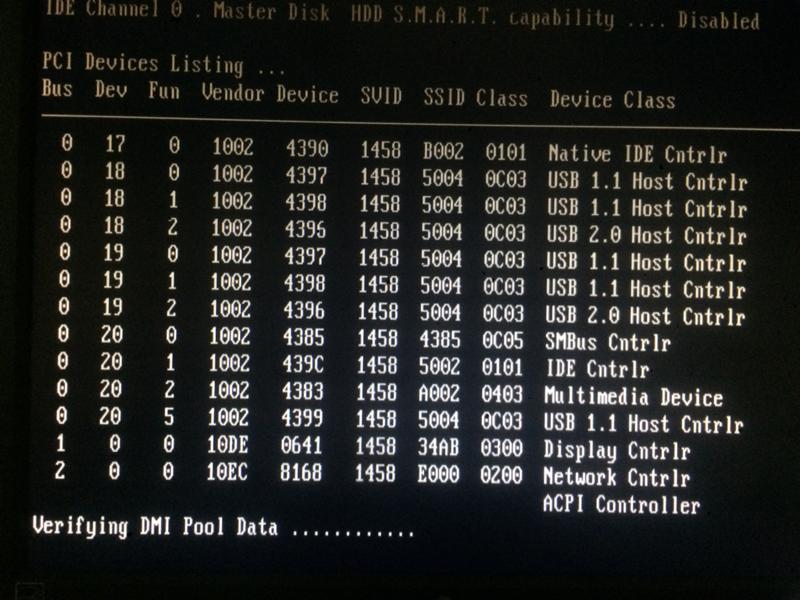 Для начала нужно откатить драйверы до тех, что были в комплекте с Windows 10. Для этого идём на вкладку «Драйвер» и нажимаем там «Откатить»:
Для начала нужно откатить драйверы до тех, что были в комплекте с Windows 10. Для этого идём на вкладку «Драйвер» и нажимаем там «Откатить»:
Далее перезагружаемся. Обратите внимание: драйвер должен быть версии 2.1.0.16 от 2013 года, это тот, что идёт в комплекте, и только он будет работать с «десяткой».
Теперь настраиваем сетевую карту. Открываем вкладку «Дополнительно». В окошке слева будет список параметров. Выделяя параметры, прописываем в правом поле следующее:
- Large Send Offload (IPv4) = Disabled
- Large Send Offload v2 (IPv4) = Disabled
- Max IRQ per second = 9000
- Transmit Buffers = 1024
Перезагружаемся. Готово! Вы восхитительны и теперь можете отправить своей девушке видео того самого котёнка размером в 12 мегабайт и не только ;3
Думаю, многие любознательные пользователи, наверняка не раз встречали такое сокращение, как IRQ. Его можно встретить, например, если вы любите заглядывать в программу «Менеджер устройств» в Windows. Если вы выберете любое устройство, к примеру, клавиатуру, выберете при помощи правой кнопки мыши пункт меню «Свойства», и в появившемся окне сделаете активной закладку «Ресурсы», то в списке ресурсов вы увидите надпись IRQ 01.
Его можно встретить, например, если вы любите заглядывать в программу «Менеджер устройств» в Windows. Если вы выберете любое устройство, к примеру, клавиатуру, выберете при помощи правой кнопки мыши пункт меню «Свойства», и в появившемся окне сделаете активной закладку «Ресурсы», то в списке ресурсов вы увидите надпись IRQ 01.
Для чего нужны IRQ
Что же такое IRQ и для чего оно нужно?
Аббревиатура IRQ расшифровывается как Interrupt ReQuest (запрос на прерывание). Для того, чтобы понять, для чего оно нужно, следует вспомнить подробности организации работы персонального компьютера.
Кровеносной системой компьютера, по которой обмениваются информацией процессор и прочие устройства, является системная шина. Но как вообще процессор способен отличить запросы на обработку информации, поступающие по шине от различных устройств?
Для этого и существует система аппаратных прерываний (IRQ). Каждое прерывание имеет определенный номер (нумерация начинается с 0) и закреплено за определенным устройством. Так, за клавиатурой закреплено прерывание под номером 1, отсюда и обозначение IRQ 01.
Так, за клавиатурой закреплено прерывание под номером 1, отсюда и обозначение IRQ 01.
При поступлении запроса от устройства компьютер прерывает (отсюда и появился сам термин «прерывание») обработку текущей информации и начинает обработку вновь поступившего. Если прерываний несколько, то они обрабатывается в порядке приоритетов, закрепленных за каждым из них. Как правило, чем меньше номер прерывания, тем больший приоритет для процессора имеет устройство, закрепленное за этим прерыванием, но это правило соблюдается далеко не всегда.
Обслуживает обработку IRQ специальный чип, который носит название контроллера прерываний. Как правило, эта микросхема является частью центрального процессора, а иногда выделяется в отдельный чип на материнской плате. Для обработки каждого прерывания в BIOS существует специальная микропрограмма, называемая обработчиком прерывания. Адреса всех обработчиков хранятся в так называемой таблице векторов прерываний.
Раньше, в первых компьютерах семейства XT была распространена 8-разрядная шина ISA, поэтому всего устройствам было доступно 8 прерываний. С появлением 16-разрядной шины ISA их количество увеличилось до 16.
С появлением 16-разрядной шины ISA их количество увеличилось до 16.
Настройка Interrupt ReQuest
Надо сказать, что прерывания, закрепленные за некоторыми устройствами, не является фиксированными и их можно изменить программно. Например, IRQ стандартно использующееся последовательным портом Com 2, может использовать и устанавливаемый в слот расширения модем. В современных компьютерах и операционных системах, поддерживающих стандарт PnP и работающих под управлением ОС Windows, значения IRQ для устройств, подключаемых в слоты шины, подбираются автоматически.
Но не все было так просто в прежние времена, когда пользователь должен был вручную устанавливать значение IRQ во многих программах, работавших под операционной системой DOS. Например, при установке в систему звуковой карты, пользователю требовалось выбрать свободное прерывание из очень небольшого числа доступных (как правило, это было IRQ 5) и указать это значение в запускаемой программе, например, в какой-нибудь игре.
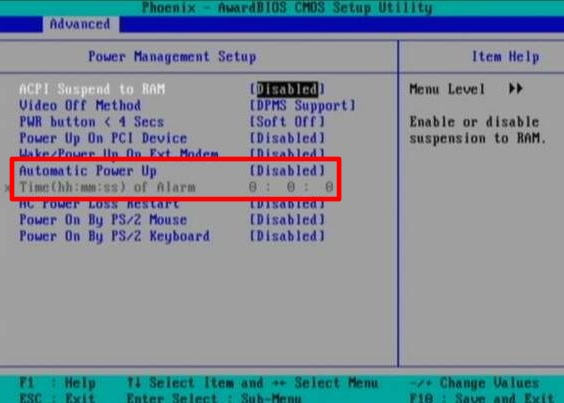
Во многих BIOS имеется возможность поменять стандартные значения IRQ в программе Setup. Обычно эта опция располагается в разделах IRQ Resources или PCI/PNP Configuration.
Установка для устройства значения IRQ, равного значению IRQ, уже занятого каким-либо устройством в большинстве случаев приводит к неработоспособности одного из этих устройств или сразу обоих, а иногда чревато и зависанием компьютера.
В более современной шине PCI система управления прерываниями была кардинально изменена, а возможности управления прерываниями были расширены. Благодаря технологии IRQ Sharing, а также технологии ACPI стало возможным размещение нескольких устройств на одном канале прерывания, а у внешних устройств, подключаемых в слоты PCI, появилась возможность автоматического распределения ресурсов между собой.
Кроме того, в современных компьютерах обычно используется расширенный программируемый контроллер прерываний (APIC, Advanced Programmable Interrupt Controller), поддерживающий 24 канала Interrupt ReQuest.
Не следует путать аппаратные прерывания IRQ c программными прерываниями BIOS, о которых речь пойдет в отдельной статье. Программные прерывания BIOS, как правило, используются для организации работы программного обеспечения с устройствами ввода-вывода и обозначаются при помощи сокращения INT. Многие из них аналогичны по своим функциям аппаратным IRQ, но имеют при этом другие номера.
Список номеров Interrupt ReQuest в стандартной схеме для 16-битной шины ISA:
- Системный таймер
- Клавиатура
- Дополнительный контроллер прерываний (для совместимости с 8-битной шиной)
- Порты Com 1 и 3
- Порты Com 2 и 4
- Свободно (в 8-битной шине — контроллер жесткого диска)
- Контроллер гибких дисков (FDD)
- Параллельный порт LPT
- Часы реального времени CMOS
- Совмещено с IRQ 2
- Свободно
- Свободно
- Порт мыши PS/2
- Сопроцессор (в настоящее время практически не используется)
- Первый контроллер IDE
- Второй контроллер IDE
Список дополнительных номеров IRQ, которые использует расширенный контроллер прерываний APIC:
- Контроллер USB
- Интегрированная звуковая подсистема (AC’97 или HDA)
- Контроллер USB
- Контроллер USB
- Встроенная сетевая карта
- Свободно
- Свободно
- Контроллер USB 2.
 0
0
 0
0Соответствие номеров IRQ и прерываний BIOS:
Заключение
Итак, в этой статье вы смогли узнать, что означает сокращение IRQ, и что представляют собой аппаратные прерывания. Они являются встроенным механизмом распределения ресурсов компьютера и предназначены для организации доступа устройств к центральному процессору. Правильное распределение и настройка IRQ позволяет избежать конфликтов между устройствами и обеспечить стабильную работу системы.
Михаил Тычков aka Hard
Доброго времени суток.
Давайте рассмотрим такую вот ситуевину: процессор обрабатывает какие-то данные, не важно какие. В этот момент у какого-нить устройства тоже появились данные для обработки. Че делать? Надо просить процессор, что бы тот соизволил обратить на просьбу внимание и решил бы, сейчас обрабатывать эти данные или потом. Так вот эта просьба и есть IRQ или прерывания (вообще-то существуют два типа прерываний: аппаратные (внешние) и программные (внутренние), но поскольку мой раздел называется «Железо и сети», то разговор я буду вести только об аппаратных прерываниях). Строго говоря IRQ – это каналы запросов прерывания, которые используются всевозможными девайсами для того, что бы сообщить процессору о том, что необходимо обработать определенный запрос. Физически, IRQ представляют собой отдельно проложенные линии (проводники) и соответствующие этим линиям контакты в интерфейсах. Все это находится, ессесно на материнской плате. Линии IRQ предназначены только для передачи запросов прерывания.
Строго говоря IRQ – это каналы запросов прерывания, которые используются всевозможными девайсами для того, что бы сообщить процессору о том, что необходимо обработать определенный запрос. Физически, IRQ представляют собой отдельно проложенные линии (проводники) и соответствующие этим линиям контакты в интерфейсах. Все это находится, ессесно на материнской плате. Линии IRQ предназначены только для передачи запросов прерывания.
А ну-ка разберемся, как вся эта фигня с IRQ происходит. Итак, после получения запроса прерывания, камень сохраняет в стеке содержимое регистров. Затем он обращается к таблице векторов прерываний, где есть список адресов памяти программ, соответствующих определенным номерам прерываний. От номера прерывания зависит, какая программа будет запущена. В основном этими программами являются драйвера, относящиеся к устройствам, пославшим запрос (а уж драйвера туго знают свое дело и разберутся, что дальше делать). После всего этого, процедура обработки возвращает из стека то, с чем работал камень, а проще говоря, отдается управление системой той программе, что работала до запроса прерывания.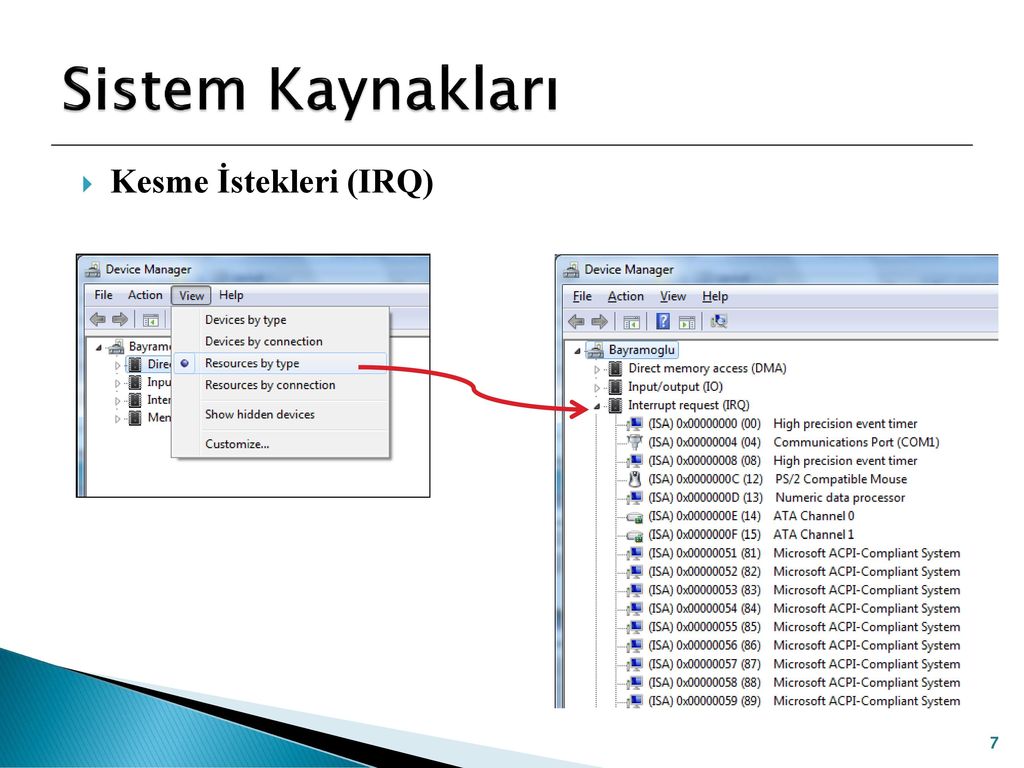 И так постоянно. Сама таблица находится в оперативной памяти и состоит из 256 элементов по 4 байта и начинается с адреса 0000:0000. Занимает она 1024 Кбайт. Надеюсь, что Вы усвоили простую истину: если необходимо обработать хотя бы один новый байт от какого-либо устройства, необходимо сначала обработать IRQ этого устройства.
И так постоянно. Сама таблица находится в оперативной памяти и состоит из 256 элементов по 4 байта и начинается с адреса 0000:0000. Занимает она 1024 Кбайт. Надеюсь, что Вы усвоили простую истину: если необходимо обработать хотя бы один новый байт от какого-либо устройства, необходимо сначала обработать IRQ этого устройства.
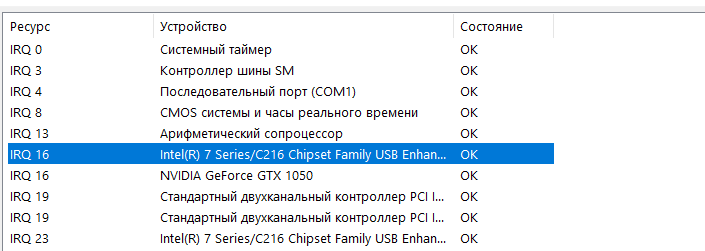
Что бы не было путаницы у IRQ есть иерархия или говоря другим языком – приоритеты. Чем меньше номер прерывания, тем выше приоритет и наоборот, чем больше номер прерывания, тем ниже приоритет. IRQ всего 16. Самый высокий приоритет у IRQ 0, а самый низкий у IRQ 15. Приведу таблицу иерархии:
Программируемый контроллер прерываний
Последовательный порт COM 2
Последовательный порт COM 1
Звуковая или сетевая карты или свободен
Стандартный контроллер гибких дисков
Параллельный порт LPT
Звуковая или сетевая карты или свободен
USB или SCSI или свободен
PS/2 совместимый порт мыши
Основной контроллер IDE
Дополнительный контроллер IDE
А хотите посмотреть свои прерывания? Выберите «Пуск – Выполнить», наберите «msinfo32».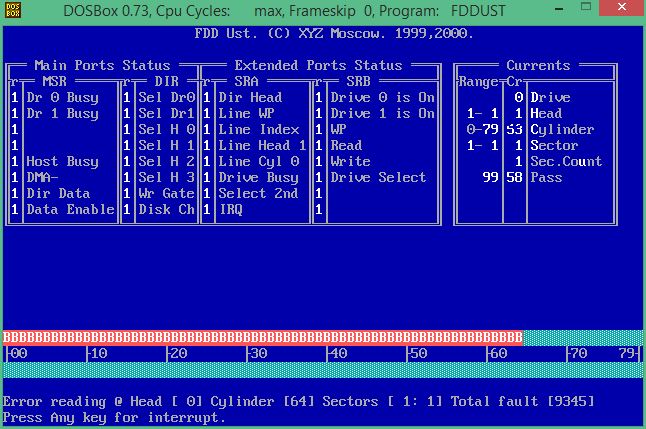 В появившимся окне «Сведения о системе», слева, выберите вкладку «Ресурсы аппаратуры – Прерывания IRQ».
В появившимся окне «Сведения о системе», слева, выберите вкладку «Ресурсы аппаратуры – Прерывания IRQ».
С прерываниями случаются и геморрои. Если произойдет генерация большого количества IRQ, то стек может переполниться и тогда…. тогда Вы потянитесь к кнопочке [Reset]. Ежели такая фигня будет происходить часто, то необходимо в файле Config.sys увеличить параметр Stacks. Кроме, этого двум различным устройствам PCI может быть назначено одно и то же прерывание. Теоретически такое не должно происходить, но вот на практике случается. В этом случае Вам придется самому назначить прерывание одному из заглючивших устройств. Как это сделать? Жмем [Win][Pause/Break]. Выскакивает окно «Свойства: Система». Выбираем вкладку «Устройства», ищем в списке то устройство, IRQ которого будем подправлять и жмем на него пару раз мышью. Выскочит окно его свойств, где выберем вкладку «Ресурсы» и снимем галку «Автоматическая настройка». Затем чуть ниже выбираем «Запрос на прерывания» и кликаем опять два раза мышью.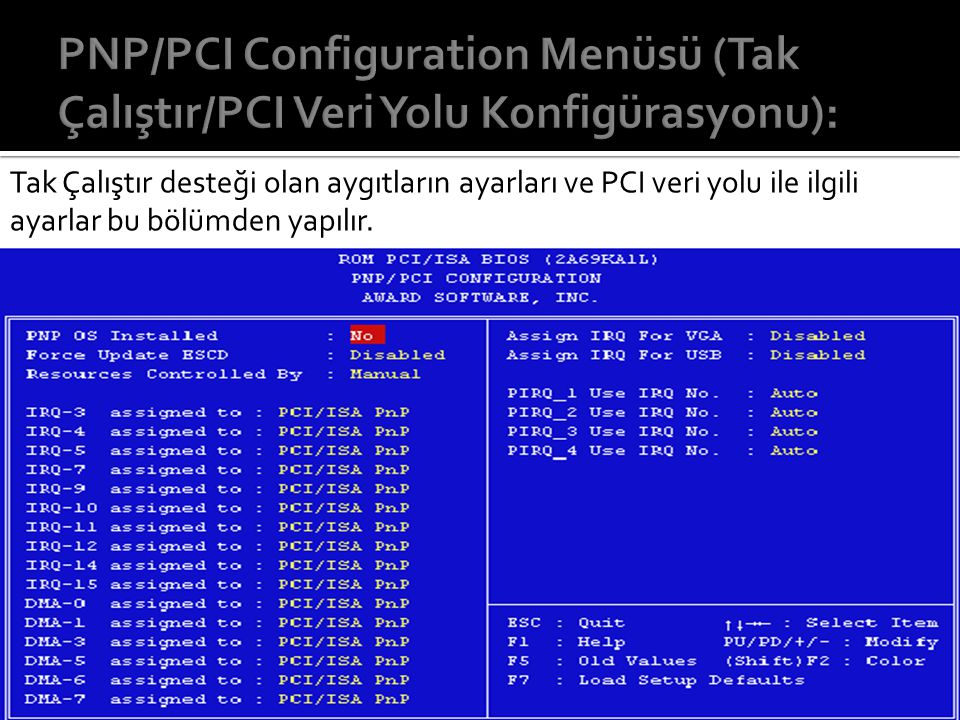 Появится окно, где можно изменить номер IRQ. Ни фиг себе и сложно. Но… Назначать прерывания надо с умом. Сверьтесь с таблицей: какие IRQ для чего предназначены. Посмотрите у себя, какие свободны. Может так случится, что свободных прерываний у Вас и не будет. Думаете – все, жопа? Нет! Новых IRQ Вы конечно не добавите, но подумайте, все ли устройства Вам необходимы. Например, как часто Вы используете порты COM. Я ими последние года три не пользуюсь вообще. Ну и на фиг их из системы. Это можно сделать из BIOS. И вот Вам свободные IRQ. Короче, в решении подобной проблемы надо приложить голову и все у Вас получится. А всяких там кулых спецов хочу предупредить сразу – не пишите мне письма типа: «После твоей статьи клиенты пачками стали нести к нам в магазин компы с развороченными настройками!». Я не отвечаю за действия людей, у которых голова и руки растут из того же места, что и ноги. Когда-то я и сам в этом ни черта не смыслил, но ведь разобрался же. Причем мне никто ничего не объяснял. Дорогу осилит идущий!
Появится окно, где можно изменить номер IRQ. Ни фиг себе и сложно. Но… Назначать прерывания надо с умом. Сверьтесь с таблицей: какие IRQ для чего предназначены. Посмотрите у себя, какие свободны. Может так случится, что свободных прерываний у Вас и не будет. Думаете – все, жопа? Нет! Новых IRQ Вы конечно не добавите, но подумайте, все ли устройства Вам необходимы. Например, как часто Вы используете порты COM. Я ими последние года три не пользуюсь вообще. Ну и на фиг их из системы. Это можно сделать из BIOS. И вот Вам свободные IRQ. Короче, в решении подобной проблемы надо приложить голову и все у Вас получится. А всяких там кулых спецов хочу предупредить сразу – не пишите мне письма типа: «После твоей статьи клиенты пачками стали нести к нам в магазин компы с развороченными настройками!». Я не отвечаю за действия людей, у которых голова и руки растут из того же места, что и ноги. Когда-то я и сам в этом ни черта не смыслил, но ведь разобрался же. Причем мне никто ничего не объяснял. Дорогу осилит идущий!
Двигаемся дальше. Вообще, следует отметить, что каналы запросов прерывания относятся к системным ресурсам. Дам короткое но очень меткое определение: системными ресурсами называются коммуникационные каналы, адреса и сигналы, используемые узлами компьютера для обмена данными с помощью шин. Вот так вот просто и понятно. К системным ресурсам кроме IRQ относятся: адреса памяти, каналы прямого доступа к памяти и адреса портов ввода/вывода. Но об этом в других статьях. А на сегодня все. Удачи в Ваших начинаниях.
Вообще, следует отметить, что каналы запросов прерывания относятся к системным ресурсам. Дам короткое но очень меткое определение: системными ресурсами называются коммуникационные каналы, адреса и сигналы, используемые узлами компьютера для обмена данными с помощью шин. Вот так вот просто и понятно. К системным ресурсам кроме IRQ относятся: адреса памяти, каналы прямого доступа к памяти и адреса портов ввода/вывода. Но об этом в других статьях. А на сегодня все. Удачи в Ваших начинаниях.
Системные прерывания грузят процессор | remontka.pro
  windows
Если вы столкнулись с тем, что системные прерывания грузят процессор в диспетчере задач Windows 10, 8.1 или Windows 7, в этой инструкции подробно о том, как выявить причину этого и исправить проблему. Полностью убрать системные прерывания из диспетчера задач нельзя, но вернуть нагрузку в норму (десятые доли процента) вполне возможно, если выяснить, что вызывает нагрузку.
Системные прерывания не являются процессом Windows, хотя и отображаются в категории «Процессы Windows». Это, в общих чертах, — событие, вызывающее прекращение выполнения текущих «задач» процессором для выполнения «более важной» операции. Существуют различные типы прерываний, но чаще всего высокую нагрузку вызывают аппаратные прерывания IRQ (от оборудования компьютера) или исключения, обычно вызываемые ошибками работы оборудования.
Что делать, если системные прерывания грузят процессор
Чаще всего, когда в диспетчере задач появляется неестественно высокая нагрузка на процессор, причиной является что-то из:
- Неправильно работающее оборудование компьютера
- Неправильная работа драйверов устройств
Почти всегда причины сводятся именно к этим пунктам, хотя взаимосвязь проблемы с устройствами компьютера или драйверами не всегда очевидна.
Прежде чем приступать к поиску конкретной причины, рекомендую, если это возможно, вспомнить, что выполнялось в Windows непосредственно перед появлением проблемы:
- Например, если обновлялись драйверы, можно попробовать откатить их.
- Если было установлено какое-то новое оборудование — убедиться в правильности подключения и работоспособности устройства.
- Также, если ещё вчера проблемы не было, а с аппаратными изменениями связать проблему не получается, можно попробовать использовать точки восстановления Windows.

Поиск драйверов, вызывающих нагрузку от «Системные прерывания»
Как уже было отмечено, чаще всего дело в драйверах или устройствах. Можно попробовать обнаружить, какое из устройств вызывает проблему. Например, в этом может помочь бесплатная для бесплатного использования программа LatencyMon.
- Скачайте и установите LatencyMon с официального сайта разработчика http://www.resplendence.com/downloads и запустите программу.
- В меню программы нажмите кнопку «Play», перейдите на вкладку «Drivers» и отсортируйте список по колонке «DPC count».
- Обратите внимание на то, какой драйвер имеет наибольшие значения DPC Count, если это драйвер какого-то внутреннего или внешнего устройства, с большой вероятностью, причина именно в работе этого драйвера или самого устройства (на скриншоте — вид на «здоровой» системе, т. е. более высокие количества DPC для приведенных на скриншоте модулей — норма).
- В диспетчере устройств попробуйте отключить устройства, драйверы которых вызывают наибольшую нагрузку согласно LatencyMon, а затем проверить, была ли решена проблема. Важно: не отключайте системные устройства, а также находящиеся в разделах «Процессоры» и «Компьютер». Также не стоит отключать видеоадаптер и устройства ввода.
- Если отключение устройства вернуло нагрузку, вызываемую системными прерываниями в норму, удостоверьтесь в работоспособности устройства, попробуйте обновить или откатить драйвер, в идеале — с официального сайта производителя оборудования.
 е. более высокие количества DPC для приведенных на скриншоте модулей — норма).
е. более высокие количества DPC для приведенных на скриншоте модулей — норма).Обычно причина кроется в драйверах сетевых и Wi-Fi адаптеров, звуковых карт, других карт обработки видео или аудио-сигнала.
Проблемы с работой USB устройств и контроллеров
Также частой причиной высокой нагрузки на процессор со стороны системных прерываний является неправильная работа или неисправность внешних устройств, подключенных по USB, самих разъемов или повреждение кабелей. В этом случае в LatencyMon вы навряд ли увидите что-то необычное.
В этом случае в LatencyMon вы навряд ли увидите что-то необычное.
При подозрениях на то, что причина в этом, можно было бы рекомендовать поочередно отключать все USB-контроллеры в диспетчере устройств, пока в диспетчере задач не упадет нагрузка, но, если вы начинающий пользователь, есть вероятность, что вы столкнетесь с тем, что у вас перестанут работать клавиатура и мышь, а что делать дальше будет не ясно.
Поэтому могу рекомендовать более простой метод: откройте диспетчер задач, так чтобы было видно «Системные прерывания» и поочередно отключайте все без исключения USB устройства (включая клавиатуру, мышь, принтеры): если вы увидите, что при отключении очередного устройства нагрузка упала, то ищите проблему в этом устройстве, его подключении или том USB-разъеме, который для него использовался.
Другие причины высокой нагрузки от системных прерываний в Windows 10, 8.1 и Windows 7
В завершение некоторые менее часто встречающиеся причины, вызывающие описываемую проблему:
- Включенный быстрый запуск Windows 10 или 8. 1 в сочетании с отсутствием оригинальных драйверов управления электропитанием и чипсета. Попробуйте отключить быстрый запуск.
- Неисправный или не оригинальный адаптер питания ноутбука — если при его отключении системные прерывания перестают грузить процессор, дело скорее всего в этом. Однако, иногда, виноват не адаптер, а батарея.
- Звуковые эффекты. Попробуйте отключить их: правый клик по значку динамика в области уведомлений — звуки — вкладка «Воспроизведение» (или «Устройств воспроизведения»). Выбираем используемое по умолчанию устройства и нажимаем «Свойства». Если в свойствах присутствуют вкладки «Эффекты», «Пространственный звук» и похожие, отключаем их.
- Неправильная работа оперативной памяти — выполните проверку оперативной памяти на ошибки.
- Проблемы с работой жесткого диска (основной признак — компьютер то и дело зависает при доступе к папкам и файлам, диск издает необычные звуки) — выполните проверку жесткого диска на ошибки.
- Редко — наличие нескольких антивирусов на компьютере или специфических вирусов, работающих напрямую с оборудованием.
 1 в сочетании с отсутствием оригинальных драйверов управления электропитанием и чипсета. Попробуйте отключить быстрый запуск.
1 в сочетании с отсутствием оригинальных драйверов управления электропитанием и чипсета. Попробуйте отключить быстрый запуск.
Есть еще один способ попробовать выяснить, какое оборудование виновато (но что-то показывает редко):
- Нажмите клавиши Win+R на клавиатуре и введите perfmon /report затем нажмите Enter.
- Подождите, пока будет подготовлен отчет.
В отчете в разделе Производительность — Обзор ресурсов вы можете увидеть отдельные компоненты, цвет которых будет красным. Присмотритесь к ним, возможно, стоит выполнить проверку работоспособности этого компонента.
А вдруг и это будет интересно:
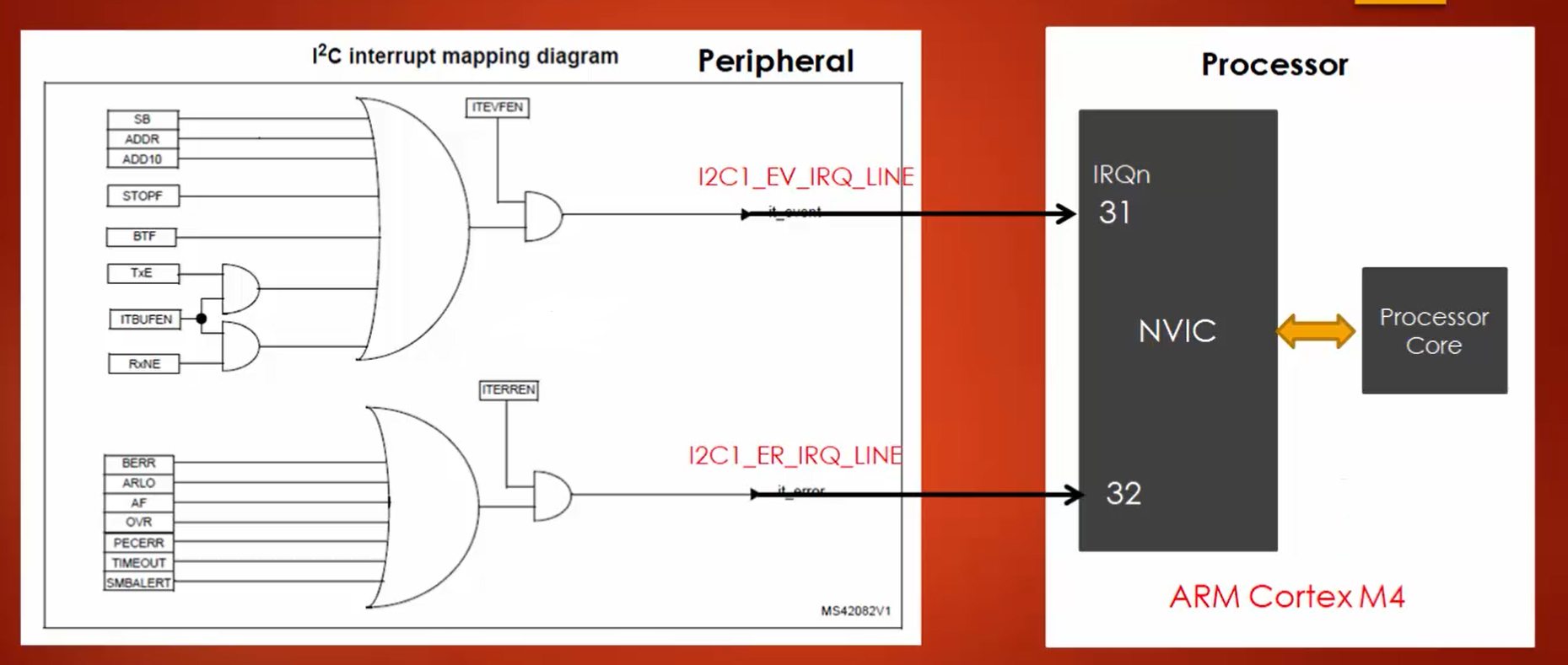
4.3. Обработка запросов прерываний Red Hat Enterprise Linux 6
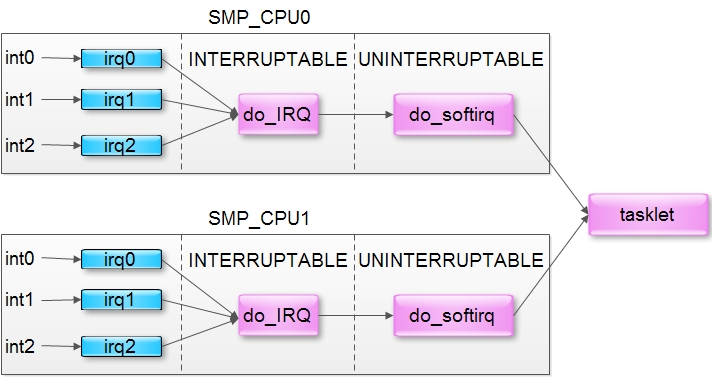
Прерывание — запрос обслуживания на аппаратном уровне. Прерывания могут генерироваться локальным оборудованием или поступать по шине в виде пакета данных (MSI, Message Signaled Interrupt).
Код обработки прерываний ядра получает номер запроса и список зарегистрированных обработчиков прерываний, и по очереди их вызывает. Обработчик получает прерывание, маскирует аналогичные запросы, запрашивает обработку прерывания низкоприоритетным обработчиком и после завершения перестает маскировать запросы.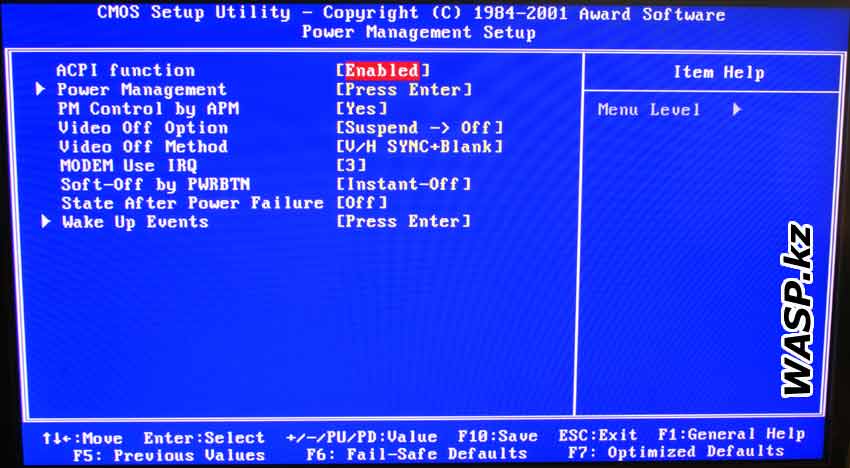
/proc/interrupts содержит статистику прерываний: номер прерывания, число прерываний этого типа, полученных каждым процессорным ядром, тип прерывания и список драйверов, обрабатывающих это прерывание. Подробную информацию можно найти на справочной странице man 5 proc.
Прерываниям соответствует параметр smp_affinity, определяющий ядра, которые будут принимать участие в обслуживании. Его значение можно корректировать с целью улучшения производительности, привязывая прерывания и потоки к одним и тем же ядрам.
Значение smp_affinity определяется в /proc/irq/номер_прерывания/smp_affinity в шестнадцатеричном формате. Для его просмотра и изменения необходимы права root.
В качестве примера рассмотрим прерывание драйвера Ethernet на сервере с четырьмя процессорными ядрами. Для начала надо узнать его номер прерывания:
# grep eth0 /proc/interrupts 32: 0 140 45 850264 PCI-MSI-edge eth0
Теперь можно просмотреть содержимое файла smp_affinity:
# cat /proc/irq/32/smp_affinity f
f означает, что прерывание может обслуживаться на любом процессоре.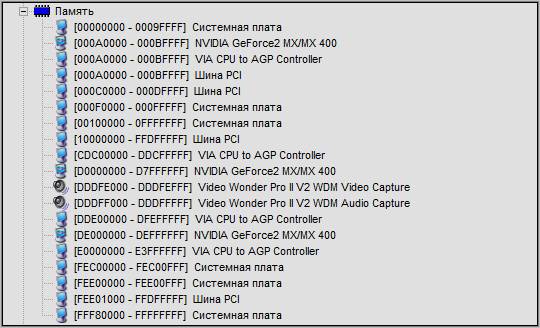 Ниже этому параметру будет присвоено значение
Ниже этому параметру будет присвоено значение 1, то есть прерывание будет обслуживаться на процессоре 0.
# echo 1 >/proc/irq/32/smp_affinity # cat /proc/irq/32/smp_affinity 1
Можно указать несколько значений, разделив их запятыми. Обычно используется в системах, где число ядер превышает 32. Так, например, ниже обслуживание прерывания 40 разрешается на всех ядрах в 64-ядерной системе:
# cat /proc/irq/40/smp_affinity ffffffff,ffffffff
Пример значения smp_affinity, ограничивающий обслуживание прерывания 40 последними 32 ядрами в 64-ядерной системе:
# echo 0xffffffff,00000000 > /proc/irq/40/smp_affinity # cat /proc/irq/40/smp_affinity ffffffff,00000000
В системах, поддерживающих управление линией запросов прерывания, управление может быть передано оборудованию.
irq – список вопросов по тегу – страница №3
У меня есть сервер ubuntu 18. 04.1 с 8-ядерным процессором и 8 гигабайтами памяти. это облачный сервер, основанный на виртуализации KVM. Я использую haproxy 1.8.8 для…
04.1 с 8-ядерным процессором и 8 гигабайтами памяти. это облачный сервер, основанный на виртуализации KVM. Я использую haproxy 1.8.8 для…
У меня 12 стержневых ящиков: egrep -c processor /proc/cpuinfo…
У меня проблема с балансировкой irq. Я взял номера irq из / etc / interrupts и назначил каждый irq каждому из 24 процессоров как этот учебник говорит for i in {143..166};do cat…
Один из наших производственных кластеров, управляемый XCP, внезапно перестал отвечать. После перезагрузки и некоторого исследования мы обнаружили такие логи в системном журнале…
Я установил последнюю версию драйвера yukon от Marvell для Solaris 10 8/11. Получил драйвер, установил, обновил /etc/driver_aliases и работал нормально. После того, как система…
Среда У меня есть небольшой двухъядерный сервер на базе Intel Atom, работающий под управлением CentOS 5. 5 x64 со слегка настроенным ядром Xen. Он также имеет одну встроенную…
5 x64 со слегка настроенным ядром Xen. Он также имеет одну встроенную…
Centos 6.9 (64 ГБ ОЗУ) Запуск nginx, mariadb, php-fpm, iptables, java На сервере случаются случайные, но частые всплески 100% загрузки процессора только на 1 ядро, что…
Я просматривал сгенерированные munin диаграммы на сервере Ubuntu 12.10. Я заметил, что примерно две недели назад (этот сервер в тот момент отключился) он начал генерировать…
В моем Linux-сервере ввод-вывод не используется для нескольких процессоров. как показано ниже ata_piix злоумышленники участвуют только в cpu0 [root@manage ~]# uname -a…
Я управляю FLOW3 Быстрый запуск на машине Fedora (виртуализированной в Windows, если это помогает). Каждый запрос занимает около 1,2 секунды, чтобы запустить самый простой.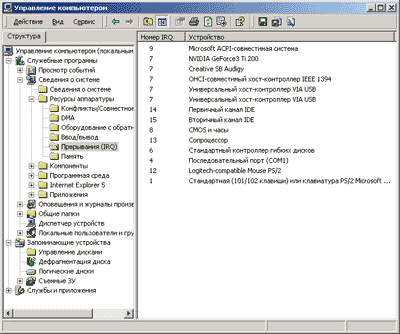 ..
..
Прерывания в защищённом режиме. Глава 8. Обработчики аппаратных прерываний.
Smart ASM: Прерывания в защищённом режиме. Глава 8. Обработчики аппаратных прерываний.Прерывания в защищённом режиме:
Глава 8. Обработчики аппаратных прерываний.
Обработка аппаратных прерываний значительно отличается в различных ОС, поэтому имеет смысл давать лишь общие рекомендации. Более серьёзно к этому вопросу мы подойдём после того, как изучим мультизадачность и виртуальную память, а пока при реализации обработчиков аппаратных прерываний придерживайтесь следующего:
| 1. | Не используйте в IDT шлюзы ловушек, а только прерываний, т.к. при переходе через шлюз прерывания процессор автоматически запрещает маскируемые прерывания (сбрасывая флаг IF в EFLAGS), но не делает этого для шлюза ловушки. | ||||
| 2. | В начале обработки прерывания посылайте в контроллер 8259A команду конца прерывания (EOI). Контроллер состоит из двух контроллеров master и slave. Master обслуживает первые 8 IRQ, slave — вторые и для них посылка EOI будет выглядеть так: Контроллер состоит из двух контроллеров master и slave. Master обслуживает первые 8 IRQ, slave — вторые и для них посылка EOI будет выглядеть так:
mov al,20h out 20h,al mov al,20h out 0a0h,al 3.
| Постарайтесь сделать обработку прерывания как можно быстрее, т.к. процессор не допустит генерации нового прерывания, пока не будет завершён обработчик.
| 4.
| При перенаправлении прерываний процедура «redirect_IRQ» запрещает контроллеру генерацию аппаратных прерываний. Значения в портах 21h и A1h содержат флаги маскировки прерываний для master- и slave-контроллера соответственно.
| Для того, чтобы разрешить какое-либо прерывание, нужно сбросить соответствующий бит, а для запрещения — установить. |
| Прерывания master: | ||
| Бит | IRQ | Устройство |
| 0 | 0 | Таймер |
| 1 | 1 | Клавиатура |
| 2 | 2 | Каскад (подключён ко второму контроллеру) |
| 3 | 3 | COM 2/4 |
| 4 | 4 | COM 1/3 |
| 5 | 5 | LPT 2 |
| 6 | 6 | Контроллер дисковода FDC (Floppy Drive Controller) |
| 7 | 7 | LPT 1 |
| Прерывания slave: | ||
| Бит | IRQ | Устройство |
| 0 | 8 | Часы реального времени RTC (Real Time Clock) |
| 1 | 9 | Редирект с IRQ 2 |
| 2 | 10 | Резерв (т. е. не имеет устройства по умолчанию) е. не имеет устройства по умолчанию)
|
| 3 | 11 | Резерв (т.е. не имеет устройства по умолчанию) |
| 4 | 12 | Резерв (т.е. не имеет устройства по умолчанию) |
| 5 | 13 | Исключение сопроцессора |
| 6 | 14 | Контроллер винчестера HDC (Hard Drive Controller) |
| 7 | 15 | Резерв (т.е. не имеет устройства по умолчанию) |
Например, для разрешения прерывания таймера нужно выполнить следующее:
in al,21h ; Читаем маску master-а and al,0feh ; FEh = 11111110b - сбрасываем 0-й бит. out 21h,al ; Записываем маску в контроллер.
 Таймер разрешён.
Таймер разрешён.
Как правило, операционная система защищённого режима подразумевает возврат в режим реальных адресов и выход в ту ОС, из которой её запускали (например, в MS-DOS). В таком случае необходимо предусмотреть правильное маскирование прерываний IRQ перед возвратом в такую ОС, так как обычно не все прерывания разрешены.
Начиная со следующего примера в начале будет использоваться процедура, сохраняющая маску прерываний IRQ:
store_R_Mode_IRQ_Mask proc near ; Сохраняет значение маски IRQ в переменную R_Mode_IRQ_Mask для корректного ; восстановления IRQ при возврате в R-Mode. in al,0a1h mov ah,al in al,21h mov R_Mode_IRQ_Mask,ax ret endp
Для корректного возврата в режим реальных адресов нужно изменить одну команду в процедуре перенаправления векторов IRQ для R-Mode:
init_R_Mode_redirect_IRQ macro R_Mode_redirect_IRQ proc near mov bx,7008h mov dx,R_Mode_IRQ_Mask ; Вот эту команду мы используем, ; вместо MOV DX,0.
 call redirect_IRQ
cmp APIC_presence,1
jne rmrirq_1
call enable_APIC
rmrirq_1:
ret
endp
endm
call redirect_IRQ
cmp APIC_presence,1
jne rmrirq_1
call enable_APIC
rmrirq_1:
ret
endp
endm
Теперь, казалось бы, наш пример должен правильно работать, но MS-DOS приготовил один неприятный «подводный камень». Дело в том, что при повторном запуске нашего примера, при условии, что в нём выполняются какие-либо процессы, длительностью более, чем примерно 2 секунды, контроллер клавиатуры генерирует символ. Если не обработать его должным образом, то клавиатура будет заблокирована, поэтому во всех наших примерах предлагается следующее:
| 1. | Обязательно размаскировывать прерывание клавиатуры (IRQ 1). |
| 2. | Обязательно разрешать прерывания на время выполнения части программы, работающей в защищённом режиме. |
| 3. | Установить обработчик IRQ клавиатуры или хотя бы следующую заглушку: |
IRQ_1_handler macro push ax in al,60h ; AL содержит скан-код клавиатуры, но в ; этом примере он не сохраняется - ; обработчик IRQ 1 работает как заглушка.
 in al,61H
mov ah,al
or al,80h
out 61H,al
xchg ah,al
out 61H,al
mov al,20h
out 20h,al
pop ax
iret
endm
in al,61H
mov ah,al
or al,80h
out 61H,al
xchg ah,al
out 61H,al
mov al,20h
out 20h,al
pop ax
iret
endm
Как видите, установка обработчика IRQ клавиатуры свелась к простой замене определяющего его макроса «IRQ_1_handler».
А теперь вашему вниманию предлагается демонстрация обработки прерываний по таймеру. В приведенном ниже примере внесены следующие изменения (по сравнению с предыдущим и с учётом всего, сказанного выше):
| 1. | Введена переменная «timer_count», в которой накапливаются «тики» таймера и ещё одна переменная — «timer_sec» — счётчик секунд. После каждого 18-го «тика» счётчик секунд увеличивается на 1. В качестве часов данный пример не совсем годится, т.к. за одну секунду таймер выдаёт около 18.2 «тиков» (если его дополнительно не программировать), а данный пример предназначен в качестве иллюстрации обработки IRQ и поэтому подсчёт времени здесь упрощённый.
|
| 2. | Макрос «IRQ_0_handler» изменён — он считает «тики» таймера. Теперь это не заглушка, а Обработчик Прерывания. |
| 3. | Перед тем, как в программе будут разрешены прерывания (командой STI), размаскировывается IRQ 0 (а так же и IRQ 1, для корректной обработки контроллера клавиатуры). |
| 4. | В программе приводится простой алгоритм, в котором на экран выводится dd-число, которое в бесконечном цикле увеличивается на 1. При это постоянно проверяется содержимое переменной «timer_count» и:
|
Вот так теперь выглядит обработчик IRQ 0:
IRQ_0_handler macro push ax mov al,20h out 20h,al pop ax inc timer_count iret endm
Как видите, всё что он делает — это посылает контроллеру прерываний команду конца прерывания (EOI) и увеличивает значение «timer_count» на 1. И всё! Так просто!
И всё! Так просто!
На самом деле, когда вы будете писать свою ОС, то, скорее всего, добавите в обработчик IRQ 0 функции подсчёта времени, даты и ещё что-нибудь важное, но даже в таком виде он будет корректно работать.
А вот так в примере разрешены прерывания и реализован алгоритм подсчёта и вывода времени:
; Демонстрация работы прерывания по таймеру in al,21h and al,11111100b ; Размаскируем прерывания таймера ; и клавиатуры. out 21h,al mov al,0 mov timer_count,al ; Сбрасываем наши счётчики mov timer_sec,al xor eax,eax ; Число в EAX будет выводится на экран ; в бесконечном цикле. sti ; Разрешаем аппаратные прерывания. Теперь наш ; бесконечный цикл будет "рваться" таймером и ; клавиатурой и остаётся только следить за ; счётчиками. timer_demo_start: mov dx,1400h ; В 20-ю строку, нулевую позицию .
 ..
call put_dd_num ; ... будет выводится dd-число.
inc eax ; А здесь оно увеличивается.
cmp timer_count,18
jb timer_demo_start ; Выводим число, пока timer_count
..
call put_dd_num ; ... будет выводится dd-число.
inc eax ; А здесь оно увеличивается.
cmp timer_count,18
jb timer_demo_start ; Выводим число, пока timer_count
Осталось добавить, что этот пример, как и предыдущий, правильно реагирует на исключения — выводит его номер, параметры и возвращается в R-Mode, так что можете смело экспериментировать — компьютер не зависнет.
Исходный текст примера вы можете скачать здесь: examp_6.asm, pmode_6.lib и examp_6.com в архиве examp_6.zip (9594 байт).
| Copyright © Александр Семенко. |
Как получить миллион пакетов в секунду
На прошлой неделе во время обычного разговора я услышал, как мой коллега сказал: «Сетевой стек Linux работает медленно! Нельзя ожидать, что он будет обрабатывать более 50 тысяч пакетов в секунду на каждое ядро!»
Это заставило меня задуматься. Хотя я согласен с тем, что 50kpps на ядро, вероятно, является пределом для любого практического приложения, на что способен сетевой стек Linux? Давайте перефразируем это, чтобы было веселее:
Хотя я согласен с тем, что 50kpps на ядро, вероятно, является пределом для любого практического приложения, на что способен сетевой стек Linux? Давайте перефразируем это, чтобы было веселее:
Насколько сложно в Linux написать программу, получающую 1 миллион UDP-пакетов в секунду?
Надеюсь, ответ на этот вопрос станет хорошим уроком при проектировании современного сетевого стека.
CC BY-SA 2.0 Изображение Боба Маккаффри
Сначала предположим:
Измерение пакетов в секунду (pps) намного интереснее, чем измерение байтов в секунду (Bps). Вы можете достичь высоких бит / с, улучшив конвейерную обработку и отправив более длинные пакеты. Улучшить pps намного сложнее.
Поскольку нас интересует pps, в наших экспериментах будут использоваться короткие сообщения UDP
. Если быть точным: 32 байта полезной нагрузки UDP. Это означает 74
байтов на уровне Ethernet.Для экспериментов мы будем использовать два физических сервера: «получатель» и
«отправитель».Оба они оснащены двумя шестиядерными процессорами Xeon с тактовой частотой 2 ГГц. С включенной функцией Hyper-Threading (HT), которая рассчитана на 24 процессора в каждом блоке. Коробки имеют сетевую карту 10G с несколькими очередями от Solarflare с 11 настроенными очередями приема. Подробнее об этом позже.
Исходный код тестовых программ доступен здесь:
udpsender,udpreceiver.
Предварительные требования
Давайте использовать порт 4321 для наших UDP-пакетов. Прежде чем мы начнем, мы должны убедиться, что iptables :
приемник $ iptables -I INPUT 1 -p udp --dport 4321 -j ACCEPT
приемник $ iptables -t raw -I PREROUTING 1 -p udp --dport 4321 -j NOTRACK
Позже вам пригодятся несколько явно определенных IP-адресов:
приемник $ для i в "seq 1 20"; делать \
ip адрес добавить 192.168. 254. $ I / 24 dev eth3; \
Выполнено
отправитель $ ip addr добавить 192.168.254.30/24 dev eth4
 254. $ I / 24 dev eth3; \
Выполнено
отправитель $ ip addr добавить 192.168.254.30/24 dev eth4
254. $ I / 24 dev eth3; \
Выполнено
отправитель $ ip addr добавить 192.168.254.30/24 dev eth4
- Наивный подход
Для начала проведем простейший эксперимент. Сколько пакетов будет доставлено при простой отправке и получении?
Псевдокод отправителя:
fd = socket.socket (socket.AF_INET, socket.SOCK_DGRAM)
fd.bind (("0.0.0.0", 65400)) # выбираем исходный порт для уменьшения недетерминизма
fd.connect (("192.168.254.1", 4321))
в то время как True:
fd.sendmmsg (["\ x00" * 32] * 1024)
Хотя мы могли бы использовать обычный системный вызов send , это было бы неэффективно. Переключение контекста в ядро имеет определенную цену, и ее лучше избегать. К счастью, недавно в Linux был добавлен удобный системный вызов: sendmmsg . Это позволяет нам отправлять много пакетов за один раз. Сделаем сразу 1024 пакета.
Псевдокод приемника:
fd = socket. socket (socket.AF_INET, socket.SOCK_DGRAM)
fd.bind (("0.0,0.0 ", 4321))
в то время как True:
пакеты = [Нет] * 1024
fd.recvmmsg (пакеты, MSG_WAITFORONE)
 socket (socket.AF_INET, socket.SOCK_DGRAM)
fd.bind (("0.0,0.0 ", 4321))
в то время как True:
пакеты = [Нет] * 1024
fd.recvmmsg (пакеты, MSG_WAITFORONE)
socket (socket.AF_INET, socket.SOCK_DGRAM)
fd.bind (("0.0,0.0 ", 4321))
в то время как True:
пакеты = [Нет] * 1024
fd.recvmmsg (пакеты, MSG_WAITFORONE)
Аналогично, recvmmsg является более эффективной версией обычного системного вызова recv .
Попробуем:
отправитель $ ./udpsender 192.168.254.1:4321
получатель $ ./udpreceiver1 0.0.0.0:4321
0,352 млн пакетов в секунду 10,730 МБ / 90,010 МБ
0,284 млн пакетов в секунду 8,655 МБ / 72,603 МБ
0,262 млн пакетов в секунду 7,991 МБ / 67,033 МБ
0,199 МБ / с 6,081 МБ / 51,013 МБ
0,195 млн пакетов в секунду 5.956MiB / 49.966Mb
0,199 МБ / с 6,060 МБ / 50,836 МБ
0.200M пакетов в секунду 6.097MiB / 51.147Mb
0,197 МБ / с 6,021 МБ / 50,509 МБ
При наивном подходе мы можем сделать от 197k до 350k pps. Не плохо. К сожалению, здесь довольно много вариаций. Это вызвано тем, что ядро перетасовывает наши программы между ядрами. Прикрепление процессов к процессорам поможет:
отправитель $ taskset -c 1 . /udpsender 192.168.254.1:4321
получатель $ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.362M пакетов в секунду 11.058MiB / 92.760Mb
0,374 МБ / с 11,411 МБ / 95,723 МБ
0,369 МБ / с 11,252 МБ / 94,389 МБ
0,370 МБ / с 11,289 МБ / 94,696 МБ
0,365 МБ / с 11,152 МБ / 93,552 МБ
0,360 МБ / с 10,971 МБ / 92,033 МБ
 /udpsender 192.168.254.1:4321
получатель $ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.362M пакетов в секунду 11.058MiB / 92.760Mb
0,374 МБ / с 11,411 МБ / 95,723 МБ
0,369 МБ / с 11,252 МБ / 94,389 МБ
0,370 МБ / с 11,289 МБ / 94,696 МБ
0,365 МБ / с 11,152 МБ / 93,552 МБ
0,360 МБ / с 10,971 МБ / 92,033 МБ
/udpsender 192.168.254.1:4321
получатель $ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.362M пакетов в секунду 11.058MiB / 92.760Mb
0,374 МБ / с 11,411 МБ / 95,723 МБ
0,369 МБ / с 11,252 МБ / 94,389 МБ
0,370 МБ / с 11,289 МБ / 94,696 МБ
0,365 МБ / с 11,152 МБ / 93,552 МБ
0,360 МБ / с 10,971 МБ / 92,033 МБ
Теперь планировщик ядра сохраняет процессы на определенных процессорах. Это улучшает локальность кэша процессора и делает числа более согласованными, как мы и хотели.
- Отправить больше пакетов
Хотя 370k pps — это неплохо для наивной программы, это все еще довольно далеко от цели 1Mpps.Чтобы получить больше, сначала мы должны отправить больше пакетов. Как насчет отправки независимо из двух потоков:
отправитель $ taskset -c 1,2 ./udpsender \
192.168.254.1:4321 192.168.254.1:4321
получатель $ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0,349 МБ / с 10,651 МБ / 89,343 МБ
0,354 млн пакетов в секунду 10,815 МБ / 90,724 МБ
0,354 МБ / с 10,806 МБ / 90,646 МБ
0,354 млн пакетов в секунду 10,811 МБ / 90,690 МБ
Цифры на принимающей стороне не увеличились.
ethtool -S покажет, куда на самом деле пошли пакеты:
ресивер $ watch 'sudo ethtool -S eth3 | grep rx'
Вячеславович: 451.3к / с
rx-0.rx_packets: 8.0 / с
rx-1.rx_packets: 0,0 / с
rx-2.rx_packets: 0,0 / с
rx-3.rx_packets: 0,5 / с
rx-4.rx_packets: 355,2 Кбит / с
rx-5.rx_packets: 0,0 / с
rx-6.rx_packets: 0,0 / с
rx-7.rx_packets: 0,5 / с
rx-8.rx_packets: 0,0 / с
rx-9.rx_packets: 0,0 / с
rx-10.rx_packets: 0,0 / с
Посредством этой статистики сетевая карта сообщает, что она успешно доставила около 350 тыс. Пакетов в секунду в очередь приема №4. rx_nodesc_drop_cnt — это специальный счетчик Solarflare, говорящий, что сетевая карта не смогла доставить ядру 450 тыс. Пакетов в секунду.
Иногда непонятно, почему пакеты не были доставлены. Однако в нашем случае все очень ясно: очередь приема №4 доставляет пакеты в ЦП №4. И CPU №4 больше не может работать — он полностью занят только чтением 350kpps. Вот как это выглядит в
Вот как это выглядит в htop :
Ускоренный курс по сетевым адаптерам с несколькими очередями
Исторически у сетевых карт была одна очередь RX, которая использовалась для передачи пакетов между оборудованием и ядром. У этой конструкции было очевидное ограничение — невозможно было доставить больше пакетов, чем может обработать один процессор.
Для использования многоядерных систем сетевые адаптеры начали поддерживать несколько очередей приема. Конструкция проста: каждая очередь RX закреплена на отдельном ЦП, поэтому, доставляя пакеты во все очереди RX, сетевая карта может использовать все ЦП. Но возникает вопрос: учитывая пакет, как сетевая карта решает, в какую очередь RX отправить его?
Балансировка с циклическим перебором неприемлема, так как она может привести к переупорядочению пакетов в рамках одного соединения. Альтернативой является использование хэша из пакета для определения номера очереди RX.Хэш обычно отсчитывается от кортежа (src IP, dst IP, src port, dst port).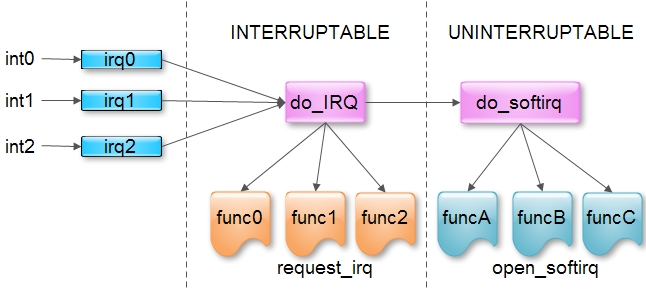 Это гарантирует, что пакеты для одного потока всегда будут попадать в одну и ту же очередь RX, и переупорядочение пакетов в одном потоке не может произойти.
Это гарантирует, что пакеты для одного потока всегда будут попадать в одну и ту же очередь RX, и переупорядочение пакетов в одном потоке не может произойти.
В нашем случае хеш можно было использовать так:
RX_queue_number = hash ('192.168.254.30', '192.168.254.1', 65400, 4321)% number_of_queues
Алгоритмы хеширования с несколькими очередями
Алгоритм хеширования можно настроить с помощью ethtool .На нашей установке это:
приемник $ ethtool -n eth3 rx-flow-hash udp4
Потоки UDP через IPV4 используют эти поля для вычисления ключа потока хэша:
IP SA
ИП DA
Это читается как: для пакетов IPv4 UDP сетевая карта будет хэшировать (src IP, dst IP) адреса. то есть:
RX_queue_number = hash ('192.168.254.30', '192.168.254.1')% number_of_queues
Это довольно ограничено, поскольку игнорирует номера портов. Многие сетевые карты позволяют настраивать хэш. Опять же, используя ethtool , мы можем выбрать кортеж (src IP, dst IP, src port, dst port) для хеширования:
приемник $ ethtool -N eth3 rx-flow-hash udp4 sdfn
Невозможно изменить параметры хеширования сетевого потока RX: операция не поддерживается
К сожалению, наша сетевая карта не поддерживает это — мы ограничены хешированием (src IP, dst IP).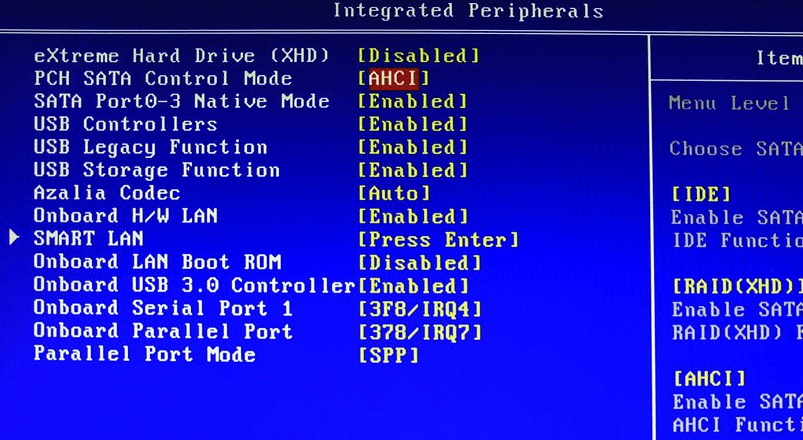
Замечание о производительности NUMA
Пока все наши пакеты проходят только в одну очередь RX и попадают только в один ЦП. Давайте воспользуемся этим как возможностью измерить производительность различных процессоров. В нашей настройке хост-приемник имеет два отдельных банка процессоров, каждый из которых является отдельным узлом NUMA.
Мы можем привязать однопоточный приемник к одному из четырех интересных процессоров в нашей установке. Четыре варианта:
Запустить приемник на другом ЦП, но на том же узле NUMA, что и очередь RX.Производительность, как мы видели выше, составляет около 360 тыс. Пакетов в секунду.
С приемником на том же процессоре, что и очередь RX, мы можем получить до ~ 430kpps. Но это создает большую изменчивость. Производительность падает до нуля, если сетевая карта перегружена пакетами.
Когда приемник работает на HT-аналоге ЦП, обрабатывающего очередь RX, производительность вдвое меньше обычного числа на уровне около 200 тыс. Пакетов в секунду.
С приемником на ЦП на узле NUMA, отличном от очереди RX, мы получаем ~ 330 тыс. Пакетов в секунду.Однако цифры не слишком согласованы.
Хотя 10% штраф за работу на другом узле NUMA может показаться неплохим, проблема только усугубляется с масштабированием. На некоторых тестах мне удалось выжать только 250kpps на ядро. Во всех кросс-NUMA тестах вариабельность была плохой. Падение производительности на узлах NUMA еще более заметно при более высокой пропускной способности. В одном из тестов я получил 4-кратный штраф при запуске приемника на плохом узле NUMA.
- Несколько IP-адресов приема
Поскольку алгоритм хеширования на нашей сетевой карте довольно ограничен, единственный способ распределить пакеты по очередям приема — использовать множество IP-адресов.Вот как отправлять пакеты на разные IP-адреса назначения:
отправитель $ taskset -c 1,2 ./udpsender 192.168.254.1:4321 192.168.254.2:4321
ethtool подтверждает, что пакеты идут в разные очереди RX:
ресивер $ watch 'sudo ethtool -S eth3 | grep rx'
rx-0.rx_packets: 8.0 / с
rx-1.rx_packets: 0,0 / с
rx-2.rx_packets: 0,0 / с
rx-3.rx_packets: 355,2 Кбит / с
rx-4.rx_packets: 0,5 / с
rx-5.rx_packets: 297,0 Кбит / с
rx-6.rx_packets: 0,0 / с
rx-7.rx_packets: 0,5 / с
rx-8.rx_packets: 0,0 / с
rx-9.rx_packets: 0,0 / с
rx-10.rx_packets: 0,0 / с
Приемная часть:
получатель $ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.609M pps 18.599MiB / 156.019Mb
0,657 Мбайт / с 20,039 Мбайт / 168,102 Мбайт
0,649 МБ / с 19,803 МБ / 166,120 МБ
Ура! Когда два ядра заняты обработкой очередей приема, а третье запускает приложение, можно получить ~ 650 тыс. Пакетов в секунду!
Мы можем еще больше увеличить это число, отправив трафик в три или четыре очереди приема, но вскоре приложение достигнет другого лимита.На этот раз rx_nodesc_drop_cnt не растет, но netstat «ошибки приемника» составляют:
приемник $ смотреть 'netstat -s --udp'
Udp:
Получено пакетов 437.0k / s
Получены пакеты 0,0 / с на неизвестный порт.
Ошибки приема пакетов со скоростью 386,9 к / с
Отправлено пакетов 0,0 / с
RcvbufErrors: 123.8k / s
SndbufErrors: 0
InCsumErrors: 0
Это означает, что, хотя сетевая карта может доставлять пакеты в ядро, ядро не может доставлять пакеты в приложение.В нашем случае он может доставить только 440 тыс. Пакетов в секунду, остальные 390 тыс. Пакетов в секунду + 123 тыс. Пакетов в секунду отбрасываются из-за того, что приложение не получает их достаточно быстро.
- Получение из множества потоков
Нам нужно масштабировать приложение-приемник. Наивный подход к получению из многих потоков не сработает:
отправитель $ taskset -c 1,2 ./udpsender 192.168.254.1:4321 192.168.254.2:4321
получатель $ taskset -c 1,2 ./udpreceiver1 0.0.0.0:4321 2
0,495 млн пакетов в секунду 15.108 МБ / 126.733 МБ
0,480 МБ / с 14,636 МБ / 122,775 МБ
0,461 МБ / с 14,071 МБ / 118,038 МБ
0,486 МБ / с 14,820 МБ / 124,322 МБ
Производительность приема снижена по сравнению с однопоточной программой. Это вызвано конфликтом блокировки на стороне приемного буфера UDP. Поскольку оба потока используют один и тот же дескриптор сокета, они тратят непропорционально много времени на борьбу за блокировку приемного буфера UDP. Эта статья описывает проблему более подробно.
Использование множества потоков для получения от одного дескриптора не оптимально.
- SO_REUSEPORT
К счастью, в Linux недавно добавлен обходной путь: флаг SO_REUSEPORT. Когда этот флаг установлен в дескрипторе сокета, Linux позволяет многим процессам связываться с одним и тем же портом. Фактически, любому количеству процессов будет разрешено связываться, и нагрузка будет распределена между ними.
С SO_REUSEPORT каждый из процессов будет иметь отдельный дескриптор сокета. Следовательно, каждый будет иметь выделенный буфер приема UDP.Это позволяет избежать проблем с конкуренцией, с которыми ранее сталкивались:
получатель $ taskset -c 1,2,3,4 ./udpreceiver1 0.0.0.0:4321 4 1
1,114 млн пакетов в секунду 34,007 МБ / 285,271 МБ
1,147 млн пакетов в секунду 34,990 МБ / 293,518 МБ
1,126 млн пакетов в секунду, 34,374 МБ / 288,354 МБ
Это больше нравится! Пропускная способность сейчас приличная!
Дальнейшее расследование покажет, что можно улучшить. Несмотря на то, что мы запустили четыре потока приема, нагрузка распределяется между ними неравномерно:
Два потока получили всю работу, а два других не получили пакетов вообще.Это вызвано конфликтом хеширования, но на этот раз на уровне SO_REUSEPORT .
Заключительные слова
Я провел несколько дополнительных тестов, и с идеально выровненными очередями приема и потоками приемника на одном узле NUMA можно было получить 1,4 млн пакетов в секунду. Запуск приемника на другом узле NUMA привел к падению числа, достигнув в лучшем случае 1 млн пакетов в секунду.
Подводя итог, если вы хотите идеальную производительность, вам необходимо:
Обеспечивает равномерное распределение трафика по множеству очередей приема и
SO_REUSEPORTпроцессам.На практике нагрузка обычно хорошо распределяется, пока существует большое количество подключений (или потоков).У вас должно быть достаточно свободной мощности ЦП, чтобы фактически принимать пакеты от ядра.
Чтобы усложнить задачу, и очереди приема, и процессы-получатели должны находиться на одном узле NUMA.
Хотя мы показали, что получение 1 млн пакетов в секунду на машине Linux технически возможно, приложение не выполняло никакой фактической обработки полученных пакетов — оно даже не просматривало содержимое трафика.Не ожидайте такой производительности для любого практического приложения без дополнительной работы.
Заинтересованы в такого рода низкоуровневой высокопроизводительной обработке пакетов? CloudFlare нанимает в Лондоне, Сан-Франциско и Сингапуре.
|
|
mpstat (1) — страница руководства Linux
mpstat (1) — страница руководства LinuxMPSTAT (1) Руководство пользователя Linux MPSTAT (1)
НАЗВАНИЕ верх
mpstat - Отчет по статистике процессоров.
ОБЗОР вверху
mpstat [-A] [--dec = {0 | 1 | 2}] [-n] [-u] [-T] [-V]
[-I { ключевое слово [,...] | ВСЕ}] [-N { список_узлов | ALL}] [-o
JSON] [-P { cpu_list | ALL}] [ интервал [ count ]]
ОПИСАНИЕ вверху
Команда mpstat записывает действия стандартного вывода для каждого
доступный процессор, процессор 0 - первый. Глобальный
Также сообщается средняя активность среди всех процессоров.В
mpstat Команда может использоваться как на SMP, так и на UP машинах, но в
в последнем случае будут напечатаны только средние глобальные активности. Если нет
активность, то отчет по умолчанию - ЦП
отчет об использовании.
Параметр interval указывает количество времени в секундах.
между каждым отчетом. Значение 0 (или без параметров вообще)
указывает, что статистика процессоров должна сообщаться для
время с момента запуска системы (загрузки).Параметр count может быть
указывается вместе с параметром интервал , если этот
не установлен в ноль. Значение count определяет количество
отчеты, созданные с интервалом секунд с интервалом секунд. Если интервал
параметр указывается без параметра count , mpstat
команда генерирует отчеты непрерывно.
ОПЦИИ наверху
-A Этот параметр эквивалентен указанию -n -u -I ALL .Эта опция также подразумевает указание -N ALL -P ALL , если только
эти параметры явно задаются в командной строке.
--dec = {0 | 1 | 2}
Укажите количество десятичных знаков для использования (от 0 до 2,
значение по умолчанию 2).
-I { ключевое слово [, ...] | ALL}
Сообщать статистику прерываний. Возможные ключевых слов - это CPU ,
SCPU и SUM .С ключевым словом CPU количество каждого отдельного
прерывание, полученное ЦП или ЦП в секунду,
отображается. Прерывания перечислены в / proc / interrupts .
файл.
С ключевым словом SCPU количество каждого человека
программное прерывание, полученное ЦП или ЦП в секунду
отображается. Эта опция работает только с ядрами 2.6.31.
и позже.Программные прерывания перечислены в
/ proc / softirqs файл.
С ключевым словом SUM команда mpstat сообщает общее
количество прерываний на процессор. Следующие значения
отображаются:
ЦП Номер процессора. Ключевое слово all указывает, что
статистика рассчитывается как среднее значение среди всех
процессоры.
intr / s Показать общее количество прерываний, полученных за
во-вторых, ЦП или ЦП.Ключевое слово ALL эквивалентно указанию всех
ключевые слова выше и, следовательно, вся статистика прерываний
отображаются.
-N { node_list | ALL}
Укажите узлы NUMA, для которых нужно вести статистику.
сообщил. node_list - это список значений, разделенных запятыми.
или диапазон значений (например, 0,2,4-7,12- ). Обратите внимание, что узел все
это среднее глобальное значение среди всех узлов.Ключевое слово ALL
указывает, что статистика должна быть представлена для всех
узлы.
-n Сводная статистика ЦП на основе узла NUMA
размещение. Отображаются следующие значения:
NODE Логический номер узла NUMA. Ключевое слово означает, что все
эта статистика рассчитывается как среднее значение среди
все узлы.
Все остальные поля такие же, как те, которые отображаются с
опция -u (см. ниже). -o JSON
Отображение статистики в формате JSON (объект Javascript
Обозначение) формат. Порядок выходных полей JSON не определен,
и в будущем могут быть добавлены новые поля.
-P { cpu_list | ALL}
Укажите процессоры, по которым должна вестись статистика.
сообщил. cpu_list - это список значений, разделенных запятыми, или
диапазон значений (например, 0,2,4-7,12- ).Обратите внимание, что процессор
0 - первый процессор, а процессор - все - глобальный
средний среди всех процессоров. Ключевое слово ALL указывает
эта статистика должна быть представлена для всех процессоров.
Автономные процессоры не отображаются.
-T Отображение элементов топологии в отчете ЦП (см. Опцию -u
ниже). Отображаются следующие элементы:
CORE Логический номер ядра.SOCK Номер логического гнезда.
NODE Логический номер узла NUMA.
-u Сообщает об использовании ЦП. Следующие значения:
отображается:
ЦП Номер процессора. Ключевое слово all указывает, что
статистика рассчитывается как среднее значение среди всех
процессоры.
% usr Показать процент использования ЦП, который
произошло при выполнении на уровне пользователя
(заявление).% nice Показывает процент использования ЦП, который
произошло при выполнении на уровне пользователя с
приятный приоритет.
% sys Показать процент использования ЦП, который
произошло при выполнении на системном уровне
(ядро). Обратите внимание, что это не включает время
потратил на обслуживание аппаратных и программных прерываний.
% iowait
Показать процент времени, в течение которого ЦП или ЦП
простаивали, в течение которых система
невыполненный дисковый запрос ввода-вывода.% irq Показать процент времени, затрачиваемого ЦП или
ЦП для обслуживания аппаратных прерываний.
% soft Показать процент времени, затрачиваемого ЦП или
ЦП для обслуживания программных прерываний.
% steal Показать процент времени, проведенного непроизвольно
подождите, пока виртуальный ЦП или ЦП
гипервизор обслуживал другой виртуальный процессор.
% guest Показать процент времени, потраченного ЦП или
ЦП для запуска виртуального процессора.% gnice Показать процент времени, затрачиваемого ЦП или
ЦП для запуска приятного гостя.
% простоя Показывает процент времени, в течение которого ЦП или ЦП
простаивали, и в системе не было
невыполненный дисковый запрос ввода-вывода.
-V Распечатать номер версии и выйти.
ОКРУЖАЮЩАЯ СРЕДА наверху
Команда mpstat учитывает следующую среду
Переменная:
S_COLORS
По умолчанию статистика отображается в цвете, когда
выход подключен к терминалу.Используйте эту переменную, чтобы
изменить настройки. Возможные значения для этой переменной:
никогда , всегда или авто (последний эквивалент
настройки по умолчанию).
Обратите внимание, что цвет (красный, желтый или
другой цвет), используемый для отображения значения, не указывает на
любая проблема просто из-за цвета. Это только
указывает разные диапазоны значений. S_COLORS_SGR
Укажите цвета и другие атрибуты, используемые для отображения
статистика по терминалу. Его значение - двоеточие.
разделенный список возможностей, по умолчанию
H = 31; 1: I = 32; 22: M = 35; 1: N = 34; 1: Z = 34; 22 . Поддерживается
возможности:
H = Подстрока SGR (Select Graphic Rendition) для
процентные значения больше или равны 75%.
I = Подстрока SGR для номера процессора. M = Подстрока SGR для процентных значений в диапазоне
от 50% до 75%.
N = Подстрока SGR для ненулевых значений статистики.
Z = Подстрока SGR для нулевых значений.
S_TIME_FORMAT
Если эта переменная существует и ее значение составляет ISO , то
текущая локаль будет проигнорирована при печати даты в
заголовок отчета. Команда mpstat будет использовать ISO
8601 формат (ГГГГ-ММ-ДД).Отметка времени также будет
соответствовать формату ISO 8601.
ПРИМЕРЫ наверху
mpstat 2 5
Отображение пяти отчетов глобальной статистики среди всех
процессоров с интервалом в две секунды.
mpstat -P ВСЕ 2 5
Отобразить пять отчетов со статистикой для всех процессоров на
двухсекундные интервалы.
ОШИБКИ вверху
Файловая система / proc должна быть смонтирована для работы команды mpstat .ФАЙЛОВ вверху
/ proc содержит различные файлы с системной статистикой.
АВТОР верх
Себастьян Годар (sysstat orange.fr)
СМОТРИ ТАКЖЕ top
sar (1), pidstat (1), iostat (1), vmstat (8)
https://github.com/sysstat/sysstat
http://pagesperso-orange.fr/sebastien.godard/
COLOPHON верх
Эта страница является частью sysstat (sysstat performance monitoring
инструменты) проект.Информацию о проекте можно найти на сайте
⟨Http: //sebastien.godard.pagesperso-orange.fr/⟩. Если у тебя есть
отчет об ошибке для этой страницы руководства, отправьте его на sysstat-AT-orange.fr.
Эта страница была получена из исходного репозитория Git проекта.
⟨Https: //github.com/sysstat/sysstat.git⟩ от 2021-04-01. (При этом
время, дата самой последней фиксации, которая была найдена в
репозиторий был 2021-02-15.) Если вы обнаружите какой-либо рендеринг
проблемы в этой HTML-версии страницы, или вы верите в нее
является лучшим или более актуальным источником для страницы, или у вас есть
исправления или улучшения информации в этом COLOPHON
(это , а не часть исходной страницы руководства), отправьте письмо по адресу
man-страницы @ man7.org
Страницы, которые относятся к этой странице: цифсиостат (1), iostat (1), iowatcher (1), nfsiostat-sysstat (1), pcp-mpstat (1), pidstat (1), сар (1), гобелен (1), vmstat (8)
Сетевой адаптер Windows Жаргон — Дэвид Миллингтон
За последние несколько лет мне всегда было любопытно попытаться настроить параметры сетевого адаптера, как вы можете видеть из некоторых из моих прошлых сообщений; Исправление низкой скорости сети Vistas, Vista VPN == медленный доступ к сети, конец моих проблем с беспроводной связью и всплески пинга беспроводной сети.Мне всегда было довольно сложно найти определения того, что делает каждая из настроек. Обычно все сводится к тому, что я гуглил названия конкретных настроек и надеялся найти что-то подходящее на понятном английском языке. Сегодня я решил обновить свой сетевой драйвер Marvell и обнаружил, что файл readme действительно содержит полное описание каждой настройки. Ради потомков я публикую это здесь на случай, если кто-то еще попытается найти эти варианты и их значения.
Следующее извлечено из файла readme для Marvell Yukon 88E8056 PCI-E Gigabit Ethernet Controller v10.66.4.3 zip-файл драйвера.
© Marvell®, 2002–2008.
Все права защищены.
yk60x64.sys: 64-разрядный драйвер минипорта, NDIS6.0
Параметры
Драйвер позволяет изменять несколько параметров, чтобы оптимизировать работу
адаптера.
- В «Сетевые подключения» щелкните правой кнопкой мыши адаптер, который нужно настроить.
- Выберите «Свойства».
- Щелкните «Настроить».
- Щелкните «Дополнительно».
- В поле «Свойство» выберите параметр, который нужно изменить.
- Введите желаемое значение в поле «Значение».
- Нажмите ОК.
- Операционная система перезагрузит драйвер с измененными настройками.
Параметры, поддерживаемые драйвером, описаны ниже.
Сетевой адрес
Значение по умолчанию: адрес встроенного адаптера
Допустимый диапазон: «02-00-00-00-00-01» до «FE-FF-FF-FF-FF-FF» ( шестнадцатеричный), где по крайней мере бит «многоадресной рассылки» (бит 0) не должен быть установлен (он указывает, что поле адреса содержит индивидуальный адрес), а бит «локально управляемый» (бит 1) установлен (адрес был назначен местным администратором).Эти два бита являются первым и вторым битами, передаваемыми по локальной сети.
ВНИМАНИЕ: Каждый отдельный сетевой MAC-адрес может использоваться в сети только один раз. Назначение одного и того же адреса более чем одному адаптеру в одной сети запрещено и может вызвать серьезные проблемы.
Чтобы использовать сетевой MAC-адрес, отличный от записанного в адаптер, введите сетевой адрес в следующем шестнадцатеричном формате: 02-00-5A-98-12-34
Если поле сетевого адреса оставлено пустым (или указано другое количество цифр), будет использоваться сетевой адрес, записанный в адаптер.
Jumbo Packet
Задает размер кадра, поддерживаемый драйвером. Производительность вашей сети обычно увеличивается, когда используются Jumbo-кадры размером> 1514.
Значение по умолчанию: «1514 байтов»
Допустимые значения:
- «4088 байт»
- «9014 байтов»
ПРИМЕЧАНИЕ: Если вы не уверены, поддерживает ли ваша сеть Jumbo-кадры, не устанавливайте размер> 1514.
ПРИМЕЧАНИЕ: Для адаптеров Fast Ethernet допустимый диапазон ограничен 1514.
Разгрузка контрольной суммы IPv4
Используется для управления разгрузкой контрольной суммы оборудования для трафика IPv4. Нет необходимости отключать разгрузку контрольной суммы.
Значение по умолчанию: «Tx & Rx Enabled»
Допустимые значения:
- «Передача и прием разрешены»
- «Передача включена»
- «Прием включен»
- «Отключено»
Разгрузка контрольной суммы TCP (IPv4), разгрузка контрольной суммы UDP (IPv4), разгрузка контрольной суммы TCP (IPv6), разгрузка контрольной суммы UDP (IPv6)
Используется для управления разгрузкой контрольной суммы оборудования для комбинаций версий TCP / UDP и IP.Нет необходимости отключать разгрузку контрольной суммы.
Значение по умолчанию: «Tx & Rx Enabled»
Допустимые значения:
- «Передача и прием разрешены»
- «Передача включена»
- «Прием включен»
- «Отключено»
ПРИМЕЧАНИЕ. Параметры IPv6 доступны не для каждого типа адаптера.
Возможности пробуждения
Значение по умолчанию: «Magic Packet & Pattern Match»
Допустимые значения:
- «Нет» — функция пробуждения по локальной сети отключена
- «Magic Packet» — пробуждение с помощью Magic Packet из состояния выключения, пробуждение под управлением ОС из состояния гибернации или ожидания
- «Соответствие шаблону» — пробуждение с помощью пакета, содержащего специальный шаблон, из состояния выключения, пробуждение, управляемое ОС, из состояния гибернации или ожидания
- «Magic Packet & Pattern Match» — пробуждение с обоими из состояния выключения, пробуждение под управлением ОС из состояния гибернации или ожидания
- «Изменение связи» — пробуждение с изменением связи из состояния выключения, пробуждение под управлением ОС из состояния гибернации или ожидания
Пробуждение после выключения
Значение по умолчанию: «Выкл.»
Допустимые значения:
- «Выкл.» — отключение возможности адаптера выводить систему из состояния выключения.
- «Вкл.» — позволяет адаптеру выводить систему из состояния выключения.
Energy Star
Используется для снижения энергопотребления в режиме ожидания и гибернации, когда включены функции Wake On LAN.
Значение по умолчанию: «Включено»
Допустимые значения:
- «Отключено» — в адаптере не включены функции энергосбережения.
- «Включено» — скорость канала переключается на 10 Мбит / с для снижения энергопотребления.
ПРИМЕЧАНИЕ: Этот параметр доступен не для каждого типа адаптера.
Буферы приема
Определяет количество буферов приема, выделяемых драйвером. Если в системе недостаточно ресурсов, драйвер не загрузится.
Увеличение этого значения может улучшить производительность.
Для адаптеров Ethernet семейства Yukon используются следующие значения:
Значение по умолчанию: 50 (десятичное)
Допустимый диапазон: 3..500 (десятичный)
Для адаптеров Ethernet семейства Yukon2 используются следующие значения:
Значение по умолчанию: 256 (десятичное)
Допустимый диапазон: 256..512 (десятичное)
Буферы передачи
Определяет количество буферов передачи, выделяемых драйвером. Если в системе недостаточно ресурсов, драйвер не загрузится. Увеличение этого значения может улучшить производительность.
Для адаптеров Ethernet семейства Yukon используются следующие значения:
Значение по умолчанию: 50 (десятичное)
Допустимый диапазон: 4..200 (десятичный)
Для адаптеров Ethernet семейства Yukon2 используются следующие значения:
Значение по умолчанию: 256 (десятичное)
Допустимый диапазон: 256..512 (десятичное)
Модерирование прерываний
Если частота прерываний превышает указанную, функция «Модерация прерываний
» группирует эти прерывания так, чтобы можно было обработать несколько пакетов данных
на прерывание. Это приведет к снижению загрузки ЦП, но может увеличить задержку
.
Значение по умолчанию: «Включено»
VA Значения крышки:
- «Включено»
- «Отключено»
Макс. IRQ в секунду
Задает частоту прерываний для их модерации. Если для параметра «Модерация прерывания» установлено значение «Выкл.», Оно будет проигнорировано.
Значение по умолчанию: 5000 (десятичное)
Допустимое значение: 1000..30000 (десятичное)
Сообщения о состоянии журнала
Задает сообщения, которые должны регистрироваться в журнале событий.
Значение по умолчанию: «Сообщения о состоянии»
Допустимые значения:
- «Все сообщения» — следует использовать только в тестовых целях.
- «Сообщения о состоянии» — драйвер будет создавать запись в журнале событий каждый раз при изменении статуса связи.
- «Предупреждения» — будут генерироваться только предупреждения или сообщения об ошибках.
- «Ошибки» — будут создаваться только сообщения об ошибках.
- «Нет» — все сообщения драйвера будут подавлены (не рекомендуется).
Скорость и дуплекс
Содержит информацию об автосогласовании, возможностях дуплекса и скорости соединения.
Значение по умолчанию: «Автосогласование»
Допустимые значения:
- «Автосогласование»
- «Полудуплекс 10 Мбит / с»
- «Полный дуплекс, 10 Мбит / с»
- «Полудуплекс 100 Мбит / с»
- «100 Мбит / с, полный дуплекс»
- «1000 Мбит / с, полный дуплекс»
ПРИМЕЧАНИЕ: Этот параметр недействителен для волоконно-оптических адаптеров.
Предпочитаемый порт
Устанавливает предпочтительный порт для RLMT (технология управления избыточным каналом). Этот порт будет использоваться для всего сетевого трафика, если более одного порта имеют активное соединение с сетью.
Значение по умолчанию: «A»
Допустимые значения:
ПРИМЕЧАНИЕ. Этот параметр доступен только для двухканальных адаптеров.
Режим RLMT
Значение по умолчанию: «CLS»
Допустимые значения:
- «CLS» (проверка состояния канала) — RLMT использует состояние канала, сообщаемое аппаратным обеспечением адаптера для каждого отдельного порта, чтобы определить, может ли порт использоваться для всего сетевого трафика или нет.
- «CLP» (Проверить локальный порт) — RLMT отслеживает сетевой путь между двумя портами адаптера, регулярно обмениваясь пакетами между ними. Для этого режима требуется конфигурация сети, в которой два порта «видят» друг друга (т. Е. Между портами не должно быть маршрутизатора).
- «CLPSS» (Проверка локальных портов и состояния сегментации) — поддерживает те же функции, что и режим «CLP», и дополнительно проверяет сегментацию сети, отправляя пакеты приветствия BPDU. Этот режим работает, только если в сети установлены коммутаторы Gigabit Ethernet, настроенные для использования протокола Spanning Tree.
ПРИМЕЧАНИЕ. Режимы RLMT «CLP» и «CLPSS» предназначены для работы в конфигурациях, где существует сетевой путь между портами на одном адаптере. Более того, они не предназначены для работы, когда адаптеры подключены друг к другу. Этот параметр доступен только для двухканальных адаптеров.
Priority & VLAN
Включает / отключает возможности 802.1p (QoS) и / или 802.1q (VLAN).
Значение по умолчанию: «Приоритет включен»
Допустимые значения:
- «Приоритет включен»
- «VLAN включен»
- «Приоритет и VLAN включены»
- «Приоритет и VLAN отключены»
ПРИМЕЧАНИЕ: Это только позволит драйверу обрабатывать такие пакеты.Должен существовать протокол или приложение, которое передает такие пакеты драйверу.
Battery Mode Link Detection
Устанавливает режим, в котором работает адаптер, если нет связи и система питается от батареи.
Значение по умолчанию: «EnergyDetect + (TM)»
Допустимые значения:
- «Нет энергосбережения» — в адаптере не включены функции энергосбережения.
- «Максимальное энергосбережение» — при отсутствии ссылки адаптер выключен.Драйвер будит адаптер каждые 20 секунд, чтобы проверить, есть ли новая ссылка.
- «EnergyDetect + (TM)» — в режиме «EnergyDetect + (TM)» соединение активируется быстрее, чем в режиме «Максимальное энергосбережение», но для адаптера требуется больше энергии.
ПРИМЕЧАНИЕ: Этот параметр доступен не для каждого типа адаптера.
Настройки скорости батареи
Устанавливает скорость соединения для адаптера, когда система питается от батареи.
Значение по умолчанию: «Полная скорость»
Допустимые значения:
- «Умное снижение скорости» — скорость канала переключается на 10/100 Мбит / с для снижения энергопотребления.
- «Полная скорость» — адаптер работает с максимальной скоростью и максимальным энергопотреблением (без энергосбережения, как при питании системы от сети переменного тока).
ПРИМЕЧАНИЕ: Этот параметр доступен не для каждого типа адаптера.
Управление потоком
Устанавливает возможности управления потоком для автоматического согласования.
Значение по умолчанию: «Tx & Rx Enabled»
Допустимые значения:
- «Отключено» — ни одному партнеру по каналу не разрешено отправлять кадры ПАУЗЫ.
- «Tx & Rx Enabled» — обоим партнерам по каналу разрешено отправлять кадры PAUSE.
Этот параметр можно установить для каждого порта индивидуально, что полезно, если порт на другом конце кабеля не может обрабатывать все возможные комбинации. Используя настройку по умолчанию, адаптер должен автоматически определять возможности однорангового порта.
Разгрузка большой отправки (IPv4)
Используется для управления возможностью разгрузки большой отправки для трафика IPv4.
Значение по умолчанию: «Включено»
Допустимые значения:
- «Включено» — большие пакеты сегментируются на адаптере перед отправкой в сеть.При использовании этого метода нагрузка будет снята с процессора.
- «Отключено» — пакеты не сегментируются адаптером.
ПРИМЕЧАНИЕ: Этот параметр доступен только начиная с адаптеров на базе микросхемы Yukon2.
Разгрузка большой отправки v2 (IPv4), разгрузка большой отправки v2 (IPv6)
Используется для управления возможностями разгрузки большой отправки версии 2 для трафика IPv4 и IPv6.
Значение по умолчанию: «Включено»
Допустимые значения:
- «Включено»
- «Отключено»
ПРИМЕЧАНИЕ: Эти параметры доступны не для каждого типа адаптера.
Масштабирование на стороне приема
Включает / отключает балансировку получаемой сетевой нагрузки от сетевого адаптера между несколькими ЦП.
Значение по умолчанию: «Отключено»
Допустимые значения:
- «Включено»
- «Отключено»
ПРИМЕЧАНИЕ: Этот параметр доступен не для каждого типа адаптера.
4.3. Настройка прерываний и IRQ Red Hat Enterprise Linux 6
Запрос прерывания (IRQ) — это запрос на обслуживание, отправляемый на аппаратном уровне.Прерывания могут отправляться либо по выделенной аппаратной линии, либо по аппаратной шине в виде информационного пакета (прерывание с сообщением или MSI).
Когда прерывания разрешены, получение IRQ побуждает переключиться на контекст прерывания. Код диспетчеризации прерывания ядра извлекает номер IRQ и связанный с ним список зарегистрированных подпрограмм обслуживания прерывания (ISR) и по очереди вызывает каждую ISR. ISR подтверждает прерывание и игнорирует избыточные прерывания от того же IRQ, а затем ставит отложенный обработчик в очередь, чтобы завершить обработку прерывания и не дать ISR игнорировать будущие прерывания.
В файле / proc / interrupts указано количество прерываний на ЦП на устройство ввода-вывода. Он отображает номер прерывания, номер прерывания, обработанного каждым ядром ЦП, тип прерывания и список драйверов, зарегистрированных для получения этого прерывания, через запятую. (См. Дополнительную информацию на странице руководства по proc (5): man 5 proc )
IRQ имеют связанное свойство «affinity», smp_affinity , которое определяет ядра ЦП, которым разрешено выполнять ISR для этого IRQ.Это свойство можно использовать для повышения производительности приложения путем присвоения привязки прерывания и привязки потока приложения к одному или нескольким конкретным ядрам ЦП. Это позволяет разделить строку кэша между указанным прерыванием и потоками приложения.
Значение сродства прерывания для конкретного номера IRQ хранится в соответствующем файле / proc / irq / IRQ_NUMBER / smp_affinity , который может просматривать и изменять пользователь root. Значение, хранящееся в этом файле, представляет собой шестнадцатеричную битовую маску, представляющую все ядра ЦП в системе.
Например, чтобы установить привязку прерывания для драйвера Ethernet на сервере с четырьмя ядрами ЦП, сначала определите номер IRQ, связанный с драйвером Ethernet:
# grep eth0 / proc / interrupts 32: 0140 45 850264 PCI-MSI-край eth0
Используйте номер IRQ, чтобы найти соответствующий файл smp_affinity :
# cat / proc / irq / 32 / smp_affinity f
Значение по умолчанию для smp_affinity — f , что означает, что IRQ может обслуживаться на любом из процессоров в системе.Установка этого значения на 1 , как показано ниже, означает, что только ЦП 0 может обслуживать это прерывание:
# эхо 1> / proc / irq / 32 / smp_affinity # cat / proc / irq / 32 / smp_affinity 1
Запятые могут использоваться для разделения smp_affinity значений для дискретных 32-битных групп. Это требуется в системах с более чем 32 ядрами. Например, следующий пример показывает, что IRQ 40 обслуживается на всех ядрах 64-ядерной системы:
# cat / proc / irq / 40 / smp_affinity ffffffff, ffffffff
Чтобы обслуживать IRQ 40 только на верхних 32-ядерных 64-ядерных системах, вы должны сделать следующее:
# эхо 0xffffffff, 00000000> / proc / irq / 40 / smp_affinity # cat / proc / irq / 40 / smp_affinity ffffffff, 00000000
В системах, которые поддерживают управление прерываниями , изменение smp_affinity IRQ настраивает оборудование таким образом, чтобы решение об обслуживании прерывания конкретным ЦП принималось на аппаратном уровне без вмешательства ядра.
96-irqs__hardware_interrupts — Техническая помощь!
96-irqs__hardware_interrupts — Техническая помощь! █▌Обзор▐█
Такие устройства, как клавиатура и контроллер диска, подключаются к
CPU через линии запроса прерывания (IRQ). Когда этим устройствам понадобится
обслуживания, они сигнализируют процессору, который немедленно начинает выполнение
код в конкретном векторе прерывания.
█▌Стандартные IRQ▐█
INT 08H IRQ 0 Прерывания таймера каждые 55 мс (18,2 раза в секунду)
INT 09H IRQ 1 Прерывания клавиатуры при каждом нажатии и отпускании клавиши
и периодически при нажатой клавише.См. Порты клавиатуры.
INT 0aH IRQ 2 каскад Подключен к вторичному прерыванию 8259a
контроллер на АЦ; может использоваться EGA для
вертикальный откат. См. Порты ввода-вывода EGA.
INT 0bH IRQ 3 COM 2/4 Прерывается, когда COM2 или COM4 что-то
сказать. См. Последовательные порты.
INT 0cH IRQ 4 COM 1/3 Прерывается, когда COM1 или COM3 что-то
сказать.См. Последовательные порты.
INT 0dH IRQ 5 LPT 2 AT: Прерывание, когда принтер на LPT2 готов
для другого символа (только если порт принтера 27aH
настроен для этого). См. Порты принтера.
PC / XT: Это использовалось для жесткого диска. Видеть
Порты для жестких дисков XT.
INT 0eH IRQ 6 diskette Прерывание после каждого действия с дискетой
контроллер дискет (чтение, запись, поиск и т. д.).См. Порты FDC.
INT 0fH IRQ 7 LPT 1 Прерывается, когда LPT1 готов к другому
символ (только если установлен порт контроллера 37aH)
для этого). См. Порты принтера.
INT 70H IRQ 8 RT Тактовые прерывания 1024 раза в секунду (для AT-класса или
лучше компы). Это создается
такое же оборудование, которое обрабатывает энергонезависимые данные
в памяти CMOS.INT 71H IRQ 9 redir IRQ2 На компьютерах класса AT IRQ 2 используется как
подключение к вторичному прерыванию 8259a
контроллер. Фактические появления IRQ 2:
перенаправлен на IRQ 9. Это IRQ может быть сгенерировано
компании EGA / VGA. См. Порты ввода-вывода EGA.
INT 72H IRQ 10 (зарезервировано) Для этого IRQ нет устройства по умолчанию.
INT 73H IRQ 11 (зарезервировано) Для этого IRQ нет устройства по умолчанию.INT 74H IRQ 12 (зарезервировано) Для этого IRQ нет устройства по умолчанию.
Математический чип INT 75H IRQ 13 Математический сопроцессор 80x87 генерирует это
прерывание по исключениям (ошибкам).
INT 76H IRQ 14 hard disk Прерывает, когда контроллер жесткого диска
завершает операцию. См. Порты для жестких дисков AT.
INT 77H IRQ 15 (зарезервировано) Для этого IRQ нет устройства по умолчанию.
См. Также: прерывания и службы BIOS
Карта портов ввода / вывода
- ♦ -
Проблемы с качеством звука на оборудовании Digium (черновик)
Как видно выше, каждому устройству, которому требуется прерывание, будет назначен собственный IRQ, если доступно свободное.(Обратите внимание, что не каждой плате PCI требуется IRQ!) Если свободное IRQ не найдено, IRQ также можно разделить между несколькими устройствами. (Это происходит автоматически.
Эти общие IRQ используются для того, чтобы разрешить более чем 4 IRQ, использующим устройства, работать на 1 шине PCI — когда APIC недоступен.
Для большинства устройств это может работать нормально, но такое совместное использование IRQ увеличивает задержки для прерываний, вызывая звуковые тики, треск … Мы этого не хотим!
Стандартный дистрибутив Linux поставляется с утилитой lspci , которую можно использовать для вывода списка всех шин и карт PCI.
С ключом -v отобразится список всех карт + irq, которые они используют.
Внимательно посмотрите, не используется ли IRQ, используемый вашей картой, другим устройством.
Если вы используете APIC, вы также можете использовать переключатель -b, чтобы узнать, какое прерывание IRQ использует карта. (ключ -v покажет вам, какое IRQ ядро назначило карте.)
пример вывода lspci -v: (на сервере с APIC и TE410p)
03: 09.0 Коммуникационный контроллер: Xilinx, Inc.: Неизвестное устройство 0314 (ред. 01)
Флаги: мастер шины, средний devsel, задержка 64, IRQ 27
Память на fe8e0000 (32-разрядная, без предварительной выборки) [size = 128]
пример вывода lspci -vb: (на том же сервере)
03: 09.0 Коммуникационный контроллер: Xilinx, Inc .: Неизвестное устройство 0314 (версия 01)
Флаги: мастер шины, средний devsel, задержка 64, IRQ 9
Память на fe8e0000 (32-разрядная, без предварительной выборки)
Если карта использует то же IRQ, что и какое-то другое устройство в выводе lspci -v, это, вероятно, вызовет проблемы, поскольку это совместное использование IRQ добавляет дополнительные задержки к прерыванию.
Обратите внимание, что в этом примере IRQ составляет 27, и карта считает, что это IRQ 9. Никакое другое устройство не должно использовать IRQ 27 в этом случае. (Для некоторых других карт это нормально, если они думают, что они используют IRQ 9.
Это нормально, если карты, отличные от zaptel, разделяют IRQ (хотя сетевым картам, вероятно, это тоже не понравится).)
Если вы используете совместное использование IRQ, убедитесь, что все устройства / карты, использующие общие IRQ, являются PCI или AGP, без isa.
Чтобы решить эту проблему:
— просмотрите BIOS и отключите все устройства, которые вам не нужны, например USB.видеокарта, дополнительная сетевая карта, чтобы освободить еще несколько IRQ.— Если это не помогло, посмотрите, можете ли вы назначить IRQ конкретному слоту PCI в BIOS. (Большинство современных биозов этого не допускают).
— Если все вышеперечисленное не помогло, попробуйте переместить карту в другой слот PCI, отключить опцию plug ‘n play OS в BIOS, перезагрузить компьютер и повторить попытку.
— Включить APIC в ядре (по умолчанию он включен в SMP, но может быть задана опция командной строки для его отмены).
— Отключить балансировку нагрузки IRQ в ядре
.