
Логическая структура реляционной базы данных
Логическая структура реляционной базы данных Access является адекватным отображением полученной информационно-логической модели предметной области. Для канонической модели не требуется дополнительных преобразований. Каждый информационный объект модели данных отображается соответствующей реляционной таблицей. Структура реляционной таблицы определяется реквизитным составом соответствующего информационного объекта, где каждый столбец (поле) соответствует одному из реквизитов объекта. Ключевые реквизиты объекта образуют уникальный ключ реляционной таблицы. Для каждого столбца таблицы (поля) задается тип, размер данных и другие свойства. Строки (записи) таблицы соответствуют экземплярам объекта и формируются при загрузке таблицы.
Логическая структура реляционной базы данных
Связи между объектами модели данных реализуются одинаковыми реквизитами — ключами связи в соответствующих таблицах. При этом ключом связи типа 1 : M всегда является уникальный ключ главной таблицы. Ключом связи в подчиненной таблице является либо некоторая часть уникального ключа в ней, либо поле, не входящее в состав первичного ключа (например, код фирмы в таблице СКЛАД). Ключ связи в подчиненной таблице называется внешним ключом.
Все связи в полученной информационно-логической модели предметной области «Поставка товара» характеризуются отношением типа 1 : M. Соответственно, связь между таблицами ПОКУПАТЕЛЬ и ДОГОВОР осуществляется по коду покупателя (КОД_ПОК), который является уникальным идентификатором главного объекта ПОКУПАТЕЛЬ и неключевым в объекте ДОГОВОР (см. табл. 2.6).
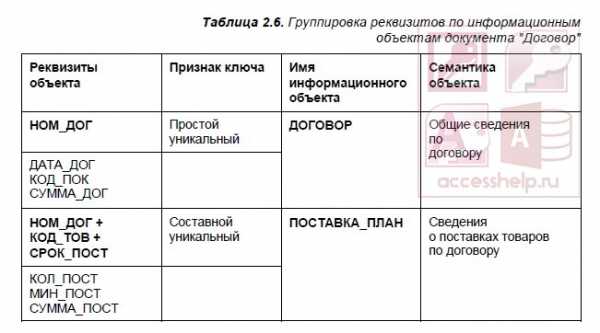
Связь между таблицами ТОВАР и ПОСТАВКА_ПЛАН осуществляется по уникальному ключу главного объекта ТОВАР — Коду товара, который в подчиненном объекте ПОСТАВКА_ПЛАН является частью ключа (см. табл. 2.6). Аналогично связь между таблицами ТОВАР и ОТГРУЗКА осуществляется по уникальному ключу главного объекта ТОВАР — Коду товара.
Связь между таблицами ДОГОВОР и НАКЛАДНАЯ осуществляется по уникальному ключу главного объекта ДОГОВОР — Номеру договора (НОМ_ДОГ), который в подчиненном объекте НАКЛАДНАЯ не входит в состав ключа (см. табл. 2.7).
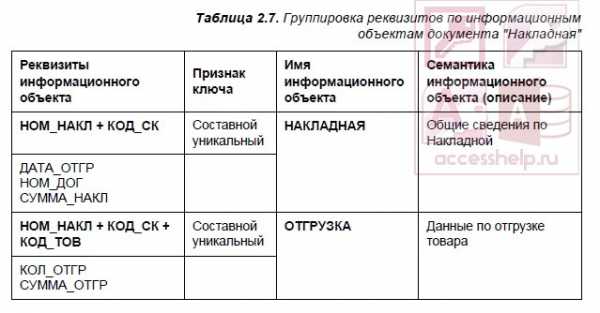
Связь между таблицами ДОГОВОР и ПОСТАВКА_ПЛАН осуществляется по уникальному ключу главного объекта ДОГОВОР — Номеру договора (НОМ_ДОГ), который в подчиненном объекте ПОСТАВКА_ПЛАН является частью ключа (см. табл. 2.6). Аналогично связь между таблицами НАКЛАДНАЯ и ОТГРУЗКА осуществляется по уникальному составному ключу главного объекта НАКЛАДНАЯ — НОМ_НАКЛ + + КОД_СК, который в подчиненном объекте ОТГРУЗКА является частью ключа (см. табл. 2.7).
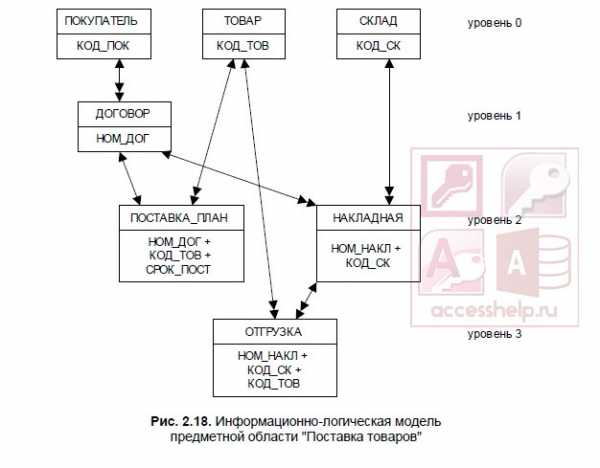
В Access может быть создана схема данных, наглядно отображающая логическую структуру базы данных. Определение одно-многозначных связей в этой схеме должно осуществляться в соответствии с построенной моделью данных. Топология проекта схемы данных практически совпадает с топологией информационно-логической модели. Для модели данных предметной области (см. рис. 2.18), построенной в рассмотренном примере, логическая структура базы данных в виде схемы данных Access приведена на рис. 2.19.
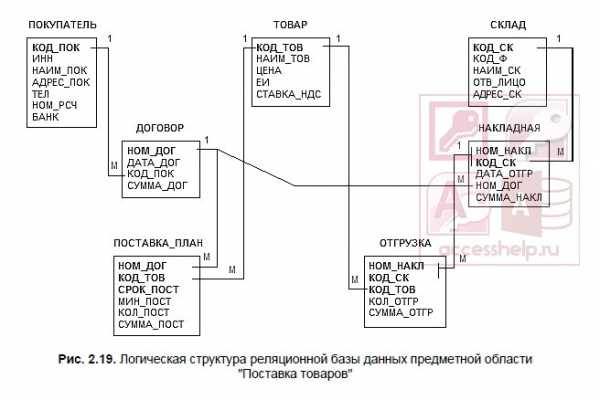
На этой схеме прямоугольники отображают таблицы базы данных с полным списком их полей, а связи показывают, по каким полям осуществляется взаимосвязь таблиц. Имена ключевых полей для наглядности выделены и находятся в верхней части полного списка полей каждой таблицы.
accesshelp.ru
10 структур данных, которые вы должны знать (+видео и задания)
Бо Карнс – разработчик и преподаватель расскажет о наиболее часто используемых и общих структурах данных. Специально для вас мы перевели его статью.
«Плохие программисты беспокоятся о коде. Хорошие программисты беспокоятся о структурах данных и их отношениях ». — Линус Торвальдс, создатель Linux
Структуры данных являются важной частью разработки программного обеспечения и одной из наиболее распространенных тем для вопросов на собеседованиях с разработчиками.
Хорошая новость в том, что они в основном являются просто специализированными форматами для организации и хранения данных.
Из этой статьи вы узнаете о 10 наиболее распространенных структурах данных. Также сюда добавлены видеоролики (на английском языке) по каждой из структур, и код их реализации на JS. А чтобы вы немного попрактиковались, я добавил сюда задачи из бесплатной учебной программы freeCodeCamp.
Обратите внимание, что некоторые из этих структур данных включают временную сложность в нотации Big O. Это не относится ко всем из них, поскольку временная сложность иногда основана на реализации. Если вы хотите узнать больше о нотации Big O, посмотрите видео от Briana Marie .
Тем не менее, знание того, как реализовать эти структуры данных, даст вам огромное преимущество в поиске работы и может пригодиться, когда вы попытаетесь написать высокопроизводительный код.
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки.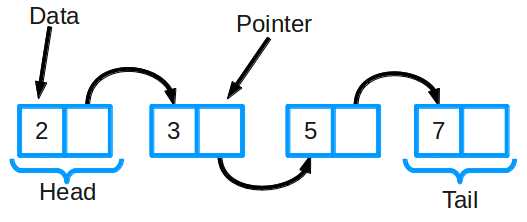
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности. Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке.
Реализация на JavaScript
Временная сложность связного списка ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
Стек — это базовая структура данных, в которой вы можете только вставлять или удалять элементы в начале стека. Он напоминает стопку книг. Если вы хотите взглянуть на книгу в середине стека, вы сначала должны взять книги, лежащие сверху.
Стек считается LIFO (Last In First Out) — это означает, что последний элемент, который добавлен в стек, — это первый элемент, который из него выходит.
Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (называемый «push»), удаление элемента из стека (называемое «pop») и отображение содержимого стека (иногда называемого «pip»).
Реализация на JavaScript
Временная сложность стека ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
Вы можете думать об этой структуре, как об очереди людей в продуктовом магазине. Стоящий первым будет обслужен первым. Также как очередь.
Если рассматривать очередь с точки доступа к данным, то она является FIFO (First In First Out). Это означает, что после добавления нового элемента все элементы, которые были добавлены до этого, должны быть удалены до того, как новый элемент будет удален.
В очереди есть только две основные операции: enqueue и dequeue. Enqueue означает вставить элемент в конец очереди, а dequeue означает удаление переднего элемента.
Реализация на JavaScript
Временная сложность очереди ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно.
- Union (Объединение). Объединяет все элементы из двух разных множеств и возвращает результат, как новый набор (без дубликатов).
- Intersection (Пересечение). Если заданы два множества, эта функция вернет другое множество, содержащее элементы, которые имеются и в первом и во втором множестве.
- Difference (Разница). Вернет список элементов, которые находятся в одном множестве, но НЕ повторяются в другом.
- Subset(Подмножество) — возвращает булево значение, показывающее, содержит ли одно множество все элементы другого множества.
Реализация на JavaScript
Задания с freeCodeCamp:
Map — это структура данных, которая хранит данные в парах ключ / значение, где каждый ключ уникален. Map иногда называется ассоциативным массивом или словарем. Она часто используется для быстрого поиска данных. Map’ы позволяют сделать следующее:
- Добавление пары в коллекцию
- Удаление пары из коллекции
- Изменение существующей пары
- Поиск значения, связанного с определенным ключом
Реализация на JavaScript
Задания с freeCodeCamp:
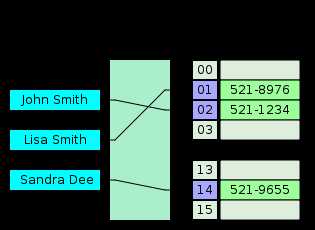
Хэш-таблица — это структура данных, реализующая интерфейс map, который позволяет хранить пары ключ / значение. Она использует хеш-функцию для вычисления индекса в массиве, по которым можно найти желаемое значение.
Поэтому, когда вы вводите пару ключ / значение в хеш-таблице, ключ проходит через хеш-функцию и превращается в число. Это числовое значение затем используется в качестве фактического ключа, в котором значение хранится. Когда вы снова попытаетесь получить доступ к тому же ключу, хеширующая функция обработает ключ и вернет тот же числовой результат. Затем число будет использовано для поиска связанного значения. Это обеспечивает очень эффективное время поиска O (1) в среднем.
Реализация на JavaScript
Временная сложность хэш-таблицы ╔═══════════╦═════════╦═══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(1) ║ O(n) ║ ║ Insert ║ O(1) ║ O(n) ║ ║ Delete ║ O(1) ║ O(n) ║ ╚═══════════╩═════════╩═══════════════╝
Задания с freeCodeCamp:

Дерево — это структура данных, состоящая из узлов. Она имеет следующие характеристики:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов и т. д.
Двоичное дерево поиска имеет + две характеристики:
- Каждый узел имеет до двух детей(потомков).
- Для каждого узла его левые потомки меньше текущего узла, что меньше, чем у правых потомков.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Способ их настройки означает, что в среднем каждое сравнение позволяет операциям пропускать половину дерева, так что каждый поиск, вставка или удаление занимает время, пропорциональное логарифму количества элементов, хранящихся в дереве.
Реализация на JavaScript
Временная сложность двоичного поиска ╔═══════════╦══════════╦══════════════╗ ║ Алгоритм ║В среднем ║Худший случай ║ ╠═══════════╬══════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(log n) ║ O(n) ║ ║ Insert ║ O(log n) ║ O(n) ║ ║ Delete ║ O(log n) ║ O(n) ║ ╚═══════════╩══════════╩══════════════╝
Задания с freeCodeCamp:
Бор, луч или дерево префикса — это своего рода дерево поиска. Оно хранит данные в шагах, каждый из которых является его узлом. Префиксное дерево из-за быстрого поиска и функции автоматического дописания часто используют для хранения слов.
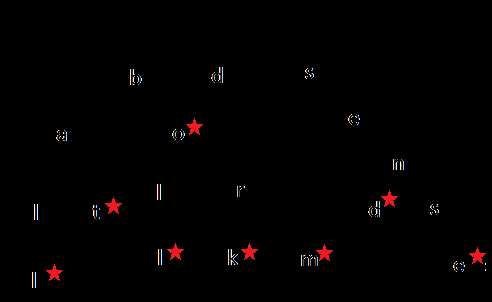
Каждый узел в префиксном дереве содержит одну букву слова. Вы следуете ветвям дерева, чтобы записать слово, по одной букве за раз. Шаги начинают расходиться, когда порядок букв отличается от других слов в дереве или, когда заканчивается слово. Каждый узел содержит букву (данные) и логическое значение, указывающее, является ли узел последним узлом в слове.
Посмотрите на изображение, и вы можете создавать слова. Всегда начинайте с корневого узла вверху и двигайтесь вниз. Показанное здесь дерево содержит слово ball, bat, doll, do, dork, dorm, send, sense.
Реализация на JavaScript
Задания с freeCodeCamp:
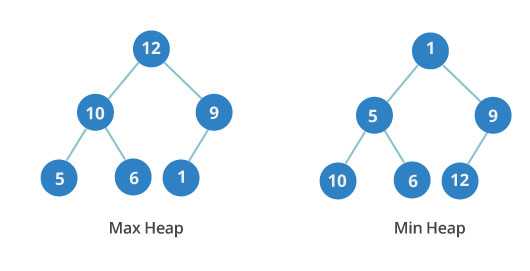
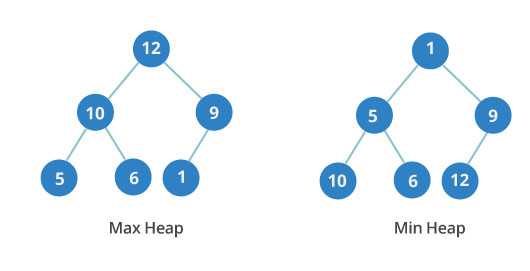
Двоичная куча — это очередное дерево, в каждом узле которого не более двух детей. Кроме того, это полное дерево. Это означает, что все уровни полностью заполнены до последнего уровня, а последний уровень заполняется слева направо.
Двоичная куча может быть либо минимальной, либо максимальной. В максимальной -ключи родительских узлов всегда больше или равны тем, что у детей. В минимальной -ключи родительских узлов меньше или равны ключам дочерних элементов.
Важен порядок между уровнями, но не узлами на одном уровне. На изображении вы можете видеть, что третий уровень минимальной кучи имеет значения 10, 6 и 12. Они расположены не по порядку.
Реализация на JavaScript
Временная сложность двоичной кучи ╔═══════════╦══════════╦═══════════════╗ ║ Алгоритм ║В среднем ║ Худший случай ║ ╠═══════════╬══════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(log n) ║ ║ Delete ║ O(log n) ║ O(log n) ║ ║ Peek ║ O(1) ║ O(1) ║ ╚═══════════╩══════════╩═══════════════╝
Задания с freeCodeCamp:
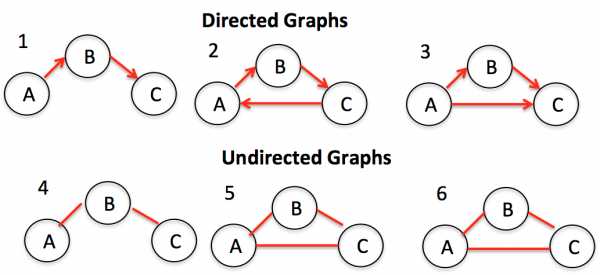
Графы представляют собой совокупности узлов (также называемых вершинами) и связей (называемых ребрами) между ними. Графы также известны как сети.
Одним из примеров графов является социальная сеть. Узлы — это люди, а ребра — дружба.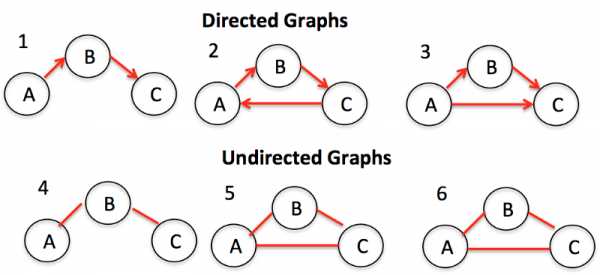
Существует два основных типа графов: ориентированные и неориентированные. Второй тип — это графы без какого-либо направления на ребрах между узлами. Ориентированные графы, напротив, представляют собой графы с направлением на них.
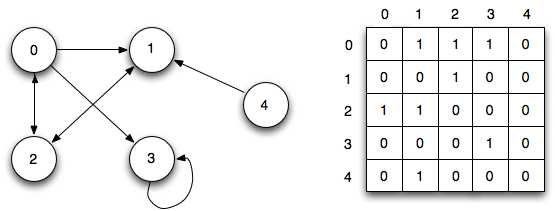
Два частых способа представления графа — это список смежности и матрица смежности.
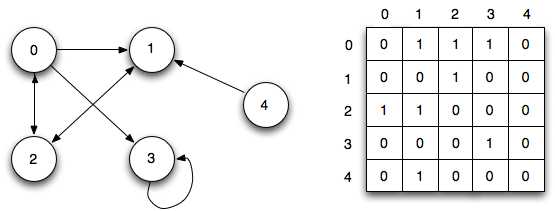
Список смежности может быть представлен как список, где левая сторона является узлом, а правая — списком всех других узлов, с которыми он соединен.
Матрица смежности представляет собой таблицу чисел, где каждая строка или столбец представляет собой другой узел на графе. На пересечении строки и столбца есть число, которое указывает на отношение. Нули означают, что нет ребер или отношений. Единицы означают, что есть отношения. Числа выше единицы могут использоваться для отображения разных весов.
Алгоритмы обхода — это алгоритмы для перемещения или посещения узлов в графе. Основными типами алгоритмов обхода являются поиск в ширину и поиск в глубину. Одно из применений заключается в определении того, насколько близко узлы расположены по отношению к корневому узлу. Посмотрите, как реализовать поиск по ширине в JavaScript в приведенном ниже видео.
Реализация на JavaScript
Временная сложность списка смежности (граф) ╔═══════════════╦════════════╗ ║ Алгоритм ║ Время ║ ╠═══════════════╬════════════╣ ║ Storage ║ O(|V|+|E|) ║ ║ Add Vertex ║ O(1) ║ ║ Add Edge ║ O(1) ║ ║ Remove Vertex ║ O(|V|+|E|) ║ ║ Remove Edge ║ O(|E|) ║ ║ Query ║ O(|V|) ║ ╚═══════════════╩════════════╝
Задания с freeCodeCamp:
Если хотите узнать больше:
Книга Grokking Algorithms — лучшая книга на эту тему, если вы новичок в структурах данных / алгоритмах и не обладаете базой компьютерных наук. Автор использует простые объяснения и юмор, рисованные иллюстрации (он является ведущим разработчиком в Etsy), чтобы объяснить некоторые структуры данных, представленные в этой статье.
proglib.io
Логическая организация баз данных
Организация данных в базе характеризуется двумя уровнями — логическом и физическом
Логическая организация базы данных определяется типом структур данных и видом модели данных, которая поддерживается СУБД.
База данных является совокупностью взаимосвязанных массивов данных.
Массив базы данных с простейшей организацией состоит из однотипных записей.
Запись является основной структурной единицей обработки данных базы. Структура записи определяется составом и последовательностью входящих в нее полей. Совокупность полей записи соответствует логически связанным реквизитам.
Реквизит – простейшая структурная единица информации предметной области, неделимая на смысловом уровне.
Структура записи простого массива является одноуровневой (линейной). Каждое поле одной записи имеет единственное значение, и отсутствуют групповые данные.
Экземпляр записи файла определяется ключом – идентификатором записей, состоящим из одного или нескольких полей.
Логическая структура базы данных (концептуальная модель) является всегда некоторой реализацией модели данных СУБД для конкретной предметной области. Такая структура определяется совокупностью объектов модели, поддерживаемой СУБД, описанием структуры каждого объекта и логических связей между объектами.
Логическая структура базы данных является в то же время отображением информационно-логической модели данных (ИЛМ) предметной области в модель, поддерживаемую СУБД. Соответственно, концептуальная модель определяется в терминах модели данных выбранной СУБД.
Физическая организация данных определяет способ размещения данных непосредственно на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства пользователя. Пользователь, как правило, оперирует в прикладных программах и универсальных программных средствах представлениями о логической организации данных.
По доступу пользователей к базе данных различают однопользовательские БД и многопользовательские.
Типовые функции обработки данных
К типовым функциям обработки данными относятся добавление, удаление, изменение, выборка данных и их обработка.
Добавление и удаление данных подразумевает добавление новых записей в массивы и удаление существующих.
Изменение данных подразумевает модификацию значений данных в полях записей.
Выборка данных подразумевает выборку записей из массивов в соответствии с заданными условиями. Выборка осуществляется средствами запросов. Причем результатом является новый массив.
Обработке могут подвергаться данные из одного массива или совместно обрабатываться взаимосвязанные данные из нескольких массивов. При этом могут, например, осуществляться расчеты в пределах каждой записи одного массива, выполняться слияние данных из разных массивов, осуществляться групповая обработка записей в соответствии с заданным критерием группировки с одновременным применением групповых функций, например суммирования в группе, определения максимальной величины, подсчета числа записей в группе и т.п.
Основные требования к базам данных
Отсутствие дублирования (избыточности) данных, обеспечивающее однократный ввод данных и, соответственно, простоту корректировки. Под дублированием данных в базе понимают повторение одних и тех же описательных, то есть неключевых данных в разных массивах (таблицах).
Например, включение адреса поставщика не только в справочник поставщиков, но и в массив поставок, в котором поставки определяется идентификаторами поставщика, поставляемого товара и датой поставки. Соответственно, в справочнике поставщиков данные о поставщике представлены однократно, а в массиве поставок они будут повторяться во всех поставках одного поставщика.
Однократность ввода данных означает, что одинаковые описательные справочные данные вводятся и корректируются однократно. Кроме того, при вводе идентификационных данных их не приходится вводить в связанные логически массивы повторно.
Целостность и непротиворечивость данных в базе – означает такое наполнение базы данными, при котором все записи из разных массивов имеют корректные логические связи с записями других массивов, в случае если такие связи определены в логической структуре БД.
Например, в БД, обладающей такими свойствами, не может сохраняться запись поставки, если в справочнике поставщиков отсутствует запись соответствующего поставщика, а в справочнике товаров отсутствует запись соответствующего товара.
Возможность многоаспектного доступа – означает, что обеспечиваются всевозможные выборки из массивов не дублированной информации и многоцелевое использование одних и тех же данных в различных задачах и приложениях пользователя.
Защита и восстановление данных при аварийных ситуациях, аппаратных и программных сбоях, ошибках пользователя,
Возможность модификации структуры базы данных без повторной загрузки данных. Т.о. база данных по мере углубления разработки может легко расширяться и модифицироваться.
studfile.net
Структуры данных логическая — Энциклопедия по машиностроению XXL
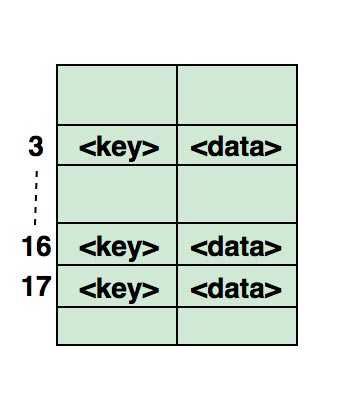
Логическая запись — единица информации, на уровне которой происходит обращение к набору данных из пользовательской программы. Размер логической записи выбирается пользователем и зависит от структуры обрабатываемых данных. Логические записи в ОС ЕС могут иметь формат 1) фиксированной длины 2) переменной длины 3) неопределенной длины. Формат логи- [c.117]Система управления БД реализует два интерфейса 1) между логическими структурами данных в программах и в БД 2) между логической и физической структурами БД. [c.97]
Следует иметь в виду, что структура данных — это совокупность правил, в соответствии с которыми элементы или группы данных связываются друг с другом. При этом структура данных как таковая не несет никаких сведений о содержательной стороне элементов данных, которая, в первую очередь, интересует проектировщиков. Вместе с тем проектировщикам необходимо иметь представление о возможных логических структурах данных, обрабатываемых ЭВМ, для того чтобы составить представление об их применимости в САПР. [c.78]
На рис. 4.6 первые две таблицы выражают отношения Изделие—узел и Узел—деталь , имеюшие место в сетевой структуре, представленной на рис. 4.5. Правая таблица является соединением зтих двух отношений. Недостатки реляционных баз данных проистекают из принципов их построения при нормализации сетевых и древовидных структур появляется избыточность информации, кроме того, многократное выполнение операций соединения таблиц приводит к увеличению затрат машинного времени на обработку запросов пользователей. Однако широкие возможности в представлении различных структур данных, а также обеспечение соответствующей СУБД полной независимости прикладного ПО от данных на логическом и физическом уровне делают реляционные базы данных в ряде случаев более предпочтительными. [c.82]
Структуры данных 78 ассоциативная 79 иерархическая 80 логическая 78 реляционная 82,102 сетевая 81 физическая 78 Схема [c.295]
Обработка данных машинной графики обычно подразумевает обработку чисел, хотя трудно найти язык, в котором не было бы обработки строк и логических выражений. Такие возможности также должны быть предусмотрены в языке. Более сложная задача — определение структуры данных. Интерактивные программы обычно работают с динамической структурой данных, которая может расширяться и сужаться во время работы программы. Язык для работы в интерактивном режиме должен иметь большой набор операций ввода — вывода и обеспечивать работу с файлами, поскольку без файлов невозможно организовать непрерывный переход от одного этапа работы к другому при выводе на экран дисплея изображений, состоящих из отдельных частей. [c.363]
Списки обеспечивают простые средства для описания динамической структуры данных. Они допускают использование компонентов разных типов например, в списке / содержатся вещественные и целые числа, логические значения и строки в следующем виде [c.366]
Логическая структура БД отрал[c.33]
Для решения новых задач в рамках имеющейся САПР или совершенствования существующих задач со временем может оказаться необходимым внесение изменений в логическую или физическую структуры данных, т. е. реорганизация БД. Это обстоятельство определяет требования к организации БД и системе управления БД. Реорганизация базы данных не должна приводить к большим стоимостно-временным затратам. [c.34]
Степень трудности задачи геометрического программирования 157 Структура базы данных логическая 33 Средства обеспечения САПР 8, 12 информационного 12, 13, 21 лингвистического 13, 14 математического 12, 14 методического 12, 13 организационного 12, 13 программного 12, 13, 82 технического 12, 13, 40 Средства программирования для графического дисплея базисные 98. 126 [c.218]
Эта группа работ начинается с определения требований конечных пользователей, анализа наличия данных, разработки структуры данных и структуры хранения данных в базе данных как на логическом, так и на физическом уровне, подготовки спецификаций на языках описания данных СУБД. Взаимодействие с конечными пользователями (выявление требований и определение наличия данных) носит нетехнический характер и входит в компетенцию АД. Например, АД может отвечать за то, чтобы пользователи выдвинули и долгосрочные (стратегические) и текущие (тактические) требования. АД должен уметь сопоставить перспективные планы предприятия с потребностями пользователей. Исходя из этого, он может разработать такую тактику, при которой система базы данных будет снабжать информацией наибольшее число пользователей и в то же время наилучшим образом служить интересам предприятия. [c.212]
Свойство системы, обеспечивающее возможность работы различных групп пользователей или приложений с собственными представлениями одних и тех же данных. В частности, разделение описаний логической структуры данных и описание приложений, структуры памяти и стратегии доступа. [c.300]
Процессоры кодирования обеспечивают настройку процессов обработки на структуру сформированной логической базы данных. [c.81]
Супервизор базы данных. Супервизор базы данных обеспечивает, отображение логической структуры данных пользователя на физическую среду хранения, осуществляет управление внешней памятью на дисках и символическое обращение к данным. [c.207]
Для хранения данных система может использовать до восьми НМД одного из трех типов СМ-5400, СМ-5407, СМ-5408. Независимо от типа и количества НМД вся внешняя память представляется как единая среда хранения. Супервизор базы данных при этом обеспечивает автоматический переход от одного накопителя к другому по мере их заполнения и полную независимость между логической структурой данных пользователя и ее физической организацией. [c.207]
База данных ЭТО совокупность файлов с прямой организацией, между которыми в соответствии с требованиями пользователя система устанавливает логические связи. Логическая структура данных представляет собой два типа файлов — основные и связующие. Доступ к данным возможен только через основные файлы. [c.239]
Каждому множеству 8 можно поставить во взаимно-однозначное соответствие сегмент некоторого информационного массива. Тогда граф Р будет описывать некоторую логическую структуру данных. По построению этот граф обладает следующими свойствами [c.55]
Произведение мощности на ширину полосы пропускания является важным параметром, используемым при разработке интегральных схем со сверхвысокой степенью интеграции. Это произведение также позволяет проводить сравнение оптоэлектронных логических матриц со всеми существующими электронными логическими матрицами. В последних подразделах данного раздела будет показано, что для фиксированных чувствительности фотодетектора, полосы частот и частоты появления ошибок произведение коэффициентов объединения по входу и разветвления по выходу для волоконно-оптической логической матрицы связано с мощностью входного сигнала. В дополнение к этому будет показано, что произведение этих коэффициентов оказывается связано с общим числом межэлементных соединений и производительностью системы. По этим причинам коэффициенты разветвления и объединения имеют критические значения. На рис. 9.4 показан пример соединения волокон встык, что позволяет реализовать высокие коэффициенты объединения по входу и разветвления по выходу либо в одном каскаде, либо в древовидной структуре. Данная методика была специально разработана для того, чтобы сделать. возможной реализацию больших волоконно-оптических логических матриц [12]. В случае необходимости разветвления волокна одиночное волокно большего диаметра служит источником, освещающим жгут волокон, имеющих маленький диаметр. Таким образом, свет от толстого волокна распределяется по всем тонким волокнам. Исходя из предположения о том, что величины угловых апертур тол- [c.245]
Необходимость взаимосвязи программ, созданных несколькими разработчиками, накладывает определенные требования на информационное обеспечение системы независимость прикладных программ от логической структуры данных и независимость логической структуры данных от физической организации памяти наличие гибких средств связи данных с прикладными программами. [c.32]
Рассмотрим применение банка данных в процессе проектирования МЭА. Можно выделить три основных этапа проектирования и в Соответствии с ними построить логическое описание структуры данных для базы МЭА. [c.203]
Система управления базой данных ИНЕС ориентирована на поддержание иерархических структур данных. На физическом уровне используется метод доступа, программно имитирующий механизм виртуальной памяти. При этом данные хранятся в блоках памяти и лексикографически упорядочены, а разным сегментам в логической схеме соответствуют различные блоки. Таким образом, блоки также организуются в иерархическую структуру. Особенность СУБД ИНЕС — наличие непроцедурного языка манипулирования данными — языка запросов. [c.84]
Для выполнения автоматизированного проектирования необходимо составить модель данных, которая включала бьт совокупность данных и их взаимосвязи, обеспечивающие решение всех предусмотренных в САПР задач. Такая модель имеет три уровня, отвечающие различным степеням абстрагирования от бесконечного многообразия реальных объектов. На первом уровне из этого многообразия выделяются только те объекты, которые необходимы для решения определенного круга задач, и формируется логическая (информационная) структура данных. На втором уровне эта структура преобразуется в физическую структуру данных, которую можно непосредственно представить в памяти ЭВМ и обработать с помощью программ. Наконец, третий уровень представляет собственно внутримашинное размещение элементов данных. [c.78]
Область хранения данных содержит записи данных для всех применений пользователя. Важно отметить, что для выполнения запросов пользователей системе не требуется обращаться к области хранения данных, так как сеть АССОЦИАТОРА содержит всю необходимую информацию в виде инвертированных списков. Средства системы ДИСОД позволяют работать с иерархическими структурами в логических записях, а возможности связи файлов делают доступным описание сетевых структур. [c.90]
При pa 4etax на ЭВМ схем, различных по структуре (рис. 3-1), задаются дополнительные логические данные, отражающие их структуру. Эти логические данные в виде восьмеричных кодов с небольшим числом разрядов определяют порядок расположения основных элементов схемы (отсеков, подогревателей), их взаимосвязь и особенности математического описания каждого элемента схемы, т. е. тип подогревателя (регенеративный, деаэратор, смешивающий и т. д.), тип отсека (дросселирование, расширение, промиерегрев и т. д.). Таким образом, для каждого элемента схемы вводится логическая информация, указывающая место расположения элемента в схеме, его особенности и т. д. [c.27]
База данных, логическая структура которой соответствует стандарту, является основой информационной интеграции автоматизированных систем, использующихся на предприятии и hjok-дающихся в информации об изделии. При этом единое представление и расположение данных позволит обеспечить полноту и целостность информации, а также избавит от возможного искажения информации. [c.24]
При организации банков данных используют различные структуры. Основными типами структур являются последовательная, списковая, древовидная, сетевая и реляционная. Для каждого типа структуры данных разработаны методы поиска информации. Последовательные структуры данных (массивы) характеризуются тем, что логический порядок элементов информации в них совпадает с физическим порядком расположения элементов. Элементами последовательной структуры данных являются зайиси. Записи организуются в массивы и характеризуются ключевым признаком. Последовательные структуры данных могут быть упорядоченными и неупорядоченными по значению ключевого признака, имя которого одинаково для всех записей. Чтобы задать последовательную структуру данных, необходимо указать адрес первой записи, длину записи и адрес последней записи. [c.268]
На стадии проектирования, физического или логического, СССД служит для запоминания описаний компонентов системы подсистем, программных модулей, структур данных, способов доступа к данным, потоков данных. Проектные спецификации содержат функциональные характеристики системы, их взаимные зависимости, а также данные, которые необходимы для работы компонентов системы. В принципе стадия проектирования логически подразделяется на две тесно взаимосвязанные части проектирование системы (разработка программ) и проектирование базы данных. [c.55]
Информационные метаобъекты представляют типы объектов данных информационных систем. На рис. 3.3 показаны пять важнейших из них. Приведенный перечень расширяют такие типы информационных метаобъектов, как транзакция, отчет, документ, экран и подсхема, служащие для описания логических представлений. При разработке программы прежде всего нужно определить элементы данных (атомарные и групповые), записи и файлы. Вхождение элементов данных в группы, групп — в- записи, а записей—в файлы изображается на диаграммах структур данных с помощью стрелок, обозначающих связи 1 п (см. разд. 2.3). Например, стрелка, направленная от группы к элементу данных, показывает, что в состав группы может входить несколько элементов (см. рис. 3.3). [c.74]
Техническое администрирование ресурсами данных в сети возложено на АБД. Он решает все те же вопросы, с которыми имеет дело АБД в централизованной системе, включая проекти рование баз данных, их создание, сопровождение и обеспечение безопасности, но с учетом особенностей распределенной сис темы. При этом АБД нуждается в поддержке со стороны СССД С ее помощью АБД может технически координировать про екты баз данных, что предотвращает появление множества несовместимых структур данных и организационных единиц и в конечном счете упрощает решение проблем преобразования данных. Он может также и контролировать процесс описания данных и структур памяти и выбрать наилучший подход к распределению данных логическую или физическую децентрализацию или и то и другое. [c.246]
| Рис. A.4. Диаграмма логических структур данных (система IDMS) |  |
Внутримашинная информационная база с логической точки зрения представляет собой конечные множества именованных элементов, каждый из которых содержит пару [39] компонент, одна из которых имя, а другая — именуемое значение. На множестве именованных элементов выделяются первичные базовые данные, которые являются основой для построения более сложных структур. Каждый из видов структуры данных характеризуется рядом свойств, существенных для эффективной организации внутрима-шинной базы. [c.7]
На концептуальном уровне и на уровне связей логический доступ к модели может осуществляться с помощью языка, ориентированного на обработку множеств. Прагматическому использованию модели способствует то, что разработан ряд методик по получению на ее основе представления реляционной модели, диаграммы структуры данных DBTGI ODASYL и модели DIAM-11. [c.25]
Теоретические работы Н. Хомского составили идейную основу концептуального , смыслового, уровня описания информации и процессов ее обработки в р/1де прикладных областей. Так, в работе [71] исследуется возможность концептуального подхода к трансформации структур данных. Развиваемый подход может быть использован для структурирования внешней схемы (следуя терминологии [56]) данных во внутреннюю, что примерно соответству-рт разработке физической организации базы данных на основе логической структуры (см. рис. 2.1 с. 33). Кроме того, идеи [71] применимы для создания программ реструктурирования физической организации данных при сохранении основного смысла процессов обработки информации (что существенно в случае изменения состава комплекса технических средств). [c.34]
При проектировании СОЭИ важно обеспечить представлеиие моделью (или их совокупностью) данных наборов взаимосвязанных экономических показателей, поскольку только на основе многоаспектного исследования системы показателей обеспечивается устойчивость проектных решений по структуре информационного и программного обеспечения. Интерпретация системы показателей необходима не только на уровне модели данных, используемой на этапе проектирования (метаинформационный уровень), но и на фазе функционирования в форме, соответствующей логической структуре данных. [c.37]
Yin построим множестви. Sf , которому соответствует одноименный сегмент в логической структуре данных [c.57]
Языки внутреннего представления. Языки внутреннего представления служат для отображений множества семантических объектов и их свойств в памяти ЭВМ. Под множеством семантических объектов в данном контексте понимается декомпозиция свойств объекта проектирования на отдельные семантические образы (объекты) и декомпозиция заданий на проектирование. Это разбиение базового множества семантических объектов входного потока на классы, обеспечивающие одпозначное отображение в памяти ЭВМ необходимых данных для процесса проектирования. В качестве языков внутреннего представления может фигурировать самая разнообразная логическая структура данных рабочие массивы, семантические таблицы, реляционные модели, построенные на основе бинарных отношений, фреймы и логические файлы [48, 49]. [c.58]
mash-xxl.info
Основные структуры данных. Матчасть. Азы / Habr
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
- Массивы
- Стеки
- Очереди
- Связанные списки
- Графы
- Деревья
- Префиксные деревья
- Хэш таблицы
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
- Insert-вставляет элемент по заданному индексу
- Get-возвращает элемент по заданному индексу
- Delete-удаление элемента по заданному индексу
- Size-получить общее количество элементов в массиве
Вопросы
- Найти второй минимальный элемент массива
- Первые неповторяющиеся целые числа в массиве
- Объединить два отсортированных массива
- Изменение порядка положительных и отрицательных значений в массиве
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
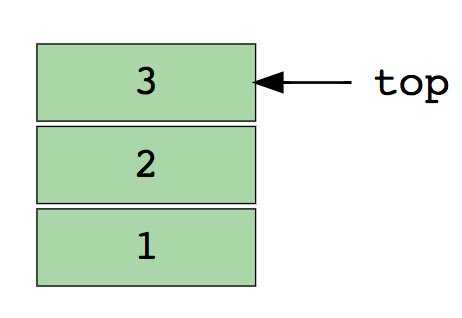
Основные операции
- Push-вставляет элемент сверху
- Pop-возвращает верхний элемент после удаления из стека
- isEmpty-возвращает true, если стек пуст
- Top-возвращает верхний элемент без удаления из стека
Вопросы
- Реализовать очередь с помощью стека
- Сортировка значений в стеке
- Реализация двух стеков в массиве
- Реверс строки с помощью стека
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
- Enqueue—) — вставляет элемент в конец очереди
- Dequeue () — удаляет элемент из начала очереди
- isEmpty () — возвращает значение true, если очередь пуста
- Top () — возвращает первый элемент очереди
Вопросы
- Реализовать cтек с помощью очереди
- Реверс первых N элементов очереди
- Генерация двоичных чисел от 1 до N с помощью очереди
Связанный список
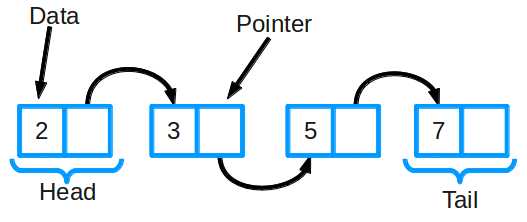
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
1->2->3->4->NULL
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
NULL<-1<->2<->3->NULL
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
1->2->3->1
Самое частое, линейный однонаправленный список. Пример – файловая система.
Основные операции
- InsertAtEnd — Вставка заданного элемента в конец списка
- InsertAtHead — Вставка элемента в начало списка
- Delete — удаляет заданный элемент из списка
- DeleteAtHead — удаляет первый элемент списка
- Search — возвращает заданный элемент из списка
- isEmpty — возвращает True, если связанный список пуст
Вопросы
- Реверс связанного списка
- Определение цикла в связанном списке
- Возврат N элемента из конца в связанном списке
- Удаление дубликатов из связанного списка
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
- Матрица смежности
- Список смежности
Общие алгоритмы обхода графа
- Поиск в ширину – обход по уровням
- Поиск в глубину – обход по вершинам
Вопросы
- Реализовать поиск по ширине и глубине
- Проверить является ли граф деревом или нет
- Посчитать количество ребер в графе
- Найти кратчайший путь между двумя вершинами
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
Простое дерево

Типы деревьев
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
- В прямом порядке (сверху вниз) — префиксная форма.
- В симметричном порядке (слева направо) — инфиксная форма.
- В обратном порядке (снизу вверх) — постфиксная форма.
Вопросы
- Найти высоту бинарного дерева
- Найти N наименьший элемент в двоичном дереве поиска
- Найти узлы на расстоянии N от корня
- Найти предков N узла в двоичном дереве
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
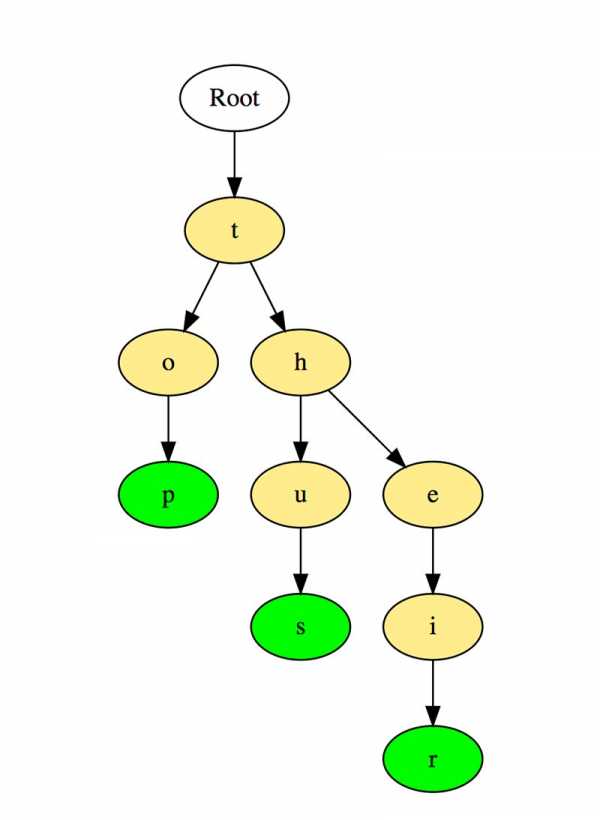
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
- Подсчитать общее количество слов
- Вывести все слова
- Сортировка элементов массива с префиксного дерева
- Создание словаря T9
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию.
Вопросы
- Найти симметричные пары в массиве
- Найти, если массив является подмножеством другого массива
- Описать открытое хеширование
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
habr.com
Определение логической структуры базы данных
Логическая структура РБД определяется совокупностью логически связанных реляционных таблиц.
Логические связи соответствуют структурным связям между объектами в инфологической модели, каждый ИО в логической структуре отображается соответствующей реляционной таблицей.
Связи между таблицами осуществляются посредством общих реквизитов (ключевых или неключевых). Логическая структура РБД имеет следующий вид:
ПРЕДПРИЯТИЯ | НАЛОГИ | |||||
Код пред. | Наим. пред | Код налога | Наим. налога | |||
Код пред. | Код налога | Сумма плана | Номер документа | Код пред. | Дата | |||
ПЛАН | ПЛАТЕЖИ | |||||||
Номер документа | Код пред. | Код налога | Сумма оплаты |
СПЕЦ-Я ПЛАТЕЖЕЙ | |||
Разработка физической структуры базы данных
Физическое моделирование БД — это способ размещения информации на машинных носителях. Правила перехода от логической реляционной структуры к физической заключаются в следующем:
каждая реляционная таблица превращается в таблицу БД;
каждый столбец таблицы — в поле таблицы;
каждая строка таблицы — в запись таблицы.
В процессе физического проектирования РБД необходимо:
Соответствие документов и таблиц бд
Имя документа | Имя таблицы БД |
Список предприятий | ПРЕДПРИЯТИЯ |
Список налогов | НАЛОГИ |
План поступления налогов | ПЛАН |
Список платежных поручений | ПЛАТЕЖИ |
СПЕЦ-Я ПЛАТЕЖЕЙ |
Таблицы базы данных заполняются на основе входных (первичных) документов. Например, в таблице ПРЕДПРИЯТИЯ имена полей КОД_ПРЕД и НАИМ_ПРЕД.
Контрольный пример
Заполнить таблицы исходными данными. Для упрощения решаемых задач сократим количество реквизитов в исходных таблицах. На основании этих данных произвести вручную расчёты для задачи 1 и задачи 2.
Контрольный пример необходим для проверки правильности решения задачи на персональном компьютере.
Следует подчеркнуть, что заполнение таблиц исходными данными в контрольной работе должно осуществляться в полном соответствии с ограничениями, допущениями и особенностями ПО.
Для нашего примера таблицы, заполненные конкретными значениями, выглядят так:
ПРЕДПРИЯТИЯ НАЛОГИ
Код пред-приятия | Наименование предприятия | Код налога | Наименование налога | |
101 | Заря | 01 | Налог на имущество | |
102 | Восток | 02 | Налог на прибыль | |
103 | Север | 03 | НДС |
ПЛАН ПЛАТЕЖИ
Код пред. | Код налога | Сумма плановая | Номер документа | Код пред. | Дата перечис-ления | |
101 | 01 | 200 | 01 | 101 | 3.02.11 | |
101 | 02 | 400 | 01 | 102 | 3.02.11 | |
102 | 01 | 150 | 02 | 101 | 5.02.11 | |
102 | 02 | 400 | 03 | 101 | 15.03.11 | |
102 | 03 | 600 | 03 | 102 | 5.03.11 | |
103 | 01 | 800 | 04 | 101 | 17.04.11 | |
103 | 02 | 200 | 04 | 103 | 10.03.11 | |
103 | 03 | 250 | 05 | 103 | 23.03.11 | |
06 | 102 | 20.04.11 |
СПЕЦИФИКАЦИЯ ПЛАТЕЖЕЙ
Номер документа | Код предприятия | Код налога | Сумма оплаты |
01 | 101 | 01 | 50 |
01 | 101 | 02 | 50 |
01 | 102 | 03 | 150 |
02 | 101 | 01 | 50 |
03 | 101 | 02 | 50 |
03 | 102 | 02 | 100 |
03 | 102 | 03 | 150 |
04 | 101 | 01 | 100 |
04 | 103 | 01 | 100 |
04 | 103 | 02 | 100 |
05 | 103 | 01 | 500 |
06 | 102 | 02 | 200 |
06 | 102 | 03 | 100 |
Примечание: данные задаются произвольно по количеству значений и содержанию с учётом ограничений.
По приведенным исходным данным выполним вручную решение поставленных задач (контрольный пример).
Задача 1. Анализ оплаты налогов по заданному предприятию.
Отберём платёжные поручения для заданного предприятия «Восток».
По отобранным платёжным поручениям вычисляем общие суммы оплаты по каждому виду налога.
Затем найдём отклонение между фактической и плановой суммой по каждому виду налога для заданного предприятия.
В результате получим:
studfile.net
10 типов структур данных, которые нужно знать + видео и упражнения
Екатерина Малахова, редактор-фрилансер, специально для блога Нетологии адаптировала статью Beau Carnes об основных типах структур данных.«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.
Структуры данных играют важную роль в процессе разработки ПО, а еще по ним часто задают вопросы на собеседованиях для разработчиков. Хорошая новость в том, что по сути они представляют собой всего лишь специальные форматы для организации и хранения данных.
В этой статье я покажу вам 10 самых распространенных структур данных. Для каждой из них приведены видео и примеры их реализации на JavaScript. Чтобы вы смогли попрактиковаться, я также добавил несколько упражнений из бета-версии новой учебной программы freeCodeCamp.
Обратите внимание, что некоторые структуры данных включают временную сложность в нотации «большого О». Это относится не ко всем из них, так как иногда временная сложность зависит от реализации. Если вы хотите узнать больше о нотации «большого О», посмотрите это видео от Briana Marie.
В статье я привожу примеры реализации этих структур данных на JavaScript: они также пригодятся, если вы используете низкоуровневый язык вроде С. В многие высокоуровневые языки, включая JavaScript, уже встроены реализации большинства структур данных, о которых пойдет речь. Тем не менее, такие знания станут серьезным преимуществом при поиске работы и пригодятся при написании высокопроизводительного кода.
Связные списки
Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка. У этих двух типов есть преимущества и недостатки.
Так устроен связный список
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке.
Основные операции в связном списке включают добавление, удаление и поиск элемента в списке.
Пример реализации на JavaScript
Временная сложность связного списка
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(1) ║
║ Delete ║ O(1) ║ O(1) ║
╚═══════════╩═════════════════╩═══════════════╝
Упражнения от freeCodeCamp
Стеки
Стек — это базовая структура данных, которая позволяет добавлять или удалять элементы только в её начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, «последним пришёл — первым вышел») . Это значит, что последний элемент, который вы добавили в стек, первым выйдет из него.

Так устроен стек
В стеках можно выполнять три операции: добавление элемента (push), удаление элемента (pop) и отображение содержимого стека (pip).
Пример реализации на JavaScript
Временная сложность стека
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(1) ║
║ Delete ║ O(1) ║ O(1) ║
╚═══════════╩═════════════════╩═══════════════╝
Упражнения от freeCodeCamp
Очереди
Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришёл в самом начале — всё как в жизни.
Так устроена очередь
Очередь устроена по принципу FIFO (First In First Out, «первый пришёл — первый вышел»). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Очередь позволяет выполнять две основных операции: добавлять элементы в конец очереди (enqueue) и удалять первый элемент (dequeue).
Пример реализации на JavaScript
Временная сложность очереди
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(1) ║
║ Delete ║ O(1) ║ O(1) ║
╚═══════════╩═════════════════╩═══════════════╝
Упражнения от freeCodeCamp
Множества
Так выглядит множество
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ещё несколько важных функций, которые можно применять к двум множествам сразу.
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов).
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах.
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом.
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества.
Пример реализации на JavaScript
Упражнения от freeCodeCamp
Map
Map — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
- добавлять пары в коллекцию;
- удалять пары из коллекции;
- изменять существующей пары;
- искать значение, связанное с определенным ключом.
Так устроена структура map
Пример реализации на JavaScript
Упражнения от freeCodeCamp
Хэш-таблицы

Так работают хэш-таблица и хэш-функция
Хэш-таблица — это похожая на Map структура, которая содержит пары ключ/значение. Она использует хэш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение.
Обычно хэш-функция принимает строку символов в качестве вводных данных и выводит числовое значение. Для одного и того же ввода хэш-функция должна возвращать одинаковое число. Если два разных ввода хэшируются с одним и тем же итогом, возникает коллизия. Цель в том, чтобы таких случаев было как можно меньше.
Таким образом, когда вы вводите пару ключ/значение в хэш-таблицу, ключ проходит через хэш-функцию и превращается в число. В дальнейшем это число используется как фактический ключ, который соответствует определенному значению. Когда вы снова введёте тот же ключ, хэш-функция обработает его и вернет такой же числовой результат. Затем этот результат будет использован для поиска связанного значения. Такой подход заметно сокращает среднее время поиска.
Пример реализации на JavaScript
Временная сложность хэш-таблицы
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(1) ║ O(n) ║
║ Insert ║ O(1) ║ O(n) ║
║ Delete ║ O(1) ║ O(n) ║
╚═══════════╩═════════════════╩═══════════════╝
Упражнения от freeCodeCamp
Двоичное дерево поиска

Двоичное дерево поиска
Дерево — это структура данных, состоящая из узлов. Ей присущи следующие свойства:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов, и так далее.
У двоичного дерева поиска есть два дополнительных свойства:
- Каждый узел имеет до двух дочерних узлов (потомков).
- Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.
Пример реализации на JavaScript
Временная сложность двоичного дерева поиска
╔═══════════╦═════════════════╦══════════════╗
║ Алгоритм ║Среднее значение ║Худший случай ║
╠═══════════╬═════════════════╬══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(log n) ║ O(n) ║
║ Insert ║ O(log n) ║ O(n) ║
║ Delete ║ O(log n) ║ O(n) ║
╚═══════════╩═════════════════╩══════════════╝
Упражнения от freeCodeCamp
Префиксное дерево
Префиксное (нагруженное) дерево — это разновидность дерева поиска. Оно хранит данные в метках, каждая из которых представляет собой узел на дереве. Такие структуры часто используют, чтобы хранить слова и выполнять быстрый поиск по ним — например, для функции автозаполнения.
Так устроено префиксное дерево
Каждый узел в языковом префиксном дереве содержит одну букву слова. Чтобы составить слово, нужно следовать по ветвям дерева, проходя по одной букве за раз. Дерево начинает ветвиться, когда порядок букв отличается от других имеющихся в нем слов или когда слово заканчивается. Каждый узел содержит букву (данные) и булево значение, которое указывает, является ли он последним в слове.
Посмотрите на иллюстрацию и попробуйте составить слова. Всегда начинайте с корневого узла вверху и спускайтесь вниз. Это дерево содержит следующие слова: ball, bat, doll, do, dork, dorm, send, sense.
Пример реализации на JavaScript
Упражнения от freeCodeCamp
Двоичная куча
Двоичная куча — ещё одна древовидная структура данных. В ней у каждого узла не более двух потомков. Также она является совершенным деревом: это значит, что в ней полностью заняты данными все уровни, а последний заполнен слева направо.
Так устроены минимальная и максимальная кучи
Двоичная куча может быть минимальной или максимальной. В максимальной куче ключ любого узла всегда больше ключей его потомков или равен им. В минимальной куче всё устроено наоборот: ключ любого узла меньше ключей его потомков или равен им.
Порядок уровней в двоичной куче важен, в отличие от порядка узлов на одном и том же уровне. На иллюстрации видно, что в минимальной куче на третьем уровне значения идут не по порядку: 10, 6 и 12.
Пример реализации на JavaScript
Временная сложность двоичной кучи
╔═══════════╦══════════════════╦═══════════════╗
║ Алгоритм ║ Среднее значение ║ Худший случай ║
╠═══════════╬══════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(log n) ║
║ Delete ║ O(log n) ║ O(log n) ║
║ Peek ║ O(1) ║ O(1) ║
╚═══════════╩══════════════════╩═══════════════╝
Упражнения от freeCodeCamp
Граф
Графы — это совокупности узлов (вершин) и связей между ними (рёбер). Также их называют сетями.
По такому принципу устроены социальные сети: узлы — это люди, а рёбра — их отношения.
Графы делятся на два основных типа: ориентированные и неориентированные. У неориентированных графов рёбра между узлами не имеют какого-либо направления, тогда как у рёбер в ориентированных графах оно есть.
Чаще всего граф изображают в каком-либо из двух видов: это может быть список смежности или матрица смежности.
Граф в виде матрицы смежности
Список смежности можно представить как перечень элементов, где слева находится один узел, а справа — все остальные узлы, с которыми он соединяется.
Матрица смежности — это сетка с числами, где каждый ряд или колонка соответствуют отдельному узлу в графе. На пересечении ряда и колонки находится число, которое указывает на наличие связи. Нули означают, что она отсутствует; единицы — что связь есть. Чтобы обозначить вес каждой связи, используют числа больше единицы.
Существуют специальные алгоритмы для просмотра рёбер и вершин в графах — так называемые алгоритмы обхода. К их основным типам относят поиск в ширину (breadth-first search) и в глубину (depth-first search). Как вариант, с их помощью можно определить, насколько близко к корневому узлу находятся те или иные вершины графа. В видео ниже показано, как на JavaScript выполнить поиск в ширину.
Пример реализации на JavaScript
Временная сложность списка смежности (графа)
╔═══════════════╦════════════╗
║ Алгоритм ║ Время ║
╠═══════════════╬════════════╣
║ Storage ║ O(|V|+|E|) ║
║ Add Vertex ║ O(1) ║
║ Add Edge ║ O(1) ║
║ Remove Vertex ║ O(|V|+|E|) ║
║ Remove Edge ║ O(|E|) ║
║ Query ║ O(|V|) ║
╚═══════════════╩════════════╝
Упражнения от freeCodeCamp
Узнать больше
Если до этого вы никогда не сталкивались с алгоритмами или структурами данных, и у вас нет какой-либо подготовки в области ИТ, лучше всего подойдет книга Grokking Algorithms. В ней материал подан доступно и с забавными иллюстрациями (их автор — ведущий разработчик в Etsy), в том числе и по некоторым структурам данных, которые мы рассмотрели в этой статье.
От редакции Нетологии
Нетология проводит набор на курсы по Big Data:
1. Программа «Big Data: основы работы с большими массивами данных»
Для кого: инженеры, программисты, аналитики, маркетологи — все, кто только начинает вникать в технологию Big Data.
- введение в историю и основы технологии;
- способы сбора больших данных;
- типы данных;
- основные и продвинутые методы анализа больших данных;
- основы программирования, архитектуры хранения и обработки для работы с большими массивами данных.
Формат занятий: онлайн.
Подробности по ссылке → http://netolo.gy/dJd
2. Программа «Data Scientist»
Для кого: специалисты, работающие или собирающиеся работать с Big Data, а также те, кто планирует построить карьеру в области Data Science. Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Темы курса:
- экспресс-обучение основным инструментам, Hadoop, кластерные вычисления;
- деревья решений, метод k-ближайших соседей, логистическая регрессия, кластеризация;
- уменьшение размерности данных, методы декомпозиции, спрямляющие пространства;
- введение в рекомендательные системы;
- распознавание изображений, машинное зрение, нейросети;
- обработка текста, дистрибутивная семантика, чатботы;
- временные ряды, модели ARMA/ARIMA, сложные модели прогнозирования.
Формат занятий: офлайн, г. Москва, центр Digital October. Преподают специалисты из Yandex Data Factory, Ростелеком, «Сбербанк-Технологии», Microsoft, OWOX, Clever DATA, МТС.
Подробности по ссылке.
habr.com