
Основные структуры данных. Матчасть. Азы / Хабр
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.
В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Пример: граф и деревья.
Основные структуры данных.
- Массивы
- Стеки
- Очереди
- Связанные списки
- Графы
- Деревья
- Префиксные деревья
- Хэш таблицы
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
- Insert-вставляет элемент по заданному индексу
- Get-возвращает элемент по заданному индексу
- Delete-удаление элемента по заданному индексу
- Size-получить общее количество элементов в массиве
Вопросы
- Найти второй минимальный элемент массива
- Первые неповторяющиеся целые числа в массиве
- Объединить два отсортированных массива
- Изменение порядка положительных и отрицательных значений в массиве
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ.
 last in — first out, «последним пришёл — первым вышел»).
last in — first out, «последним пришёл — первым вышел»).Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
Основные операции
- Push-вставляет элемент сверху
- Pop-возвращает верхний элемент после удаления из стека
- isEmpty-возвращает true, если стек пуст
- Top-возвращает верхний элемент без удаления из стека
Вопросы
- Реализовать очередь с помощью стека
- Сортировка значений в стеке
- Реализация двух стеков в массиве
- Реверс строки с помощью стека
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом.
 Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым
Основные операции
- Enqueue—) — вставляет элемент в конец очереди
- Dequeue () — удаляет элемент из начала очереди
- isEmpty () — возвращает значение true, если очередь пуста
- Top () — возвращает первый элемент очереди
Вопросы
- Реализовать cтек с помощью очереди
- Реверс первых N элементов очереди
- Генерация двоичных чисел от 1 до N с помощью очереди
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
1->2->3->4->NULL
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
NULL<-1<->2<->3->NULL
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
1->2->3->1
Самое частое, линейный однонаправленный список. Пример – файловая система.
Основные операции
- InsertAtEnd — Вставка заданного элемента в конец списка
- InsertAtHead — Вставка элемента в начало списка
- Delete — удаляет заданный элемент из списка
- DeleteAtHead — удаляет первый элемент списка
- Search — возвращает заданный элемент из списка
- isEmpty — возвращает True, если связанный список пуст
Вопросы
- Реверс связанного списка
- Определение цикла в связанном списке
- Возврат N элемента из конца в связанном списке
- Удаление дубликатов из связанного списка
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
- Матрица смежности
- Список смежности
Общие алгоритмы обхода графа
- Поиск в ширину – обход по уровням
- Поиск в глубину – обход по вершинам
Вопросы
- Реализовать поиск по ширине и глубине
- Проверить является ли граф деревом или нет
- Посчитать количество ребер в графе
- Найти кратчайший путь между двумя вершинами
Деревья
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
Простое дерево
Типы деревьев
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
- В прямом порядке (сверху вниз) — префиксная форма.
- В симметричном порядке (слева направо) — инфиксная форма.
- В обратном порядке (снизу вверх) — постфиксная форма.
Вопросы
- Найти высоту бинарного дерева
- Найти N наименьший элемент в двоичном дереве поиска
- Найти узлы на расстоянии N от корня
- Найти предков N узла в двоичном дереве
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
- Подсчитать общее количество слов
- Вывести все слова
- Сортировка элементов массива с префиксного дерева
- Создание словаря T9
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию.
Вопросы
- Найти симметричные пары в массиве
- Найти, если массив является подмножеством другого массива
- Описать открытое хеширование
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки.
 Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
10 типов структур данных, которые нужно знать + видео и упражнения
Екатерина Малахова, редактор-фрилансер, специально для блога Нетологии адаптировала статью Beau Carnes об основных типах структур данных.«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.
Структуры данных играют важную роль в процессе разработки ПО, а еще по ним часто задают вопросы на собеседованиях для разработчиков. Хорошая новость в том, что по сути они представляют собой всего лишь специальные форматы для организации и хранения данных.
В этой статье я покажу вам 10 самых распространенных структур данных. Для каждой из них приведены видео и примеры их реализации на JavaScript. Чтобы вы смогли попрактиковаться, я также добавил несколько упражнений из бета-версии новой учебной программы freeCodeCamp.
Для каждой из них приведены видео и примеры их реализации на JavaScript. Чтобы вы смогли попрактиковаться, я также добавил несколько упражнений из бета-версии новой учебной программы freeCodeCamp.
Обратите внимание, что некоторые структуры данных включают временную сложность в нотации «большого О». Это относится не ко всем из них, так как иногда временная сложность зависит от реализации. Если вы хотите узнать больше о нотации «большого О», посмотрите это видео от Briana Marie.
В статье я привожу примеры реализации этих структур данных на JavaScript: они также пригодятся, если вы используете низкоуровневый язык вроде С. В многие высокоуровневые языки, включая JavaScript, уже встроены реализации большинства структур данных, о которых пойдет речь. Тем не менее, такие знания станут серьезным преимуществом при поиске работы и пригодятся при написании высокопроизводительного кода.
Связные списки
Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка.
 У этих двух типов есть преимущества и недостатки.
У этих двух типов есть преимущества и недостатки.
Так устроен связный список
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке.
Основные операции в связном списке включают добавление, удаление и поиск элемента в списке.
Пример реализации на JavaScript
Временная сложность связного списка
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(1) ║
║ Delete ║ O(1) ║ O(1) ║
╚═══════════╩═════════════════╩═══════════════╝
 youtube.com/embed/9YddVVsdG5A?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
youtube.com/embed/9YddVVsdG5A?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
Упражнения от freeCodeCamp
Стеки
Стек — это базовая структура данных, которая позволяет добавлять или удалять элементы только в её начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, «последним пришёл — первым вышел») . Это значит, что последний элемент, который вы добавили в стек, первым выйдет из него.
Так устроен стек
В стеках можно выполнять три операции: добавление элемента (push), удаление элемента (pop) и отображение содержимого стека (pip).
Пример реализации на JavaScript
Временная сложность стека
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(1) ║
║ Delete ║ O(1) ║ O(1) ║
╚═══════════╩═════════════════╩═══════════════╝
 youtube.com/embed/Gj5qBheGOEo?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
youtube.com/embed/Gj5qBheGOEo?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
Упражнения от freeCodeCamp
Очереди
Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришёл в самом начале — всё как в жизни.
Так устроена очередь
Очередь устроена по принципу FIFO (First In First Out, «первый пришёл — первый вышел»). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Очередь позволяет выполнять две основных операции: добавлять элементы в конец очереди (enqueue) и удалять первый элемент (dequeue).
Пример реализации на JavaScript
Временная сложность очереди
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(1) ║
║ Delete ║ O(1) ║ O(1) ║
╚═══════════╩═════════════════╩═══════════════╝
 youtube.com/embed/bK7I79hcm08?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
youtube.com/embed/bK7I79hcm08?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
Упражнения от freeCodeCamp
Множества
Так выглядит множество
Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть ещё несколько важных функций, которые можно применять к двум множествам сразу.
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов).
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах.
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом.
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества.
Пример реализации на JavaScript
 com/embed/wl8u02IdVxo?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
com/embed/wl8u02IdVxo?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
Упражнения от freeCodeCamp
Map
Map — это структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда её также называют ассоциативным массивом или словарём. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
- добавлять пары в коллекцию;
- удалять пары из коллекции;
- изменять существующей пары;
- искать значение, связанное с определенным ключом.
Так устроена структура map
Пример реализации на JavaScript
Упражнения от freeCodeCamp
Хэш-таблицы
Так работают хэш-таблица и хэш-функция
Хэш-таблица — это похожая на Map структура, которая содержит пары ключ/значение. Она использует хэш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение.
Она использует хэш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение.
Обычно хэш-функция принимает строку символов в качестве вводных данных и выводит числовое значение. Для одного и того же ввода хэш-функция должна возвращать одинаковое число. Если два разных ввода хэшируются с одним и тем же итогом, возникает коллизия. Цель в том, чтобы таких случаев было как можно меньше.
Таким образом, когда вы вводите пару ключ/значение в хэш-таблицу, ключ проходит через хэш-функцию и превращается в число. В дальнейшем это число используется как фактический ключ, который соответствует определенному значению. Когда вы снова введёте тот же ключ, хэш-функция обработает его и вернет такой же числовой результат. Затем этот результат будет использован для поиска связанного значения. Такой подход заметно сокращает среднее время поиска.
Пример реализации на JavaScript
Временная сложность хэш-таблицы
╔═══════════╦═════════════════╦═══════════════╗
║ Алгоритм ║Среднее значение ║ Худший случай ║
╠═══════════╬═════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(1) ║ O(n) ║
║ Insert ║ O(1) ║ O(n) ║
║ Delete ║ O(1) ║ O(n) ║
╚═══════════╩═════════════════╩═══════════════╝
 youtube.com/embed/F95z5Wxd9ks?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
youtube.com/embed/F95z5Wxd9ks?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
Упражнения от freeCodeCamp
Двоичное дерево поиска
Двоичное дерево поиска
Дерево — это структура данных, состоящая из узлов. Ей присущи следующие свойства:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов, и так далее.
У двоичного дерева поиска есть два дополнительных свойства:
- Каждый узел имеет до двух дочерних узлов (потомков).
- Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.
Пример реализации на JavaScript
Временная сложность двоичного дерева поиска
╔═══════════╦═════════════════╦══════════════╗
║ Алгоритм ║Среднее значение ║Худший случай ║
╠═══════════╬═════════════════╬══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(log n) ║ O(n) ║
║ Insert ║ O(log n) ║ O(n) ║
║ Delete ║ O(log n) ║ O(n) ║
╚═══════════╩═════════════════╩══════════════╝
 youtube.com/embed/5cU1ILGy6dM?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
youtube.com/embed/5cU1ILGy6dM?rel=0&showinfo=1″ allowfullscreen=»» scrolling=»no»/>
Упражнения от freeCodeCamp
Префиксное дерево
Префиксное (нагруженное) дерево — это разновидность дерева поиска. Оно хранит данные в метках, каждая из которых представляет собой узел на дереве. Такие структуры часто используют, чтобы хранить слова и выполнять быстрый поиск по ним — например, для функции автозаполнения.
Так устроено префиксное дерево
Каждый узел в языковом префиксном дереве содержит одну букву слова. Чтобы составить слово, нужно следовать по ветвям дерева, проходя по одной букве за раз. Дерево начинает ветвиться, когда порядок букв отличается от других имеющихся в нем слов или когда слово заканчивается. Каждый узел содержит букву (данные) и булево значение, которое указывает, является ли он последним в слове.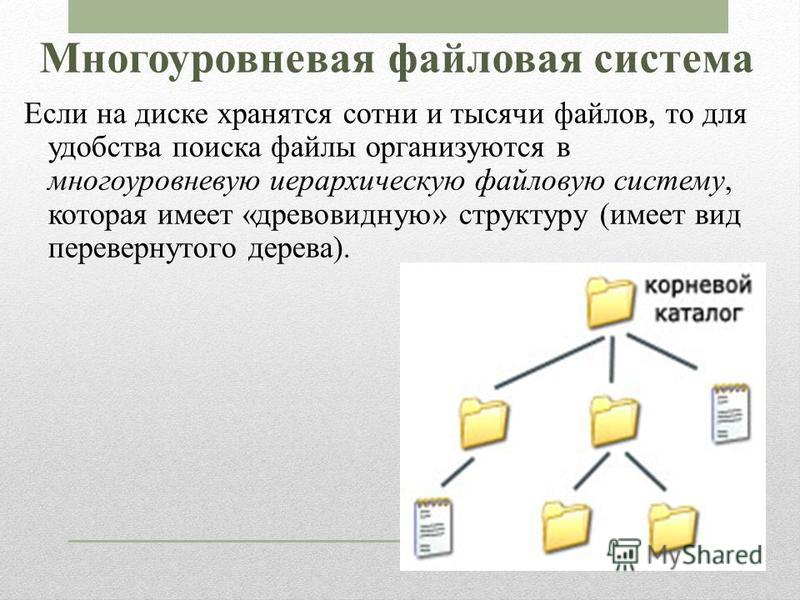
Посмотрите на иллюстрацию и попробуйте составить слова. Всегда начинайте с корневого узла вверху и спускайтесь вниз. Это дерево содержит следующие слова: ball, bat, doll, do, dork, dorm, send, sense.
Пример реализации на JavaScript
Упражнения от freeCodeCamp
Двоичная куча
Двоичная куча — ещё одна древовидная структура данных. В ней у каждого узла не более двух потомков. Также она является совершенным деревом: это значит, что в ней полностью заняты данными все уровни, а последний заполнен слева направо.
Так устроены минимальная и максимальная кучи
Двоичная куча может быть минимальной или максимальной. В максимальной куче ключ любого узла всегда больше ключей его потомков или равен им. В минимальной куче всё устроено наоборот: ключ любого узла меньше ключей его потомков или равен им.
Порядок уровней в двоичной куче важен, в отличие от порядка узлов на одном и том же уровне. На иллюстрации видно, что в минимальной куче на третьем уровне значения идут не по порядку: 10, 6 и 12.
На иллюстрации видно, что в минимальной куче на третьем уровне значения идут не по порядку: 10, 6 и 12.
Пример реализации на JavaScript
Временная сложность двоичной кучи
╔═══════════╦══════════════════╦═══════════════╗
║ Алгоритм ║ Среднее значение ║ Худший случай ║
╠═══════════╬══════════════════╬═══════════════╣
║ Space ║ O(n) ║ O(n) ║
║ Search ║ O(n) ║ O(n) ║
║ Insert ║ O(1) ║ O(log n) ║
║ Delete ║ O(log n) ║ O(log n) ║
║ Peek ║ O(1) ║ O(1) ║
╚═══════════╩══════════════════╩═══════════════╝
Упражнения от freeCodeCamp
Граф
Графы — это совокупности узлов (вершин) и связей между ними (рёбер). Также их называют сетями.
По такому принципу устроены социальные сети: узлы — это люди, а рёбра — их отношения.
Графы делятся на два основных типа: ориентированные и неориентированные. У неориентированных графов рёбра между узлами не имеют какого-либо направления, тогда как у рёбер в ориентированных графах оно есть.
Чаще всего граф изображают в каком-либо из двух видов: это может быть список смежности или матрица смежности.
Граф в виде матрицы смежности
Список смежности можно представить как перечень элементов, где слева находится один узел, а справа — все остальные узлы, с которыми он соединяется.
Матрица смежности — это сетка с числами, где каждый ряд или колонка соответствуют отдельному узлу в графе. На пересечении ряда и колонки находится число, которое указывает на наличие связи. Нули означают, что она отсутствует; единицы — что связь есть. Чтобы обозначить вес каждой связи, используют числа больше единицы.
Существуют специальные алгоритмы для просмотра рёбер и вершин в графах — так называемые алгоритмы обхода. К их основным типам относят поиск в ширину (breadth-first search) и в глубину (depth-first search). Как вариант, с их помощью можно определить, насколько близко к корневому узлу находятся те или иные вершины графа. В видео ниже показано, как на JavaScript выполнить поиск в ширину.
Как вариант, с их помощью можно определить, насколько близко к корневому узлу находятся те или иные вершины графа. В видео ниже показано, как на JavaScript выполнить поиск в ширину.
Пример реализации на JavaScript
Временная сложность списка смежности (графа)
╔═══════════════╦════════════╗
║ Алгоритм ║ Время ║
╠═══════════════╬════════════╣
║ Storage ║ O(|V|+|E|) ║
║ Add Vertex ║ O(1) ║
║ Add Edge ║ O(1) ║
║ Remove Vertex ║ O(|V|+|E|) ║
║ Remove Edge ║ O(|E|) ║
║ Query ║ O(|V|) ║
╚═══════════════╩════════════╝
Упражнения от freeCodeCamp
Узнать больше
Если до этого вы никогда не сталкивались с алгоритмами или структурами данных, и у вас нет какой-либо подготовки в области ИТ, лучше всего подойдет книга Grokking Algorithms.
 В ней материал подан доступно и с забавными иллюстрациями (их автор — ведущий разработчик в Etsy), в том числе и по некоторым структурам данных, которые мы рассмотрели в этой статье.
В ней материал подан доступно и с забавными иллюстрациями (их автор — ведущий разработчик в Etsy), в том числе и по некоторым структурам данных, которые мы рассмотрели в этой статье.От редакции Нетологии
Нетология проводит набор на курсы по Big Data:
1. Программа «Big Data: основы работы с большими массивами данных»
Для кого: инженеры, программисты, аналитики, маркетологи — все, кто только начинает вникать в технологию Big Data.
- введение в историю и основы технологии;
- способы сбора больших данных;
- типы данных;
- основные и продвинутые методы анализа больших данных;
- основы программирования, архитектуры хранения и обработки для работы с большими массивами данных.
Формат занятий: онлайн.
Подробности по ссылке → http://netolo.gy/dJd
2. Программа «Data Scientist»
Для кого: специалисты, работающие или собирающиеся работать с Big Data, а также те, кто планирует построить карьеру в области Data Science. Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Темы курса:
- экспресс-обучение основным инструментам, Hadoop, кластерные вычисления;
- деревья решений, метод k-ближайших соседей, логистическая регрессия, кластеризация;
- уменьшение размерности данных, методы декомпозиции, спрямляющие пространства;
- введение в рекомендательные системы;
- распознавание изображений, машинное зрение, нейросети;
- обработка текста, дистрибутивная семантика, чатботы;
- временные ряды, модели ARMA/ARIMA, сложные модели прогнозирования.
Формат занятий: офлайн, г. Москва, центр Digital October. Преподают специалисты из Yandex Data Factory, Ростелеком, «Сбербанк-Технологии», Microsoft, OWOX, Clever DATA, МТС.
Подробности по ссылке.
5. Блочный поиск
Снова
вспомним пример с записной книжкой. Пусть в вашей записной книжке имеется
алфавитный индекс в виде вырезанной
«лесенки» или в виде букв вверху
страницы. Несколько страниц, помеченных
одной буквой, назовем блоком. Имеется
блок «А», блок «Б» и т. д. до блока «Я».
Пусть в вашей записной книжке имеется
алфавитный индекс в виде вырезанной
«лесенки» или в виде букв вверху
страницы. Несколько страниц, помеченных
одной буквой, назовем блоком. Имеется
блок «А», блок «Б» и т. д. до блока «Я».
Индекс — это часть ключа поиска (например, первая буква).
Записи телефонов и адресов расставлялись в записной книжке по блокам в соответствии с первой буквой. Однако внутри блока записи не упорядочены в алфавитном порядке следующих букв, как это делается в словарях и энциклопедиях. Записи в книжке мы ведем в порядке поступления. При такой организации данных поиск нужного телефона будет происходить блочно-последовательным методом:
1) с помощью алфавитного индекса выбирается блок с нужной буквой;
2)
внутри
блока поиск производится путем
последовательного перебора. Большинство
книг в начале или в конце текста содержат
оглавления:
список
названий разделов с указанием страниц,
с которых они начинаются. Разделы –
это те же блоки. Поиск нужной информации
в книге начинается с просмотра
оглавления, с дальнейшим переходом к
нужному разделу, который затем
просматривается последовательно.
Очевидно, это тот же блочно-последовательный
метод поиска.
Разделы –
это те же блоки. Поиск нужной информации
в книге начинается с просмотра
оглавления, с дальнейшим переходом к
нужному разделу, который затем
просматривается последовательно.
Очевидно, это тот же блочно-последовательный
метод поиска.
Списки с указанием на блоки данных называются списками указателей.
Разбиение данных на блоки может быть многоуровневым. В толстых словарях блок на букву «А» разбивается, например, на блоки по второй букве: блок от «АБ» до «АЖ», следующий от «АЗ» до «АН» и т. д. Такой порядок называется лексикографическим.
В
поисковом множестве с многоуровневой
блочной структурой происходит поиск
методом спуска: сначала отыскивается
нужный блок первого уровня, затем второго
и т. д. Внутри блока последнего уровня
может происходить либо последовательный
поиск (если данных в нем относительно
немного), либо оптимизированный поиск
типа половинного деления. Поиску
методом спуска часто помогают многоуровневые
списки указателей.
6. Поиск в иерархической структуре данных.
Многоуровневые блочные структуры хранения данных называются иерархическими структурами. По такому принципу организовано хранение файлов в файловой системе компьютера. То, что мы называли выше блоками, в файловой системе называется каталогами пли папками, а графическое изображение структуры блоков-папок называется деревом каталогов. Пример отображения на экране компьютера дерева каталогов показан на следующем рисунке. Чтобы найти файл, нужно знать путь к файлу по дереву каталогов. Операционная система поможет найти напрашиваемый вами файл по команде Поиск. Результат поиска представляется в виде пути к файлу, начиная от корневого каталога последовательно по уровням дерева до каталога (папки), непосредственно содержавшего ваш файл. Например, при поиске файла с именем kе.ехе будет выдан следующий ответ: E:\GAME\GAMES\ARCON\ke.exe
Здесь указан полный путь к файлу на логическом диске Е: от корневого каталога до самого файла. Имея такую подсказку, вы легко отыщете нужный файл на диске методом спуска по дереву каталогов. Каталог иерархической структуры файловой системы компьютера является многоуровневым списком указателей. (слайд 10)
1.5.8. Структуры данных
Автоматизированная обработка больших объемов данных становится проще, если данные упорядочены (структурированы). Применяются следующие структуры данных:
Линейная структураданных (список) – это упорядоченная структура, в которой адрес данного однозначно определяется его номером (индексом). Пример: список учебной группы, дома, стоящие на одной улице.
В списках, как известно, новый элемент начинается с новой строки. Если элементы располагаются в строчку, то вводится разделительный знак между элементами. Поиск осуществляется по разделителям (например, чтобы найти десятый элемент, надо отсчитать девять разделителей).
Если элементы списка одной длины, структура называется вектором данных, разделители не требуются. При длине одного элемента d, зная номер элементаn, его начало определяется соотношениемd(n-1).
Табличная структураданных – это упорядоченная структура, в которой адрес данного однозначно определяется двумя числами – номером строки и номером столбца, на пересечении которых находится ячейка с исходным элементом.
Если элементы располагаются в строчку, вводятся два разделительных знака – между элементами строки и между строками. Поиск, аналогично линейной структуре осуществляется по разделителям.
Если элементы таблицы одной длины, структура называется матрицейданных, разделители в ней не требуются. При длине одного элементаd, зная номер строкиmи номер столбцаn, а также строк и столбцовM,N, найдем адрес его начала:
d[N(m – 1) + (n – 1)].
Таблица может быть трехмерной, тогда три числа характеризуют положение элемента, а может быть n– мерной.
Мой компьютер
Диск С: ДискD: ДискH:
Program files Папка 1 Папка 2 …
MS OfficeСтандартные …
MS Word MS Excel …
Иерархическая структура– это структура, в которой адрес каждого элемента определяется путем (маршрутом доступа), идущим от вершины структуры к данному элементу. Иерархическую структуру образуют, например, почтовые адреса, файловая система компьютера:
Линейная и табличная структуры более просты, чем иерархическая , но, если в линейной структуре появляется новый элемент, то упорядоченность сбивается. Например, если в списке студентов появляется новый человек, расположенный по алфавиту список нарушается.
В иерархической структуре введение нового элемента не нарушает структуры дерева. Недостатком является трудоемкость записи адреса и сложность упорядочивания.
H:\Stud\tsi11\Ivanov\Text\my_file.doc
Россия \ Ростовская область \ Ростов – на – Дону \ ул. Б. Садовая \дом 1\кв. 11
1.5.9. Хранение данных
При хранении данных решаются две задачи:
В компьютерных технологиях единицей хранения данных является объект переменной длины, называемый файлом. Файл – это поименованная область на внешнем носителе, содержащая данные определенной длины, обладающая собственным именем.
Современные файлы могут содержать данные различных типов. Например, в текстовом файле могут содержаться графические вставки, таблицы и пр.
Имя файла фактически несет в себе адресные функции в иерархических структурах. Имя файла может иметь расширение, в котором хранятся сведения о типе данных. При автоматической обработке по типу файла может запускаться приложение (программа), работающее с ним.
Для доступа к файлам, которых на жестком диске может быть сотни тысяч, используется определенное ПО, предназначенное для централизованного управления данными.
Системы управления данными называются файловыми системами. Именно файловая система решает задачи распределения внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным. Благодаря этому, работа с файлами во многом стала напоминать работу с обычными документами.
Информация любого типа хранится в виде файлов, выступающих в роли логически завершенных совокупностей данных.
Для пользователя файл является основным и неделимым элементом хранения данных, который можно найти, изменить, удалить, сохранить или переслать, но только целиком. С физической точки зрения, файл – это всего лишь последовательность байтов. Способ использования или отображения этой последовательности определяется типом файла – текстовый, звуковой, исполняемый модуль программы и т.п.
Для хранения различных видов информации необходимо использовать по-разному устроенные файлы. Способ организации данных (структура файла) называется форматом.
Файловая система – это часть ОС компьютера и поэтому всегда несет на себе отпечаток свойств конкретной ОС. Некоторые форматы файлов стандартизированы и должны поддерживаться любой ОС и работающими в ней приложениями (например, графические файлы .GIFилиJPEG). Наряду с этим всегда имеются форматы, специфичные только для данной системы (например, исполняемые файлыMSDOSилиWindows). Есть форматы, разработанные для конкретных приложений, работающих под управлением данной ОС (например, формат .xls, используемыйMSExcel). В некоторых случаях при разработке приложений программистам приходится создавать новые форматы.
Структура файла может быть простой. Например, текст может сохраняться в виде последовательности байтов, прямо соответствующих формату ASCII. Но в большинстве случаев вместе с данными приходится сохранять и дополнительную информацию. Например, особенности форматирования текста (размеры символов, шрифты и т.п.). Процесс форматирования можно рассматривать, как процедуру придания некоторых свойств фрагменту текста. Поэтому, для сохранения форматирования нужно иметь два типа кодов, для обозначения блока текста, к которому применяется форматирование, и для указания свойства (типа форматирования).
Если система служебных кодов определена, то для сохранения текста требуется вставка в него управляющих символов. Например, надо сохранить таблицу из шести чисел, имеющую две строки и три столбца (2 х 3):
Для хранения чисел используются ячейки фиксированного размера (например, два байта). Поэтому, если в файл записано 6 чисел, то при чтении данных из него нужно извлечь шесть раз по 2 байта. Т.к. память ПК линейна, то возникает задача, как сохранить не только сами числа, но и структуру таблицы. Очевидно, что если таблица запоминается построчно, то основным параметром, определяемым ее вид, является количество чисел в строке (т.е. количество столбцов). Поэтому, договариваемся, что первое число в файле – это длина строки таблицы, затем записывается количество строк, а далее построчно сохраняются числовые элементы таблицы. Тип данных, представляющий их, также должен быть оговорен. Число строк необходимо запомнить, чтобы знать, где остановиться при чтении информации. Таблица может быть записана в файл в виде следующей последовательности:
Сформулированными правилами должна будет пользоваться не только программа, сохраняющая таблицу, но и любая другая, которой потребуется прочесть данные из таблицы, т.к. формат файла определяет способ правильной интерпретации хранимых данных. Размещение в начале файла блока служебной информации часто используется в многочисленных форматах, например, в файлах баз данных или графических данных.
Заголовок (служебная информация) | Собственно сохраняемые данные |
Часто заголовок файла включает идентификатор формата файла. Программы, предназначенные для просмотра файлов определенного типа, начинают работу с чтения служебной информации и проверки возможности восприятия формата файла.
Современные программные системы позволяют одновременно включать в файл данные разных видов, а это требует разработки очень сложных форматов. Придумать простой формат, который позволил бы хранить множество видов данных вместе, невозможно. Поэтому, например, для хранения документов в MSOfficeстроятся так называемые структурированные хранилища – фактически файловые системы, спрятанные в одном файле. Наличие разных форматов для хранения данных одного и того же типа затрудняет переносимость их из среды одного приложения (программы) в среду другого. Проблема обычно решается использованием специальных программ, называемыхконверторами.
Вопросы для самоконтроля
Как представляются числа в памяти компьютера?
Как представляются символьные и текстовые данные?
Как представляются звуковые данные?
Как представляются графические данные?
Какими способами формируются графические изображения?
Что вы можете рассказать о моделях RGBиCMYK?
Что вы можете сказать об особенностях хранения данных различных типов?
12 Файловые структуры » СтудИзба
1. Файловые структуры, используемые для хранения информации в БД.
В каждой СУБД по-разному организованы хранение и доступ к данным, однако, существуют некоторые файловые структуры, которые имеют общепринятые способы организации и широко применяются практически во всех системах БД. Файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать следующим образом:
С точки зрения пользователя файл – поименованная линейная последовательность записей, расположенных на внешних носителях. Так как файл линейная последовательность записей, то всегда можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла. В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией и устройства с последовательной адресацией. На устройствах с произвольной адресацией возможна установка головок чтения-записи в произвольное место мгновенно. Практически существует время позиционирования головки, которое мало по сравнению со временем считывания записи.
2. Файлы прямого и последовательного доступа
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа, называются файлами прямого доступа. В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи.
Каждая файловая система – система управления файлами поддерживает некоторую иерархическую файловую структуру, включающую чаще всего неограниченное количество уровней иерархии в представлении внешней памяти.
Для каждого файла в системе хранится следующая информация:
· имя файла;
· тип файла, размер записи, количество занятых физических блоков;
· базовый начальный адрес;
· ссылка на сегмент расширения;
· способ доступа (код защиты).
Для файлов с постоянной длиной записи адрес размещения записи с номером К может быть вычислен по формуле:
К=ВА+(К-1)*LZ+1,
где ВА – базовый адрес, LZ-длина записи.
Поскольку всегда можно определить адрес, на который необходимо позиционировать механизм считывания-записи, то устройства прямого доступа делают это практически мгновенно, поэтому для таких файлов чтение произвольной записи практически не зависит от ее номера. Файлы прямого доступа обеспечивают наиболее быстрый доступ к произвольным записям, и их использование считается наиболее перспективным в системах БД.
Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Они могут быть организованы двумя способами:
Конец записи отмечается специальным маркером.
Запись 1 | * | Запись 2 | * | Запись 3 | * |
В начале каждой записи записывается ее длина.
LZ1 | Запись 1 | LZ2 | Запись 2 | LZ3 | Запись 3 |
Файлы с прямым доступом обеспечивают наиболее быстрый доступ. Не всегда можно хранить информацию в виде файлов прямого доступа, но главное – это то, что доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в БД необходим поиск по первичному или возможному ключам, иногда необходима выборка по внешним ключам, но во всех этих случаях мы знаем значение ключа, но не знаем номера записи, который соответствует этому ключу.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер записи файла).
NZ=F(K),
где NZ – номер записи, К – значение ключа.
Однако далеко не всегда удается найти взаимно однозначное соответствие между значениями ключа и номерами записей. Часто бывает, что значения ключей разбросаны по нескольким диапазонам. В этих случаях применяют различные методы хеширования (рандомизации) и создают специальные хэш-функции.
При организации доступа по ключу широко применяются индексные файлы.
В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (хеш-код). Преимущество хранения хеш — кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поисковых операций. Недостатком хеширования является необходимость выполнения операций свертки, что требует определенного времени, а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код).
Суть методов хеширования состоит в том, что мы берем значение ключа или некоторые его характеристики и используем его для начала поиска. То есть, вычисляем некоторую хеш-функцию, и полученное значение берем в качестве адреса начала поиска. При этом мы не требуем полного взаимно однозначного соответствия, но с другой стороны, для повышения скорости мы ограничиваем время этого поиска (количество дополнительных шагов) для окончательного получения адреса. Таким образом, мы допускаем, что нескольким разным ключам может соответствовать одно значение хеш-функции, то есть один адрес. Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хеш-функции называются синонимами. Поэтому при использовании хеширования как метода доступа необходимо принять 2 решения:
· выбор хеш- функции;
· выбор метода разрешения коллизий.
3. Индексные файлы
Несмотря на высокую эффективность хеш-адресации, в файловых структурах не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно совмещение двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс.
Сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа фалов: с плотным и неплотным индексом. Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются индексно-последовательными файлами.
4. Файлы с плотным индексом
В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи имеет следующий вид:
Здесь значение ключа – это значение первичного ключа, а номер записи – это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
В индексных файлах с плотным индексом для каждой записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном массиве. Наиболее эффективным из всех является бинарный поиск. Максимальное число шагов поиска определяется двоичным логарифмом от общего числа элементов (N).
Tn=log2N
Однако в нашем случае существенным является только число обращений к диску при поиске записи по заданному значению первичного ключа, так как обращение к диску является наиболее длительной операцией по сравнению со всеми обработками в ОП. Поиск происходит в индексной области, где применяется двоичный алгоритм поиска индексной записи, а затем путем прямой адресации мы обращаемся к основной области уже по конкретному номеру записи. Для того чтобы оценить максимальное время доступа, нам надо определить количество обращений к диску для поиска произвольной записи. На диске записи хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и ОС. В одном блоке могут размещаться несколько записей. Поэтому нам надо определить количество индексных блоков, которое потребуется для размещения всех требуемых индексных записей, а потому максимальное число обращений к диску будет равно двоичному логарифму от этого числа блоков плюс 1 (после поиска номера записи в индексной области надо будет обратиться к основной области файла).
Рассмотрим, как осуществляются операции добавления новых записей. При операции добавления осуществляется запись в конец основной области. В индексной области необходимо произвести занесение информации в конкретное место, чтобы не нарушать упорядоченности. Поэтому вся индексная область разделяется на блоки и при первоначальном заполнении в каждом блоке остается свободная область (процент расширения). После определения блока, в который должен быть занесен индекс, этот блок копируется в оперативную память, там он модифицируется путем вставки в нужное место новой записи и, уже измененный, копируется на диск.
В процессе добавления новых записей процент расширения постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны 2 решения: перестроить индексную область или организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную индексную область записи. Для того чтобы избежать подобных проблем, важно как можно точнее определить объем хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность действий: запись в основной области помечается как удаленная (отсутствующая), в индексной области соответствующий индекс уничтожается физически, то есть записи, следующие за удаленной записью, перемещаются на ее место, и блок, в котором хранился данный индекс, заново записывается на диск. При этом количество обращений к диску для этой операции такое же, как и при добавлении новой записи.
Файлы с неплотным индексом
Неплотный индекс строится для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид:
Значение ключа первой записи блока | Номер блока с этой записью |
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области.
Пример заполнения основной и индексной областей, если первичным ключом являются целые числа.
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше. Время доступа при использовании неплотного индекса уменьшается примерно в полтора раза. Рассмотрим процедуры добавления и удаления новой записи при неплотном индексе.
При включении новая запись должна заноситься сразу в требуемый блок на требуемое место. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить требуемую запись, а потом этот блок считывается в ОП, затем в ОП корректируется содержимое блока и он снова записывается на диск на старое место. Здесь, также как и в первом случае должен быть задан процент первоначального заполнения блоков, но только применительно к основной области. В MS SQL-Server этот процент называется Full-factor и используется при формировании кластеризованных индексов. Кластеризованными называют те индексы, в которых исходные записи физически упорядочены по значениям первичного ключа. При внесении новой записи индексная область не корректируется. Количество обращений к диску при добавлении новой записи равно количеству обращений, необходимых для поиска соответствующего блока плюс одно обращение, которое требуется для занесения измененного блока на старое место.
Tдобавления=log2N+1+1
Уничтожение записи происходит путем ее физического удаления на основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока. Поэтому количество обращений к диску такое же, как и при добавлении новой записи.
На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД, как правило, индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, часто называют файлами первичных индексов. Индексы, создаваемых для не ключевых полей, называют вторичными индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. В некоторых СУБД, например, Access деление на первичные и вторичные индексы не производится. В этом случае используются автоматически создаваемые индексы и индексы, определяемые пользователем.
Главная причина повышения скорости выполнения различных операций состоит в том, что основная часть работы производится с небольшими индексными файлами, а не с самими таблицами. Наибольший эффект повышения производительности работы с индексированными таблицами достигается для больших по объему таблиц. Индексирование требует незначительного дополнительного места на диске и незначительных затрат процессора для изменения индексов в процессе работы. Индексы в общем случае могут изменяться перед выполнением запросов к БД, после выполнения запросов к БД, по специальным командам пользователя или программным вызовам приложений. Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов:
· вида содержимого в поле ключа записей индексного файла;
· типа используемых ссылок (указателей) на запись основной таблицы;
· метода поиска нужных записей.
5. Моделирование отношений 1:М на файловых структурах
Для моделирования отношений 1:М и М:М на файловых структурах используется принцип организации цепочек записей внутри файла и ссылки на номера записей для нескольких взаимосвязанных файлов.
Моделирование отношений 1:М с использованием однонаправленных указателей
В этом случае связываются 2 файла, например, Ф1 и Ф2, причем предполагается, что одна запись в файле Ф1 может быть связана с несколькими записями в файле Ф2. При этом файл Ф1 в этом комплексе условно называется основным, а файл Ф2 – подчиненным. Структура основного файла может быть представлена в виде 3 областей:
Ключ | Запись | Ссылка-указатель на первую запись в подчиненном файле, с которой начинается цепочка записей файла Ф2, связанных с данной записью в файле Ф1 |
В подчиненном файле также к каждой записи добавляется специальный указатель, в нем хранится номер записи, которая является следующей в цепочке записей подчиненного файла, связанной с одной записью основного файла.
Таким образом, каждая запись подчиненного файла делится на 2 области: область указателя и область, содержащую собственно запись.
Структура записи подчиненного файла.
Указатель на следующую запись в цепочке | Содержимое записи |
В качестве примера рассмотрим связь между таблицами Преподаватели и Занятия.
Преподаватели
Ф1 | ||
Номер записи | Ключ и остальная запись | Указатель |
1 | Иванов И.И. | 1 |
2 | Петров П.П. | 3 |
Занятия
Ф2 | ||
Номер записи | Указатель на следующую запись в цепочке | Содержимое записи |
1 | 4 | Моделирование |
2 | — | Вычислительные сети |
3 | 6 | Исследование операций |
4 | 5 | ЭВМ и программирование |
5 | — | Модели данных и СУБД |
6 | — |
|
Преподаватель Иванов ведет Моделирование, ЭВМ и программирование, Модели данных и СУБД. Запись № 5 – последняя в этой цепочке, так как она не имеет указателя на следующую записью.
Алгоритм поиска нужных записей подчиненного файла:
· Ищем запись в основном файле в соответствии с ее организацией. Если требуемая запись найдена, то переходим к шагу 2, в противном случае выводим сообщение об отсутствии записи основного файла.
· Анализируем указатель в основном файле. Если он пустой, это значит, что для этой записи нет связанной записи в подчиненном файле, выводим соответствующее сообщение. В противном случае переходим к следующему шагу.
· По ссылке-указателю в найденной записи основного файла переходим прямым методом доступа по номеру записи на первую запись в цепочке подчиненного файла, переходим к следующему шагу.
· Анализируем текущую запись на содержание. Если это искомая запись, то заканчиваем поиск, в противном случае переходим к шагу 5.
· Анализируем указатель на следующую запись в цепочке. Если он пуст, то выводим сообщение о том, что искомая запись отсутствует, и прекращаем поиск. В противном случае переходим на следующую запись в подчиненном файле и снова переходим к шагу 4.
Использование цепочек позволяет эффективно организовывать модификацию взаимосвязанных файлов.
Алгоритм удаление записи из цепочки подчиненного файла.
· Ищем удаляемую запись в соответствии с ранее рассмотренным алгоритмом. Отличием при этом является обязательное сохранение в специальной переменной номера предыдущей записи в цепочке (NP).
· Запоминаем в специальной переменной указатель на следующую запись в найденной записи, заносим его в переменную NS. Переходим к шагу 3.
· Помечаем специальным символом, например, символом «*» найденную запись, то есть в позиции указателя на следующую запись в цепочке ставим “*”. Это означает, что данная запись отсутствует, а место в файле свободно и может быть занято любой другой записью.
· Переходим к записи с номером, который хранится в NP, и заменяем в ней указатель на содержимое переменной NS.
Для того чтобы эффективно использовать дисковое пространство при включении новой записи в подчиненный файл, ищется первое свободное место, то есть запись, помеченная символом “*”, и на ее место заносится новая запись. После этого производится модификация соответствующих указателей.
6. Инвертированные списки
До сих пор рассматривались структуры данных, которые использовались для ускорения доступа по первичному ключу. Однако достаточно часто в БД требуется проводить операции доступа по вторичным ключам. Возможно существование множества записей с одинаковыми значениями вторичного ключа. Например, в случае БД «Библиотека» вторичным ключом может служить место издания, год издания. Множество книг может быть издано в одном и том же месте.
Для обеспечения ускорения доступа по вторичным ключам используются структуры, называемые инвертированными списками, которые послужили основой организации индексных файлов для доступа по вторичным ключам.
Инвертированный список — это в общем случае двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в котором упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и тоже значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И, наконец, на третьем уровне находится уже собственно файл. Механизм доступа по вторичному ключу заключается в следующем. На первом шаге ищем в области первого уровня заданное значение вторичного ключа, затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа. Далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа. Размер блока ограничен 5-ю записями.
Пример инвертированного списка, составленного для вторичного ключа Номер группы в списке студентов некоторого учебного заведения.
7.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Какие файловые структуры используются для хранения данных во внешней памяти?
2. В чем заключаются различия между файлами прямого и последовательного доступа?
3. Что представляют собой индексные файлы? За счет чего повышается скорость обработки данных при использовании индексов?
4. Что содержится в основной и индексной области файлов с плотным индексом? Какие способы поиска применяются? Как осуществляется добавление, удаление записей?
5. Для каких файлов строится неплотный индекс? Что содержится в индексной области файлов с неплотным индексом?
6. Как выполняется включение новой записи в файл с неплотным индексом?
7. Как происходит удаление записи из файла с неплотным индексом?
8. Для каких областей задается процент первоначального заполнения блоков при использовании файлов с плотным и неплотным индексом?
9. Какова структура основного и подчиненного файла при использовании однонаправленных указателей для моделирования отношений 1:М?
10. Как организован поиск записей в подчиненном файле при использовании однонаправленных указателей?
11. Как происходит удаление записи из цепочки подчиненного файла?
12. Объясните принцип организации инвертированных списков и механизм поиска по вторичному ключу.
300+ TOP Структуры данных и алгоритмы MCQs Pdf 2021
Структуры данных и алгоритмы с несколькими вариантами ответов: —
1. Которые, если следующие, являются / являются уровнями реализации структуры данных
A) Абстрактный уровень
B) Уровень приложения
C) Уровень реализации
D) Все вышеперечисленное
2. Дерево двоичного поиска, левое поддерево и правое поддерево которого отличаются по высоте не более чем на 1 единицу, называется ……
A) Дерево AVL
B) Красно-черное дерево
C) Дерево лемм
D) Ничего из вышеперечисленного
3.……………… .. уровень, на котором модель становится совместимым исполняемым кодом
A) Абстрактный уровень
B) Уровень приложения
C) Уровень реализации
D) Все вышеперечисленное
4. Стек также называется
. A) Последний пришел — первым ушел
B) Первым пришел последним
C) Последний пришел последним
D) Первым пришел — первым вышел
5. Что из следующего верно относительно характеристик абстрактных типов данных?
i) Экспортирует тип.
ii) Экспортирует набор операций
A) Верно, неверно
B) Ложно, верно
C) Верно, верно
D) Ложно, неверно
6. …………… не является компонентом структуры данных.
A) Операции
B) Складские конструкции
C) Алгоритмы
D) Ни один из вышеперечисленных
7. Что из перечисленного не является частью описания ADT?
A) Данные
B) Операции
C) Оба вышеперечисленных
D) Ни один из вышеперечисленных
8.Вставка элемента в стопку, когда стопка не заполнена, называется …………. Операция и удаление элемента из стека, когда стек не пуст, называется ……… ..операцией.
A) нажимной, нажимной
B) поп, толчок
C) вставить, удалить
D) удалить, вставить
9. ……………. Это стопка, в которую элементы добавляются с одного конца и удаляются с другого.
A) Стек
B) Очередь
C) Список
D) Ни один из вышеперечисленных
10.………… очень полезен в ситуации, когда данные нужно сохранять, а затем извлекать в обратном порядке.
A) Стек
B) Очередь
C) Список
D) Список ссылок
11. Какая структура данных позволяет удалять элементы данных и вставлять их сзади?
A) Стеки
B) Очереди
C) Dequeues
D) Дерево двоичного поиска
12. Какая из следующих структур данных не может хранить неоднородные элементы данных?
A) Массивы
B) Записи
C) Указатели
D) Стеки
13.А ……. представляет собой структуру данных, которая упорядочивает данные аналогично строке в супермаркете, где первый в строке выходит первым.
A) Связанный список очереди
B) Связанный список стеков
C) Оба
D) Ни один из них
14. Что из перечисленного является нелинейной структурой данных?
A) Стеки
Б) Список
C) Струны
D) Деревья
15.Узел Хердера используется как дозорный в… ..
А) Графики
B) Стеки
C) Бинарное дерево
D) Очереди
16. Какая структура данных используется при поиске в ширину графа для хранения узлов?
A) Стек
Б) очередь
C) Дерево
D) Массив
17. Определите структуру данных, которая допускает удаление на обоих концах списка, но вставку только на одном конце.
A) Выход из очереди с ограничением по входу
B) Выход ограничен qequeue
C) Приоритетные очереди
D) Стек
18. Какая из следующих структур данных относится к нелинейному типу?
A) Струны
B) Списки
C) Стеки
D) График
19. Какая из следующих структур данных относится к линейному типу?
А) График
Б) Деревья
C) Бинарное дерево
D) Стек
20.Какая структура данных подходит для представления иерархических отношений между элементами?
A) Удаление из очереди
B) Приоритет
C) Дерево
D) График
21. Ориентированный граф — это ………………. если есть путь от каждой вершины до каждой другой вершины орграфа.
А) Слабое соединение
B) Сильная связь
C) Плотно связаны
D) Линейное соединение
22.В обходе …………… .. мы обрабатываем все потомки вершины перед тем, как перейти к соседней вершине.
A) Первая глубина
B) В ширину
C) С первым
D) Ограниченная глубина
23. Состояние Верно или Неверно.
i) Сеть — это граф, с которым связаны веса или затраты.
ii) Неориентированный граф, не содержащий циклов, называется лесом.
iii) Граф называется полным, если между каждой парой вершин нет ребра.
A) Верно, Ложно, Верно
B) Верно, Верно, Неверно
C) Верно, Верно, Верно
D) Ложь, правда, правда
24. Сопоставьте следующее.
a) Полнота i) Сколько времени нужно, чтобы найти решение.
b) Сложность времени ii) Сколько памяти необходимо для выполнения поиска.
c) Пространственная сложность iii) Гарантируется ли стратегия найти решение, когда оно есть.
A) a-iii, b-ii, c-i
B) a-i, b-ii, c-iii
C) a-iii, b-i, c-ii
D) a-i, b-iii, c-ii
25. Количество сравнений, выполненных последовательным поиском, составляет ………………
А) (Н / 2) +1
В) (N + 1) / 2
С) (Н-1) / 2
Д) (N + 2) / 2
26. В …………… поиск начинается с начала списка и проверяется каждый элемент в списке.
A) Линейный поиск
B) Бинарный поиск
C) Поиск по хэшу
D) Поиск в двоичном дереве
27.Укажите Истина или Ложь.
i) Двоичный поиск используется для поиска в отсортированном массиве.
ii) Временная сложность двоичного поиска составляет O (logn).
A) Верно, неверно
B) Ложь, правда
C) Неверно, Неверно
D) Верно, верно
28. Что из перечисленного не является внутренней сортировкой?
A) Сортировка вставкой
B) Пузырьковая сортировка
C) Сортировка слиянием
D) Сортировка кучи
29.Укажите Истина или Ложь.
i) Неориентированный граф, не содержащий циклов, называется лесом.
ii) Граф называется полным, если между каждой парой вершин есть ребро.
A) Верно, верно
B) Ложь, правда
C) Неверно, Неверно
D) Верно, Неверно
30. Граф называется ………………, если вершины могут быть разбиты на два множества V1 и V2, так что между двумя вершинами V1 или двумя вершинами V2 нет ребер.
A) Партит
B) Двудольный
C) Корневой
D) Биссектриса
31. В очереди начальные значения переднего указателя f редкого указателя r должны быть …… .. и ……… .. соответственно.
A) 0 и 1
B) 0 и -1
C) -1 и 0
D) 1 и 0
32. В кольцевой очереди значение r будет ..
А) г = г + 1
B) r = (r + 1)% [QUEUE_SIZE — 1]
C) r = (r + 1)% QUEUE_SIZE
D) r = (r-1)% QUEUE_SIZE
33.Какое из следующих утверждений верно?
i) Используя односвязные списки и циклический список, невозможно перемещаться по списку назад.
ii) Чтобы найти предшественника, необходимо пройти список от первого узла в случае односвязного списка.
A) только i-only
B) только ii
C) Оба i и ii
D) Ни один из
34. Преимущество …………… .. в том, что они решают проблему последовательного представления памяти.Но недостаток в том, что это последовательные списки.
A) Списки
B) Связанные списки
C) Деревья
D) Очереди
35. Каким будет значение вершины, если размер стека STACK_SIZE равен 5
А) 5
В) 6
С) 4
D) Нет
36. ………… не является операцией, которая может выполняться в очереди.
A) Вставка
B) Удаление
C) Получение
D) Переход
37.В начале списка есть дополнительный элемент, который называется ……….
А) Антинел
B) Sentinel
C) Заголовок списка
D) Заголовок списка
38. Граф — это набор узлов, называемых ………. И отрезки линии, называемые дугами или ……… .., которые соединяют пару узлов.
А) вершины, ребра
Б) ребра, вершины
C) вершины, пути
D) узел графа, ребра
39.……… .. — это граф, с ребрами которого связаны веса затрат.
A) Сеть
B) Взвешенный график
C) И A, и B
D) Нет A и B
40. Как правило, для метода двоичного поиска требуется не более ……………. сравнения.
A) [log2n] -1
B) [logn] +1
C) [log2n]
D) [log2n] +1
41. Что из перечисленного не относится к типу очереди?
A) Обычная очередь
B) Односторонняя очередь
C) Круговая очередь
D) Приоритетная очередь
42.Свойство двоичного дерева
A) Первое подмножество называется левым поддеревом
B) Второе поддерево называется правым поддеревом
C) Корень не может содержать NULL
D) Правое поддерево может быть пустым
43. Укажите истину или ложь.
i) Степень корневого узла всегда равна нулю.
ii) Узлы, которые не являются корневыми и не листовыми, называются внутренними узлами.
А) Верно, Верно
B) Верно, неверно
C) Ложь, правда
D) Ложь, Ложь
44.Любой узел — путь от корня к узлу называется
A) Узел-преемник
B) Узел предка
C) Внутренний узел
D) Ни один из вышеперечисленных
45. Состояние истина или ложь.
i) Узел является родительским, если у него есть узлы-преемники.
ii) Узел является дочерним узлом, если его степень равна единице.
А) Верно, Верно
B) Верно, Неверно
C) Ложь, правда
D) Ложь, Ложь
46.………………. не является операцией, выполняемой в линейном списке
a) Вставка b) Удаление c) Извлечение d) Обход
A) только a, b и c
B) только a и b
C) Все вышеперечисленное
D) Ни один из вышеперечисленных
47. Какое приложение (приложения) стека
A) Функциональные вызовы
B) Арифметические операции с большими числами
C) Оценка арифметических выражений
D) Все вышеперечисленное
48.…………… — ациклический орграф, в котором только один узел имеет степень 0, а другие узлы имеют внутреннюю степень 1.
A) Направленное дерево
B) Ненаправленное дерево
C) Разъединенное дерево
D) Дерево, ориентированное на направление
49. …………………. Это ориентированное дерево, в котором исходящая степень каждого узла меньше или равна двум.
A) Одинарное дерево
B) Двоичное дерево
C) Тройное дерево
D) И B, и C
50.Укажите истину или ложь.
i) Пустое дерево также является двоичным деревом.
ii) В строго двоичном дереве исходная степень каждого узла равна 0 или 2.
A) Верно, неверно
B) Ложь, правда
C) Верно, верно
D) Ложь, Ложь
51. Какие из следующих структур данных являются индексированными?
A. Линейные массивы
B. Связанные списки
C. Очередь
Д.Стек
52. В какой из следующих структур данных хранятся однородные элементы данных?
A. Массивы
B. Записи
C. Указатели
D. Списки
53. Когда новые данные должны быть вставлены в структуру данных, но нет свободного места; эту ситуацию обычно называют….
A. Отпуск
Б. перелив
C. Жилой
D. насыщенный
54.Структура данных, в которой элементы могут быть добавлены или удалены с любого конца, но не в середине, называется…
A. Связанные списки
Б. штабелей
C. очереди
D. удаление из очереди
55. Операции со структурой данных могут быть… ..
A. Создание
Б. Уничтожение
C. отбор
D. все вышеперечисленное
56. Способ, которым элемент или элементы данных логически связаны, определяет…..
A. Складская структура
B. структура данных
C. связь данных
D. Работа с данными
57. Какие из следующих операций применимы к примитивным структурам данных?
A. создать
Б. уничтожить
C. обновление
D. все вышеперечисленное
58. Использование указателей для ссылки на элементы структуры данных, в которой элементы являются логически смежными, — это….
A. указатели
B. Связанное распределение
C. стек
D. очередь
59. Лучшая структура данных — массивы
A. для относительно постоянных сборов данных
Б. за размер структуры и данные в структуре постоянно меняются
C. для обеих вышеупомянутых ситуаций
D. в случае отсутствия вышеуказанной ситуации
60. Какое из следующих утверждений неверно?
А.Массивы — это плотные списки и статическая структура данных.
B. Элементы данных связанного списка не нужно хранить в соседнем пространстве памяти
C. Указатели сохраняют следующий элемент данных списка.
D. Связанные списки — это совокупность узлов, содержащих информационную часть и следующий указатель.
Структуры данных и алгоритмы с множественным выбором вопросов и ответов: —
61. Какая из следующих структур данных имеет нелинейный тип?
A) Струны
B) Списки
C) Стеки
D) Дерево
62.Какая из следующих структур данных относится к линейному типу?
A) Массив
Б) Дерево
C) Графики
D) Иерархия
63. Логическая или математическая модель конкретной организации данных называется ………
A) Структура данных
B) Расположение данных
C) Конфигурация данных
D) Формирование данных
64. Самым простым типом структуры данных является ………………
A) Многомерный массив
B) Линейная решетка
C) Двумерный массив
D) Трехмерный массив
65.Линейные массивы также называются ……………….
A) Прямой массив
B) Одномерный массив
C) Вертикальный массив
D) Горизонтальный массив
66. Лучшая структура данных — это массивы …………
A) Для относительно постоянных сборов данных.
Б) За размер структуры и данные в структуре постоянно меняются
C) Для обеих вышеупомянутых ситуаций
D) Ни для одного из вышеперечисленных
67.Какие из следующих структур данных являются индексированными структурами?
A) Линейные массивы
B) Связанные списки
C) Графики
D) Деревья
68. Каждый узел связанного списка имеет две пары ………… .. и ……………….
A) Поле связи и информационное поле
B) Поле связи и поле доступности
C) Поле доступности и информационное поле
D) Поле адреса и поле ссылки
69.A …………………… не отслеживает адрес каждого элемента в списке.
A) Стек
B) Строка
C) Линейная решетка
D) Очередь
70. Когда изменяется верхнее значение стека?
A) Перед удалением
Б) При проверке переполнения
C) На момент удаления
D) После удаления
71. Какая из следующих структур данных имеет нелинейный тип?
A) Струны
B) Списки
C) Стеки
D) Дерево
72.Какая из следующих структур данных относится к линейному типу?
A) Массив
Б) Дерево
C) Графики
D) Иерархия
73. Логическая или математическая модель конкретной организации данных называется ………
A) Структура данных
B) Расположение данных
C) Конфигурация данных
D) Формирование данных
74. Самым простым типом структуры данных является ………………
A) Многомерный массив
B) Линейная решетка
C) Двумерный массив
D) Трехмерный массив
75.Линейные массивы также называются ……………….
A) Прямой массив
B) Одномерный массив
C) Вертикальный массив
D) Горизонтальный массив
76. Лучшая структура данных — это массивы …………
A) Для относительно постоянных сборов данных.
Б) За размер структуры и данные в структуре постоянно меняются
C) Для обеих вышеупомянутых ситуаций
D) Ни для одного из вышеперечисленных
77.Какие из следующих структур данных являются индексированными структурами?
A) Линейные массивы
B) Связанные списки
C) Графики
D) Деревья
78. Каждый узел связанного списка имеет две пары ………… .. и ……………….
A) Поле связи и информационное поле
B) Поле связи и поле доступности
C) Поле доступности и информационное поле
D) Поле адреса и поле ссылки
79.A …………………… не отслеживает адрес каждого элемента в списке.
A) Стек
B) Строка
C) Линейная решетка
D) Очередь
80. Когда изменяется верхнее значение стека?
A) Перед удалением
Б) При проверке переполнения
C) На момент удаления
D) После удаления
91. Лучшая структура данных — массивы
A) для относительно постоянных сборов данных
B) за размер структуры и данные в структуре постоянно меняются
C) для обеих вышеупомянутых ситуаций
D) ни в одной из вышеперечисленных ситуаций
92.Какая из следующих структур данных не является линейной структурой данных?
A) Массивы
B) Связанные списки
C) Оба вышеперечисленных
D) Ни один из вышеперечисленных
93. Недостатком использования кругового связного списка является …………………….
A) Можно попасть в бесконечный цикл.
B) Последний узел указывает на первый узел.
C) Требуется много времени
D) Требуется больше памяти
94.Линейный список, в котором каждый узел имеет указатели, указывающие на узлы-предшественники и узлы-последователи, называется ..
A) Односвязный список
B) Циркулярный связанный список
C) Двусвязный список
D) Линейный связанный список
95. A ……………… .. — это линейный список, в котором вставки и удаления выполняются с любого конца структуры.
A) кольцевая очередь
B) случайный из очереди
C) приоритет
D) удалить из очереди
96.В очереди с приоритетом вставка и удаление происходит по адресу ………………
A) передняя, задняя часть
B) только сзади
C) только на передней панели
D) любое положение
97. Временная сложность быстрой сортировки ………… ..
А) О (н)
В) O (n2)
C) O (n журнал n)
D) O (журнал n)
98. Что из перечисленного является применением стека?
A) нахождение факториала
B) Ханойская башня
C) преобразование инфикса в постфикс
D) все вышеперечисленное
99.Односторонняя структура данных ………………
А) очередь
B) стек
C) дерево
D) график
100. Список, который отображает взаимосвязь между элементами, называется
.А) линейный
В) нелинейная
C) связанный список
D) деревья
Просмотры сообщений: 853
Многоуровневая (8-уровневая) архитектура для корпоративных решений
Сегодня я хотел бы написать о многоуровневой архитектуре как лучшем варианте для корпоративных программных продуктов.Прежде чем углубляться в детали, я рассмотрю программные архитектуры с разным количеством уровней. Затем я опишу лучшие технологии для каждого уровня.
N-уровневые архитектуры
В зависимости от целей и сложности программного продукта он может иметь от одного до любого количества уровней. Помимо разделения на уровни (логически), продукт также может быть разделен на уровни (физически).
Одноуровневая архитектура, , где все программные компоненты хранятся в одном месте.
Такое программное обеспечение может быть запущено на одном компьютере и является самым простым и прямым вариантом. Все компоненты включены в одно приложение. Если данные необходимо изменить, это можно сделать только с помощью компьютера, на котором установлено программное обеспечение. Одноуровневой архитектуры недостаточно для веб-приложений или облачных решений.
Двухуровневая архитектура включает два уровня: уровень представления и уровень данных. Первый работает на стороне клиента, а второй хранит данные на сервере.
Этот подход улучшает масштабируемость и отделяет пользовательский интерфейс от уровня данных. Большая часть обработки происходит либо на стороне клиента, либо на сервере. В контексте увеличения числа пользователей производительность этой программной архитектуры может быть низкой.
Трехуровневая архитектура — самый популярный вариант. Он предоставляет следующие независимые слои:
- Уровень представления, который отображает информацию и взаимодействует с другими уровнями.
- Уровень приложения, который содержит бизнес-логику и управляет функциями приложения, выполняющими обработку.
- Уровень данных, на котором хранится и извлекается информация. Данные на этом уровне хранятся независимо от серверов приложений или бизнес-логики.
Это разделение позволяет разрабатывать, тестировать, выполнять и повторно использовать каждый уровень индивидуально. Уровень приложения также может быть многоуровневым. В этом случае общая архитектура называется N-уровневая архитектура .
Многоуровневая архитектура имеет множество преимуществ, например:
- Масштабируемость — любой слой можно масштабировать отдельно от других.
- Гибкость — любой слой можно изменить в соответствии с новыми требованиями, не затрагивая другие слои.
- Безопасность — каждый уровень можно защитить независимо и индивидуально.
- Управление — каждым уровнем можно управлять индивидуально и поддерживать изолированно.
Пример 8-уровневого приложения
На следующем изображении показан пример приложения с 8 слоями.Эти уровни могут быть распределены по серверам (уровням) в зависимости от конкретных потребностей:
Уровень клиентского приложения — это интерфейсный уровень, который позволяет взаимодействовать с клиентами с помощью веб-приложений, мобильных приложений и приложений для ПК.
Уровень Client API Layer включает специальные API (интерфейс прикладных программ), которые используются для взаимодействия с клиентскими приложениями.
Уровень API сторонних систем включает общедоступные API для интеграции со сторонними системами.
Уровень сервисной / бизнес-логики отвечает за обработку бизнес-данных (например, алгоритмов).
Уровень распределения данных гарантирует, что данные распределяются по кластеру и доступны для всех узлов, так что каждый узел может работать эффективно. Сетка распределенных данных является примером этого.
Уровень преобразования данных абстрагирует объекты API от объектов базы данных. Этот уровень позволяет поддерживать стабильность модели базы данных, когда API требует изменений.
Уровень логики сохранения состояния использует ORM сохранения состояния (объектно-реляционное сопоставление) и сохраняет данные, извлекает данные и т. Д. Этот уровень содержит логику взаимодействия с базой данных.
Уровень хранения базы данных играет роль хранилища данных.
Каждый из этих уровней может выполняться в распределенной среде, и это может быть одно-N-уровневое приложение.
При разработке корпоративного программного продукта с использованием подхода Smart Engine мы предпочитаем использовать трех- или четырехуровневую архитектуру.Типичные четырехуровневые решения описаны ниже.
Типовые решения для многоуровневой архитектуры
Здесь я опишу некоторые технологические решения, которые мы часто используем. Как известно, каждый уровень может быть разработан с использованием определенных технологий. Вот почему я хочу показать лучшие решения для каждого уровня отдельно.
Уровень представления
Уровень презентации может быть представлен с помощью настольных, веб-или мобильных приложений. Что касается веб-приложений, мы предпочитаем следующие технологии: JavaScript с JQuery и AngularJS.
Мобильные приложения можно создавать с помощью Cordova, ReactJS или Native App. Выбор лучшей технологии зависит от конкретных потребностей проекта. Cordova позволяет быстро разработать простое приложение с несколькими страницами. Однако, если требуется полнофункциональное мобильное приложение, Native App с прямым доступом к Native SDK может быть лучшим выбором.
Интеграция / уровень API
Вам могут потребоваться API для взаимодействия с бизнес-уровнем или сторонними объектами. В этом случае вы можете использовать методы SOAP или REST.Какой из них вы используете, зависит от спецификации стороннего объекта и требований конкретного проекта.
SOAP не зависит от языка, платформы и транспорта. Он хорошо работает в распределенных корпоративных средах. С другой стороны, REST более эффективен, быстрее и ближе к другим веб-технологиям в философии дизайна.
Уровень приложения
Уровень приложения содержит бизнес-логику, которая может состоять из одного или нескольких модулей. На этом уровне мы рекомендуем использовать следующие технологии: Java EE 7 и Java SE 8, Spring Framework и JPA / Hibernate ORM.
В зависимости от требований проекта уровень приложения можно разделить на несколько уровней. Этот шаг может повысить масштабируемость и удобство обслуживания приложения. Также возможна кластеризация.
Уровень данных
Уровень данных может состоять из дополнительных подуровней. Например, типичный процесс ETL (извлечение, преобразование и загрузка) включает уровни извлечения, преобразования и хранения; каждый из слоев может быть выполнен в отдельном ярусе.
В зависимости от требований проекта могут использоваться базы данных SQL или NoSQL.Также возможен гибридный подход SQL + NoSQL. Наши рекомендации следующие:
- Базы данных SQL : PostgreSQL, MySQL, Oracle. У каждого из них есть свои плюсы и минусы.
- NoSQL
Управляемое блочное хранилище | oVirt
Страницы функций — это проектные документы, созданные разработчиками во время совместной работы над oVirt.Большинство из них устаревшие , но содержат исторический контекст дизайна.
Это , а не пользовательская документация, и их не следует рассматривать как таковые.
Документация доступна здесь.
Сводка
Многие поставщики хранилищ предоставляют API-интерфейс разгрузки, позволяющий выполнять быстрые действия со стороны хранилища с минимальным использованием сети со стороны управления virt. Такие API уже интегрированы в Cinder.
Эта функция позволяет пользователю использовать любую серверную часть хранилища, поддерживаемую Cinder, для создания виртуальных дисков для своих виртуальных машин без необходимости полного развертывания OpenStack.
Владелец
Подробное описание
Cinder Library [1] предоставляет библиотеку Python, которая дает возможность напрямую использовать драйверы Cinder без необходимости полного развертывания OpenStack / Cinder с поддержкой более 80 драйверов хранения.
- Пользователь может настроить домен хранения с именем драйвера Cinder и набором параметров, необходимых для реализации драйвера.
- Пользователь может создавать / удалять / клонировать диски в этом домене хранения.
- Пользователь может создавать / удалять моментальные снимки дисков, созданных в этом домене хранения.
- Пользователь может запускать виртуальные машины с дисками, созданными в этом домене хранения.
- Пользователь может создать виртуальную машину из шаблона с дисками в этом домене хранения.
Пособие для ОВИРТА
Благодаря этой функции пользователь сможет использовать любого поставщика хранилища, поддерживаемого в Cinder (более 80 драйверов хранилища), и получить выгоду от функций разгрузки, реализованных поставщиками хранилища.
Пользовательский опыт
На стороне UX потоки хранения остаются без каких-либо изменений, за исключением нового типа Storage Domain, где пользователь должен будет предоставить набор параметров, необходимых драйверу (пары имя / значение). Конфиденциальные поля, такие как пароли, будут отделены от других и замаскированы в графическом интерфейсе.Эти поля будут храниться в БД в зашифрованном виде.
Например:
- volume_driver = ’cinder.volume.drivers.dell_emc.xtremio.XtremIOISCSIDriver’
- san_ip = ’10 .10.10.1 ’
- xtremio_cluster_name = ’xtremio_cluster’
- san_login = ’xtremio_user’
- san_password = ’xtremio_password’
Вот скриншот пользовательского интерфейса для домена хранения:
Высокий расход
Cinderlib необходимо сохранить метаданные томов для выполнения некоторых операций.Постоянство томов будет храниться в базе данных Postgres в новой базе данных.
API-интерфейсы Cinderlib будут вызываться движком вместе с параметрами БД и параметрами драйверов. Движку необходим доступ к сети Storage Management API.
Операции инициализации выполняются только на стороне Engine.
Создать домен хранения
Пользователь настраивает новый домен хранения со всеми необходимыми параметрами для драйвера Cinder:
- Движок вызывает API Cinderlib для проверки заданных параметров.
- Если вызов Cinderlib API успешен, Engine сохраняет данные в БД.
В случае, если некоторые параметры драйвера содержат конфиденциальную информацию, например пароли, пользователь может указать их как driver_sensitive_options . Эти параметры будут храниться в зашифрованном виде в БД и замаскированы в пользовательском интерфейсе.
Вот примеры использования REST API:
л.с. 3PAR:
<домен_хранилища>
cinder-hp3par
управляемый_block_storage
<хранилище>
управляемый_block_storage
<собственность>
драйвер_ тома
<значение> золы.volume.drivers.hpe.hpe_3par_fc.HPE3PARFCDriver
<собственность>
hpe3par_api_url
https://3par-cli.mgmt.acme.com:8080/api/v1
<собственность>
san_ip
10.10.10.10
<собственность>
san_login
администратор
<собственность>
san_password
my_secret
<хост>
vdsm-01
Ceph:
<домен_хранилища>
ceph-cinder
управляемый_block_storage
<хранилище>
управляемый_block_storage
<собственность>
rbd_ceph_conf
<значение> / etc / ceph / ceph.conf
<собственность>
rbd_pool
объемы
<собственность>
rbd_user
администратор
<собственность>
use_multipath_for_image_xfer
истина
<собственность>
драйвер_ тома
<значение> золы.volume.drivers.rbd.RBDDriver
<собственность>
rbd_keyring_conf
/etc/ceph/ceph.client.admin.keyring
<хост>
vdsm-01
Создать диск
Пользователь создает диск в домене хранения:
- Механизм вызывает API Cinderlib с параметрами серверной части драйвера, идентификатором тома, размером тома и URL-адресом БД.
- Если вызов Cinderlib API успешен, Engine создает диск в базе данных.
Удалить диск
Пользователь удаляет диск в домене хранения:
- Движок вызывает API Cinderlib с параметрами серверной части драйвера, идентификатором тома и URL-адресом БД для удаления тома.
- Если вызов Cinderlib API успешен, Engine удаляет диск в БД
Увеличить размер диска
Пользователь обновляет размер диска в домене хранения: — Движок вызывает API Cinderlib с параметрами серверной части драйвера, идентификатором тома, новым размером и URL-адресом БД.- Если вызов Cinderlib API успешен, Engine обновляет размер диска в БД
.Информация о разъеме от хоста Vdsm
Чтобы иметь возможность предоставлять том хосту, Cinderlib должна иметь информацию о его соединителе.
Как часть GetCapabilities Verb будет добавлена новая запись для предоставления необходимой информации.
Запуск VM
Пользователь запускает виртуальную машину с диском Cinderlib:
- Механизм вызывает API Cinderlib для подключения тома, используя информацию о соединителе для конкретного хоста, и возвращает данные, необходимые для вложения.
- Движок вызывает команду Vdsm для присоединения тома с необходимыми данными. Vdsm хранит локально детали прикрепления, которые потребуются для отсоединения, а затем возвращает путь.
- Механизм сохраняет результат в базе данных и использует возвращенный путь для тома в XML виртуальной машины.
Остановить ВМ
Пользователь останавливает виртуальную машину с помощью диска Cinderlib:
- Механизм вызывает команду Vdsm для отсоединения тома с идентификатором тома. Vdsm использует идентификатор, предоставленный движком, извлекает необходимые данные из своей локальной БД и отключает том.
- Движок вызывает API Cinderlib для отключения тома.
VDSM
Host.GetCapabilities
Vdsm использует библиотеку «os_brick» Cinder для сбора данных. Если библиотека «os_brick» не установлена на хосте, «connector_info» будет недоступна, и виртуальные машины с диском MBS не смогут работать на этом хосте.
Вот пример «connector_info»
"connector_info": {
"инициатор": "iqn.1994-05.com.acme: b82360563cee ",
"ip": "10.10.10.1",
"платформа": "x86_64",
"хост": "vdsm02",
"do_local_attach": ложь,
"os_type": "linux2",
"multipath": правда
}
ManagedVolume.attach_volume
Когда пользователь хочет запустить виртуальную машину, Engine сначала вызовет CinderLib API, чтобы предоставить том хосту в соответствии с «connector_info». API управления хранилищем предоставит информацию о подключении, необходимую хосту для подключения.Затем Engine вызывает ManagedVolume.attach_volume с этой информацией и идентификатором тома. Структура данных соответствует формату os_brick / Cinder.
Вот пример информации о подключении (том iSCSI):
{
"driver_volume_type": "iscsi",
"данные":
{
"target_lun": 26,
"target_iqn": "iqn.2009-01.com.kaminario: storage.k2.22612",
"target_portal": "3.2.1.1:3260",
"target_discovered": "Верно"
}
}
Vdsm вызовет API os_brick для присоединения тома и вернет данные с информацией о томе в Engine, который сохранит их в БД.Информация о томе состоит из пути к тому, который Engine будет использовать в XML виртуальной машины, и прикрепленного тома, возвращенного os_brick. Структура данных присоединения тома соответствует os_brick / Cinder формат.
Вот примеры информации о томе:
Для тома iSCSI с несколькими путями:
{
"путь": "/ dev / mapper / 20024f400585401ce",
«вложение»:
{
"путь": "/ dev / dm-25",
"scsi_wwn": "20024f400585401ce",
"тип": "блок",
"multipath_id": "20024f400585401ce"
}
}
Для объема РосБР:
{
"путь": "/ dev / rbd1",
«вложение»:
{
"путь": "/ dev / rbd1",
"тип": "блок",
"conf": "/ tmp / brickrbd_WimcIm"
}
}
Vdsm хранит информацию о томе вместе с информацией о подключении подключенных томов в локальной БД.Идентификатор тома будет ключом к данным в БД. Сохраненные данные используются, чтобы иметь возможность отфильтровать их из результата GetDeviceList и отсоединить том.
ManagedVolume.detach_volume
Когда пользователь хочет остановить виртуальную машину, Engine вызывает Vdsm, чтобы отсоединить том с идентификатором тома с помощью ManagedVolume.detach_volume.
Необходимые данные (информация об устройстве и информация о подключении) для выполнения отключения извлекаются из локальной БД.
ManagedVolume.volumes_info
Пользователь может получить информацию о конкретных томах с помощью ManagedVolume.volume_info с идентификаторами томов. Список всех томов можно получить с помощью ManagedVolume.volumes_info без указания идентификатора тома.
Vdsm вернет информацию о томе, как в потоке присоединения.
Помимо информации, содержащейся в потоке присоединения, он также включает идентификатор тома, а параметр существует , который имеет значение True , если подключено многопутевое устройство и путь существует на локальном компьютере.
Например:
[{
"vol_id": "01713ade-9688-43ff-a46c-0e2e35974dce",
"существует": "Верно",
"путь": "/ dev / mapper / 20024f400585401ce",
«вложение»:
{
"путь": "/ dev / sda",
"scsi_wwn": "20024f400585401ce",
"тип": "блок"
}
}]
Двигатель
- Добавить поддержку БД для дополнительной информации о домене хранения.
- Блокировать неподдерживаемые операции хранения.
- Исполняемый файл Python, предоставляющий API для Cinderlib
- Настроить дополнительную БД.
Установка
Cinderlib будет упаковываться в RPM. Драйверы Cinder и Cinderlib необходимо установить в Engine. OS-Brick необходимо установить на хостах
Ручная установка
Поскольку некоторые из необходимых библиотек в настоящее время не являются частью установки oVirt, необходимо выполнить следующие шаги:
на двигателе:
$ yum install -y centos-release-openstack-pike
$ yum-config-manager - включить openstack-pike
$ yum install -y openstack-cinder python-pip
$ pip install cinderlib
На всех хостах: (после установки пакетов необходимо перезапустить Vdsm)
$ yum install -y centos-release-openstack-pike
$ yum-config-manager - включить openstack-pike
$ yum install -y python2-os-brick
Для бэкэнда Ceph в движке и на всех хостах необходим следующий пакет:
$ yum install -y ceph-common
Также для бэкэнда Ceph, файла связки ключей и ceph.conf необходим в Engine.
Включить управляемый блочный домен в движке
Managed Block Domain не включен по умолчанию в Engine. Чтобы включить его, выполните следующую команду и перезапустите Engine:
$ engine-config -s ManagedBlockDomainSupported = true
Пожалуйста, выберите версию:
1. 4.3
2. 4.1
3. 4.2
# Выбрать 1
Открытые проблемы / ограничения
- Cinderlib должен быть упакован в об / мин, необходимых для двигателя.
- os-brick необходимо установить на хосты.
- В настоящее время для установки Cinderlib необходимо будет установить все библиотеки openstack-cinder.
- Engine в oVirt должен иметь доступ к сети Storage Management API.
- Не все потоки хранения поддерживаются в первом выпуске этой функции. Например :
- Миграция хранилища (холодная и активная)
- ОВФ
- Главный домен
- Аренда
- Мониторинг домена хранилища
- Для некоторых драйверов требуются дополнительные пакеты, которые необходимо будет установить на хостах.См. Здесь: [2]
Документация / Внешние ссылки
[1] Библиотека Cinder
[2] Необходимый пакет дополнительных драйверов
Архитектура на AWS: создание двухуровневого приложения
Идея масштабируемой облачной инфраструктуры с оплатой по мере использования, как правило, легко понимается большинством современных ИТ-специалистов. Однако, чтобы в полной мере воспользоваться преимуществами хостинговых решений в облаке, вам придется переосмыслить традиционные подходы к проектированию «на месте».Это должно происходить по целому ряду причин, наиболее заметными из которых являются расчет с учетом затрат или принятие подхода к расчету на отказ.
Это первая из серии статей, в которых мы познакомим вас с различными сервисами AWS начального уровня на примере построения архитектуры на AWS для создания стандартного двухуровневого развертывания приложения (например, mod_php LAMP). Мы будем использовать архитектуру для объяснения общей инфраструктуры и шаблонов проектирования приложений, относящихся к облачной инфраструктуре.
Для начала мы предоставляем вам общий обзор системы и краткое описание используемых услуг.
Виртуальное частное облако (VPC)
VPC позволяет развертывать службы в сегментированных сетях до , чтобы снизить уязвимость ваших служб для злонамеренных атак из Интернета. Разделение сети на общедоступные и частные подсети позволяет защитить уровень данных за брандмауэром и подключать только веб-уровень напрямую к общедоступному Интернету.Сервис VPC предоставляет гибкие возможности настройки правил маршрутизации и управления трафиком. Используйте Интернет-шлюз, чтобы обеспечить подключение к Интернету для ресурсов, развернутых в общедоступных подсетях.
Резервирование
В нашем эталонном дизайне мы распределили все ресурсы по двум зонам доступности (AZ), чтобы обеспечить резервирование и отказоустойчивость на случай непредвиденных сбоев или планового обслуживания системы. Таким образом, в каждой зоне доступности размещается по крайней мере один экземпляр для каждой службы, за исключением служб, которые являются избыточными по дизайну (например,г. Simple Storage Service, Elastic Load Balancer, Rote 53 и т. Д.).
Веб-уровень
Наш веб-уровень состоит из двух веб-серверов (по одному в каждой зоне доступности), которые развернуты в экземплярах Elastic Compute Cloud (EC2). Мы балансируем внешний трафик к серверам с помощью Elastic Load Balancers (ELB). Политики динамического масштабирования позволяют эластично масштабировать среду при добавлении или удалении веб-экземпляров в группу автоматического масштабирования. Amazon Cloud Watch позволяет нам отслеживать спрос на нашу среду и запускать события масштабирования с помощью сигналов тревоги Cloud Watch.
Уровень базы данных
Управляемая служба реляционных баз данных Amazon (RDS) предоставляет реляционную среду (MySQL, MS SQL или Oracle) для этого решения. В этом эталонном дизайне он устанавливается как развертывание в нескольких зонах доступности. Развертывание в нескольких зонах доступности включает резервный экземпляр RDS во второй зоне доступности, что обеспечивает повышенную доступность и надежность на для службы базы данных при синхронной репликации всех данных в резервный экземпляр.
При желании мы также можем подготовить реплики для чтения, чтобы снизить нагрузку на основную базу данных.Для оптимизации затрат наше первоначальное развертывание может включать только главный и подчиненный экземпляры RDS, с дополнительными репликами чтения, созданными в каждой зоне доступности, как того требует спрос.
Магазин предметов
Наши файловые объекты хранятся в Amazon Simple Storage Service (S3). Объекты в S3 управляются в сегментах, которые обеспечивают практически неограниченной емкости хранилища . Управление жизненным циклом объектов в корзине S3 позволяет нам архивировать (передавать) данные в более экономичную службу Amazon Glacier и / или удалять (истечение срока) объектов из службы хранения на основе политик.
Задержка и взаимодействие с пользователем
Для минимизированной задержки и улучшенного взаимодействия с нашими пользователями по всему миру мы используем сеть распространения контента Amazon CloudFront. CloudFront поддерживает большое количество периферийных местоположений по всему миру. Пограничное расположение действует как массивный кеш для Интернета и потокового контента.
Управление инфраструктурой, мониторинг и контроль доступа
Любой аккаунт AWS должен быть защищен с помощью Amazon Identity and Access Management (IAM).IAM позволяет создавать пользователей, группы и разрешения для обеспечения детализированного управления доступом на основе ролей ко всем ресурсам, размещенным в AWS.
Предоставление вышеуказанного решения регионам достигается с помощью Amazon CloudFormation. CloudFormation поддерживает предоставление и управление сервисами и ресурсами AWS с помощью шаблонов с возможностью создания сценариев. После создания CloudFormation также обновляет подготовленную среду на основе изменений, внесенных в «определение инфраструктуры по сценарию».
Мы используем службу доменных имен Route 53 для регистрации и управления нашим интернет-доменом.
Таким образом, мы познакомили вас с множеством сервисов AWS, каждый из которых был выбран для решения одной или нескольких конкретных проблем, касающихся функциональных и нефункциональных требований всей системы. В наших следующих публикациях мы рассмотрим ряд вышеупомянутых услуг более подробно, обсудим основные конструктивные особенности и компромиссы при выборе подходящей услуги для вашего решения.А пока вы можете начать узнавать больше об отдельных сервисах AWS с помощью AWS Learning Paths, доступных в библиотеке Cloud Academy.
Автор
Кристиан Петтерс
Как архитектор решений, Кристиан помогает организациям найти наиболее подходящее решение для решения их уникальных бизнес-проблем.Он увлечен возможностями, которые предоставляют современные облачные сервисы, и освещает темы в AWS и MS Azure, уделяя особое внимание технологиям Microsoft.
| вторник | четверг |
|---|---|
Деревья слияния, часть I 2 июня Память внутри компьютера разбита на отдельные машинные слова с примитивными операциями. например, сложение, вычитание и умножение с постоянным временем.Это означает, что если мы сможем упаковать несколько частей данных в одно машинное слово, мы можем получить ограниченную форму параллельных вычислений. С помощью множества очень умных уловок мы можем использовать это, чтобы ускорить поиск и сортировка. Эта первая лекция исследует параллелизм на уровне слов через структуру данных для очень маленьких целые числа и метод вычисления старших разрядов за время O (1). Он заложит основу, которую мы будем использовать в следующий раз при исследовании деревьев слияния. Слайды: Чтения: | Деревья слияния, часть II 4 июня Сардиновое дерево, которое мы разработали в нашей последней лекции, дает быстро упорядоченный словарь. структура данных для маленьких ключей. Используя его ключевое понимание — поиск в B-дереве может можно ускорить за счет улучшения вычислений ранга на каждом узле и сочетания его с некоторые идеи о целых числах и попытках Патрисии, мы можем построить дерево слияния, которое работает для любых целых чисел, которые входят в машинное слово. Слайды: |
Splay Trees 26 мая Красные / черные деревья перемещают узлы только во время вставки или удаления. Что будет, если мы реструктурируем наши BST каждый раз, когда мы выполняем с ними операцию? Если вы сделаете это правильно, ответ будет «замечательно вещи, но мы не уверены, насколько они прекрасны «. Слайды: Чтения: | x -Быстрый и y -Быстрый попытки 28 мая Сбалансированные BST — отличные структуры данных общего назначения для хранения отсортированных коллекций. элементов.Но что произойдет, если мы узнаем, что эти элементы являются целыми числами? Воспользовавшись их структуры и некоторых хороших свойств машинных слов, мы можем экспоненциально улучшить их производительность. Слайды: Чтения: |
Хеширование кукушки 19 мая Большинство хеш-таблиц дают ожидаемый поиск O (1). Можем ли мы сделать хеш-таблицы без столкновений, и если да, можем ли мы сделать это эффективно? Удивительно, но ответ — да.Есть много схем достижения это, одно из которых, хеширование с кукушкой, на удивление просто воплощать в жизнь. Слайды: Чтения: Раздаточные материалы: | Лучше, чем сбалансированные BST 21 мая Мы работали в предположении, что сбалансированный BST, который имеет наихудший поиск O (log n), равен в некотором смысле «оптимальное» двоичное дерево поиска.В определенном смысле (эффективность наихудшего случая) эти деревья являются оптимальный. Однако есть и другие точки зрения, на которые мы можем взглянуть, что означает «оптимальный», и они советуют к другим вариантам древовидной структуры — деревьям со сбалансированным весом, деревьям поиска пальцами и структура рабочего набора. Слайды: Чтения: |
Эскизы Count-Min 12 мая Как Google может отслеживать частые поисковые запросы, не сохраняя все запросы, которые он получает в памяти? Как вы можете оценить часто- появляются твиты без сохранения каждого твита в ОЗУ? Так долго как вы готовы обменять точность на пространство, вы получите отличный приближения. Слайды: Чтения: | Счетчики эскизов и фильтры Блума 14 мая Теперь мы увидели, как построить оценщик: создайте простую структуру данных, которая дает хорошие шансы на успех, а затем запустить его параллельно. Эта идея может быть расширена для построения частотных оценщиков с другими свойствами и построения оценки булевых величин.Эта лекция посвящена методам, необходимым для этого. Слайды: Чтения: |
Биномиальные кучи 5 мая Биномиальные кучи — это простая и гибкая структура очереди с приоритетами. который поддерживает эффективное объединение приоритетных очередей. Интуиция позади биномиальных куч особенно элегантно, и они будут служить как строительный блок для более сложных данных кучи Фибоначчи структура, о которой мы поговорим в четверг. Слайды: Чтения: | Куча Фибоначчи 2 мая Кучи Фибоначчи — это тип приоритетной очереди, которая эффективно поддерживает клавишу уменьшения, операцию, используемую в качестве подпрограммы во многих алгоритмы графа (алгоритм Дейкстры, алгоритм Прима, Алгоритм минимального сокращения Стоера-Вагнера и т. Д.) Они созданы умным преобразование на ленивую биномиальную кучу.Хотя кучи Фибоначчи имеют репутацию чрезвычайно сложных, они намного менее страшно, чем может показаться! Слайды: Чтения: Раздаточные материалы: |
Сбалансированные деревья, часть II 28 апреля Наша последняя лекция завершилась рассмотрением красно-черных деревьев как изометрий 2-3-4 деревьев.Как далеко это подключение идет? Как мы можем использовать его, чтобы вывести правила для красных / черных деревьев? И теперь, когда у нас есть красно-черные деревья, что еще мы можем с ними сделать? Слайды: Чтения: Раздаточные материалы: | Амортизированный анализ 30 апреля Во многих случаях нас заботит только общее время, необходимое для обработки набор данных.В таких случаях мы можем разработать структуры данных, которые сделать некоторые операции более дорогими, чтобы снизить общую стоимость всех агрегатных операций. Как вы анализируете эти структуры? Слайды: Чтения: |
Построение массивов суффиксов 21 апреля Деревья суффиксов и массивы суффиксов — удивительные структуры, но они были бы гораздо менее полезны, если бы не возможно построить их быстро.К счастью, есть отличные методы построения суффиксов массивы и суффиксные деревья. Используя тот факт, что суффиксы перекрываются, и имитируя многостороннее слияние алгоритм подойдет при определенных обстоятельствах, мы можем быстро построить эти прекрасные конструкции. Слайды: Чтения: Раздаточные материалы: | Сбалансированные деревья, часть I 23 апреля Сбалансированные деревья поиска — одни из самых универсальных и гибких структур данных.Они широко используются в теории и на практике. Какие виды сбалансированных деревьев существуют? Как бы вы их спроектировали? А что с ними делать? Слайды Раздаточные материалы: Чтения: |
Дерево попыток и суффиксов 14 апреля Чтобы начать обсуждение строковых структур данных, мы рассмотрим попытки, попытки Патрисии и большинство главное, суффиксные деревья.Эти структуры данных обеспечивают быстрое решение ряда алгоритмических проблем. и намного более универсальны, чем может показаться на первый взгляд. Что делает их такими полезными? Какие свойства струны они захватывают? И какие интуиции мы можем построить из них? Слайды: Раздаточные материалы: | Массивы суффиксов 16 апреля Что делает суффиксные деревья такими полезными в качестве структуры данных? Удивительно, но большая часть их полезности и гибкость можно объяснить двумя фактами: они хранят суффиксы отсортированными, и они выставить ветвящиеся слова в строке.Представляя эту информацию другим способом, мы можем получить большую часть преимуществ суффиксных деревьев без огромных затрат на пространство. Чтения: Слайды: |
Минимальный диапазон запросов, часть первая 7 апреля Задача запроса минимума диапазона следующая: задан массив, предварительно обработать его, чтобы вы могли эффективно определить наименьший значение в различных поддиапазонах.RMQ имеет множество приложений в информатике и является отличным полигоном для ряд передовых алгоритмических приемов. Слайды: Чтения: | Минимальный диапазон запросов, часть вторая 9 апреля Наша последняя лекция привела нас очень, очень близко к решению RMQ за время & langle; O (n), O (1) & rangle ;.Использование новой структуры данных, называемой декартовым деревом, в сочетании с техникой, называемой Метод четырех русских, мы можем адаптировать наш подход, чтобы получить линейное время предварительной обработки, решение для RMQ с постоянным временем запроса. |