
Кодирование символьной информации
⇐ ПредыдущаяСтр 5 из 5Символьная (алфавитно-цифровая) информация в компьютере представляется посредством восьмиразрядных двоичных кодов. Полное число кодовых комбинаций нулей и единиц определяется длиной (разрядностью) кода и составляет 28 = 256. То есть, используя восьмиразрядный двоичный код (восемь битов) можно закодировать 256 символов. Каждому символу (цифре, букве, знаку) ставится в соответствие единственный код из числа кодовых комбинаций. С помощью восьмиразрядного кода можно закодировать строчные и прописные буквы как латинского, так и русского алфавитов, цифры, знаки препинания, знаки математических операций и некоторые специальные символы (например, §, /).
Каждому символу алфавита сопоставляется определенное целое число из диапазона от 0 до 255 – это его порядковый номер, код. Если “открыть” память ЭВМ, то можно увидеть коды букв. Обычный текст представляется в компьютере последовательностью кодов, иначе говоря, вместо каждой буквы текста хранится ее номер по кодовой таблице.
Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера [6, c. 21]. Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255. Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств. В этой области размещаются так называемые управляющие коды, которые не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) – ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня эта кодировка имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета. В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных – это одна из распространенных задач информатики.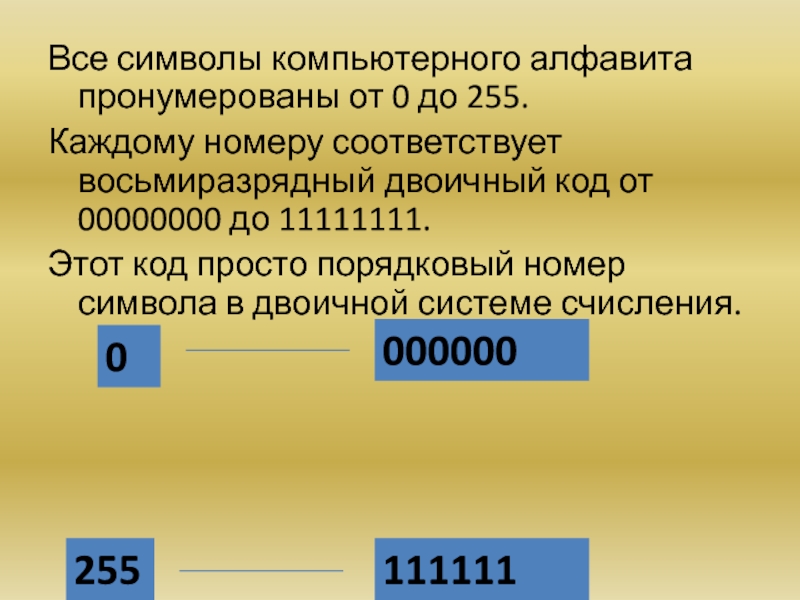
Кодирование чисел в ЭВМ
Числа вводятся в десятичном виде, а в памяти компьютера они представляются двоичными кодами. При выводе числа снова преобразуются в десятичную систему счисления. Чаще встречаются целые числа, среди которых можно выделить короткие (по числу цифр) и длинные. Целые числа принято изображать арабскими цифрами, употребляя при необходимости знаки “+” и “-“ . Очевидно, что эти 12 символов также должны присутствовать в кодовой таблице и меть там свои номера (коды). Для представления коротких целых чисел используют 2 байта (16 бит). Полное число возможных состояний, представимых 16-ю битами, составляет 2
Чаще встречаются целые числа, среди которых можно выделить короткие (по числу цифр) и длинные. Целые числа принято изображать арабскими цифрами, употребляя при необходимости знаки “+” и “-“ . Очевидно, что эти 12 символов также должны присутствовать в кодовой таблице и меть там свои номера (коды). Для представления коротких целых чисел используют 2 байта (16 бит). Полное число возможных состояний, представимых 16-ю битами, составляет 2 Иногда встречаются более длинные целые числа, которые не помещаются в указанный диапазон. Тогда добавляют еще 2 байта, т.е. диапазон значений увеличивается на 65536. Получается новый диапазон от -2147483648 до +2147483647. Более крупные целые числа на практике встречаются очень редко, и последнего диапазона оказывается вполне достаточно.
Иногда встречаются более длинные целые числа, которые не помещаются в указанный диапазон. Тогда добавляют еще 2 байта, т.е. диапазон значений увеличивается на 65536. Получается новый диапазон от -2147483648 до +2147483647. Более крупные целые числа на практике встречаются очень редко, и последнего диапазона оказывается вполне достаточно.
Таким образом, при кодировании целых чисел в два байта помещается, по крайней мере, четырехзначное число со знаком, а в четыре байта – девятизначное. Если бы в каждый байт заносили только по одной цифре числа (как буквы или другие символы), то в два байта помещались бы числа в диапазоне от 0 до 99.
Число +15 в машине будет иметь вид 00000000 00001111, а число 257 будет иметь вид 00000001 00000001. Как видно коды чисел представлены в двоичной системе счисления. Как переводятся числа из десятичной в двоичную систему счисления и наоборот?
Для перевода числа из любой системы счисления в двоичную делят данное число на 2 и записывают остаток (0 или 1), результат снова делят на 2 и новый остаток записывают слева от первого и т.
Х(2) = хn-1 2n-1 + xn-2 2n-2 + … + x1 21 + x0 20,
где x i = 0 или 1; n – число разрядов (позиций) в целой части числа. Например, 1710 = 100112, 100112 = 1 × 24 + 0 × 23 + 0 × 22 + 0 × 21 + 1 × 20 = 16 + 1 = 1710.
Например, 1710 = 100112, 100112 = 1 × 24 + 0 × 23 + 0 × 22 + 0 × 21 + 1 × 20 = 16 + 1 = 1710.
Для представления служебной информации – программ при подготовке задач к решению на ЭВМ – применяют вспомогательные системы счисления – восьмеричную и шестнадцатеричную. Обе системы используются для более короткой и удобной записи двоичных кодов. Это связано с понятием байта – 8 двоичных разрядов или 2 шестнадцатеричных. Например, 197210 = 111101101002 = 36648 = 7В416.
Для кодирования действительных чисел их предварительно преобразуют в форму представления чисел с плавающей точкой или нормализованную форму. В нормальной форме число представляется в виде произведения
Кодирование информации [Love Soft]
Информация может поступать от передатчика к приёмнику с помощью условных знаков или сигналов самой разной физической природы. Сигнал может быть световым, звуковым, тепловым, электрическим, в виде жеста, слова, движения, другого условного знака.
Сигнал может быть световым, звуковым, тепловым, электрическим, в виде жеста, слова, движения, другого условного знака.
Для того чтобы произошла передача информации, приёмник должен не только принять сигнал, но и расшифровать его. Так, услышав звонок будильника — человек понимает, что пришло время просыпаться; телефонный звонок — кому-то нужно с вами поговорить; школьный звонок — сообщает учащимся о долгожданной перемене.
Код — это система условных знаков для представления информации.
Кодирование — это переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Обратное преобразование называется декодированием — процесс восстановления содержания закодированной информации.
Кодирование и шифрование информации — разные вещи. См. Криптография
Кодировать и декодировать информацию человек учится с самого раннего детства.
Когда вы рассказываете другу о своей туристической поездке в Париж, происходит кодирование визуальной информации (впечатлений, полученных в поездке) в звуковую форму: «Эйфелева башня очень высокая, внутри есть ресторан». Ваш приятель, слушая вас, воображает образ Эйфелевой башни — то есть производит декодирование информации: слова переводятся в зрительный образ.
Ваш приятель, слушая вас, воображает образ Эйфелевой башни — то есть производит декодирование информации: слова переводятся в зрительный образ.
Музыкальные звуки характеризуются следующими свойствами: высота, тембр и громкость. В музыке также используется такое понятие, как длительность звука.
Когда говорят, что звук мягкий, густой, резкий, звенящий — это говорят именно о тембре звука. Вы можете по голосу узнать своего знакомого, потому что тембр его голоса не такой, как у других. Вы можете отличить звук гитары от звука флейты, потому что этим инструментам присуща своя окраска звука, свой тембр. Различие тембров объясняется тем, что у каждого звука есть так называемые добавочные звуки, «призвуки». Их называют обертонами. Образуются обертоны вследствие сложной формы звуковой волны.
Различие тембров объясняется тем, что у каждого звука есть так называемые добавочные звуки, «призвуки». Их называют обертонами. Образуются обертоны вследствие сложной формы звуковой волны.
Звукоряд. В основу музыкальной системы положен ряд звуков. Этих звуков ровно 88, расположены они в порядке возрастания высоты звука.
Расстояние между соседними звуками ступеней с одинаковыми названиями назвали октавой. Например: между соседними двумя соль — ровно октава. Названия октав от самых низких до самых высоких: субконтроктава, контроктава, большая октава, малая октава, первая октава, вторая, третья, четвёртая и пятая октава.
Давайте посмотрим на фрагмент клавиатуры пианино: всего клавиш, включая и белые, и чёрные, ровно 12. Таким образом, октава состоит из 12-ти звуков. Расстояние между двумя соседними звуками получило название полутона. Такой музыкальный строй называется темперированным. В отличие от натурального строя, в нём все полутоны равны.
Для записи звуков используются специальные знаки — ноты (это латинское слово, переводится как «знак»). Нота представляет собой кружок, который может быть внутри пустой, либо не пустой.
Для обозначения длительности ноты (сколько по времени должна звучать нота) используют штили (вертикальная палочка), флажки и рёбра. Флажки и рёбра «крепятся» к штилю.
Нота со штилём: ♩. Нота с одним флажком: ♪. Если у нот, расположенных одна за одной, есть флажки (особенно, если количество флажков одинаково), то их можно сгруппировать. Тогда флажки называются рёбрами: ♫ ♬. То есть такая запись: ♫ и вот такая: ♪♪ равносильны.
Целая нота — незаштрихованный кружочек (овал), обладает наибольшей длительностью. Половинная — то же самое, но добавлен штиль. Её длительность вдвое короче длительности целой ноты. Четвертная — как и половинная, но овал уже заштрихован, восьмая — как предыдущая, с добавлением флажка или ребра, шестнадцатая — та же восьмая, но ее хвостик (или ребро) изображается сдвоенным. Далее, по тому же принципу, пишутся более мелкие длительности: тридцатьвторые, шестьдесятчетвертые. Более короткие ноты используются редко.
Далее, по тому же принципу, пишутся более мелкие длительности: тридцатьвторые, шестьдесятчетвертые. Более короткие ноты используются редко.
Существуют дополнительные знаки, увеличивающие длительности нот. Точка увеличивает длительность ноты на половину. Ставится справа от ноты. Пример: если нота ♩ звучит, например, секунду, то нота с точкой ♩. будет звучать полторы секунды. Лига — вогнутая линия, которая связывает две ноты одной высоты. Извлекается звук в том месте, где встретилась первая нота (вторая нота не извлекается), длительность будет равна сумме длительностей обеих нот, связанных лигой. Фермата обозначает неограниченное увеличение длительности. Обозначается дугой с точкой в центре изгиба.
Нотный стан состоит из 5 горизонтальных линеек, на которых располагаются ноты и другие знаки нотного письма. Линии нотного стана нумеруются снизу вверх. 5 нотных линий разбиваются на такты с помощью вертикальных палочек. Между двумя вертикальными линиями располагается один такт.
Между двумя вертикальными линиями располагается один такт.
Как правило, самый сильный акцент приходится на первую долю такта. Второй по силе — на середину такта. Самая слабая доля выпадает на конец такта. Часть такта, которая содержит акцентированные звуки, называется сильной долей. Части такта, не имеющие акцентов, называются слабыми долями. Знаком > обозначают акцентированную ноту. Знаком ∧ обозначают сильно акцентированную ноту.
В начале произведения обязательно указывается размер, в котором написано произведение. Размер указывается двумя цифрами, расположенными одна над другой. Нижняя цифра указывает длительность ноты, а верхняя — сколько нот данной длительности составляют суммарную длительность такта. Пример: четыре четверти, что обозначает буквально следующее: в каждом такте суммарная длительность всех нот и пауз должна быть равна длительности, которую составляют 4 ноты, каждая из которых длительностью в четверть. Верхняя цифра размера показывает количество долей в такте, а нижняя — длительность каждой доли. Такт — это ещё и отрезок произведения от сильной доли до следующей сильной доли.
Такт — это ещё и отрезок произведения от сильной доли до следующей сильной доли.
rithm1.mp3 ( B, 50y ago, 0 downloads)
Ключ — элемент нотного письма, который определяет расположение нот на нотном стане. Ключ указывает размещение одной из нот, от которой отсчитываются все остальные ноты. Существует несколько видов ключей, мы же рассмотрим 3 основных: это Скрипичный ключ, Басовый ключ и Альтовый ключ.
Скрипичный Ключ. Этот ключ указывает положение ноты Соль первой октавы:
Обратите внимание на красную линию нотного стана. Её охватывает ключ своим завитком. Этим ключ указывает расположение ноты соль. Все остальные ноты будут размещаться с учётом обозначенной ключом ноты. На рисунке мы разместили ноты от до (самая первая нота, находится внизу на дополнительной линии) до си (на центральной линии). Последний символ — пауза.
Басовый Ключ. Указывает расположение ноты Фа малой октавы. Его начертание напоминает запятую, кружок которой указывает линию ноты фа.
Альтовый ключ. Этот ключ указывает расположение ноты До первой октавы: она находится на средней линии нотного стана:
Может возникнуть вопрос: «Почему нельзя обойтись одним ключом»? Читать ноты удобно, когда основная часть нот располагается на нотном стане без дополнительных линий сверху и снизу. Да и сама мелодия таким образом записывается компактней.
Знаки альтерации: диез, бемоль, бекар. Диез. Звук чёрной клавиши относительно ноты до выше на полтона. Такое повышение называют словом диез. В данном случае это — до-диез. Обозначается диез символом решётки ♯. Теперь рассмотрим ту же самую чёрную клавишу, но уже относительно ноты ре. Звук «чёрной клавиши» ниже ноты ре на полтона. Понижение основной ступени на полтона называют словом бемоль ♭. Нашей чёрной клавише соответствует либо нота «до-диез», либо нота «ре-бемоль» — всё зависит от того, какую ноту берём за основу.
Бекар ♮ отменяет действие диеза или бемоля.
Паузы. Длительность пауз определяется абсолютно также, как и у звуков (нот): она может быть равна целой ноте, половинной, четвертной и т.д.
Музыку для фортепиано записывают на двух нотных станах (очень редко — на трёх), которые объединяют слева фигурной скобкой — акколадой.
Урок № 8. Тексты в компьютерной памяти
Основные темы параграфа:
• преимущества компьютерного документа по сравнению с бумажным;
• как представляются тексты в памяти компьютера;
• что такое гипертекст.
Преимущества компьютерного документа по сравнению с бумажным
А теперь от обсуждения вопроса о том, что представляет собой компьютер, перейдем к ответу на вопрос, что умеет делать компьютер. Начиная с этой главы, мы будем знакомиться с применением ЭВМ.
Первая область применения, которую мы рассмотрим, — работа с текстами. При ручной записи часто неприятную проблему составляет необходимость исправлять ошибки или вносить какие-то изменения в текст. При этом приходится зачеркивать, стирать, заклеивать, что портит вид текста. Необходимость переписывать текст ведет к потере времени и лишнему расходу бумаги.
Имея компьютер, можно создавать тексты, не тратя на это лишнее время и бумагу. Носителем текста становится память ЭВМ. Конечно, для длительного его сохранения это должна быть внешняя память — магнитные или оптические диски.
Текст на внешних носителях сохраняется в виде файла.
Есть ряд преимуществ сохранения текстов в файловой форме на компьютерных носителях по сравнению с бумагой. Во-первых, это компактное размещение. Например, текст толстой книги в 500 страниц помещается на маленькую дискету диаметром 9 см. А если использовать специальные методы сжатия, то размер текста, помещающегося на дискете, можно увеличить в несколько раз.
Во-вторых, если данный текст становится ненужным, то дискету, как бумагу, не надо выбрасывать или сдавать в макулатуру. С нее с помощью компьютера легко стереть этот текст и на его место записать новый.
В-третьих, с помощью компьютера легко скопировать файлы в любом количестве на другие носители.
В-четвертых, файл с текстом можно быстро переслать другому человеку по электронной почте. Для этого ваш компьютер и компьютер адресата должны иметь связь через компьютерную сеть.
Главное неудобство хранения текстов в файлах состоит в том, что прочитать их можно только с помощью компьютера. Человек может просмотреть текст на экране дисплея или напечатать на бумаге, используя принтер.
Уже сейчас имеются некоторые издания, которые не печатаются на бумаге, а хранятся и распространяются в форме файлов. Когда компьютеры станут такими же обычными предметами в каждом доме, как сейчас радио и телевизор, то безбумажных изданий станет еще больше. Представьте себе, что вся ваша личная библиотека разместится в коробке с дисками. Причем по объему информации она будет не меньше, чем сотни книг, собранных родителями. А экономя бумагу, мы сохраняем леса на нашей планете.
Как представляются тексты в памяти компьютера
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 28 = 256. 8 битов = 1 байт, следовательно:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодирования.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код — просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки. С распространением персональных компьютеров типа IВМ РС международным стандартом стала таблица кодировки под названием АSCII (American Standart Code for Information Interchange — американский стандартный код для информационного обмена).
Точнее говоря, стандартной в этой таблице является только первая половина, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная с 10000000 и кончая 11111111, используются в разных вариантах. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
В табл. 3.1 приведена стандартная часть кода АSCII (коды от 0 до 31 имеют особое назначение, не отражаются какими-либо знаками и в данную таблицу не включены). Здесь приведены десятичные номера символов, символы, двоичные коды.
Обратите внимание на то, что в этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуйте решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В табл. 3.2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти компьютера текст может быть выведен на экран или на печать в символьной форме. Но для долговременного хранения его следует записать на внешний носитель в виде файла.
Что такое гипертекст
Наиболее существенное отличие компьютерного текста от бумажного вы почувствуете, если встретитесь с текстом, информация в котором организована по принципу гипертекста.
Гипертекст — это текст, организованный так, что его можно просматривать в последовательности смысловых связей между его отдельными фрагментами. Такие связи называются гиперсвязями (гиперссылками).
Чаще всего по принципу гипертекста организованы компьютерные справочники, энциклопедии, учебники. Такую «книгу» можно читать не только в обычном порядке, «листая страницы» на экране, но и перемещаясь по смысловым связям в произвольном порядке. Например, при изучении на уроке физики темы «Второй закон Ньютона» с помощью компьютерного учебника ученик прочитал определение закона «Сила равна произведению массы на ускорение».
Ему захотелось вспомнить определение массы. Указав в тексте на слово «масса» (связанные понятия обычно выделяются цветом или подчеркиванием, а указывать на них удобно с помощью мыши), он быстро перейдет к разделу учебника, где рассказывается о массе тел. Прочитав определение «Масса — мера инертности тела», ученик может пожелать уточнить, что такое инертность. По гиперссылке он быстро выйдет на нужный раздел.
После такой экскурсии вглубь материала ученик может вернуться в исходную точку, щелкнув мышью по кнопке «Назад», так как система запоминает весь маршрут продвижения по гиперссылкам.
Коротко о главном
С помощью компьютера можно создавать текстовые документы и хранить их на носителях внешней памяти в виде файлов.
Преимущества файлового хранения текстов: возможность редактирования, быстрого копирования на другие носители; возможность передачи текста по линиям компьютерной связи.
Каждый символ текста кодируется восьмиразрядным двоичным кодом. Для представления текстов в компьютере используется алфавит мощностью 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код. Международным стандартом является код АSСII — американский стандартный код для информационного обмена.
Гипертекст — это текст, организованный так, что его можно просматривать в последовательности смысловых связей между его отдельными фрагментами. Такие связи называются гиперсвязями (гиперссылками). Гиперссылка позволяет быстро перейти к просмотру того раздела, на который она указывает.
Вопросы и задания
1. В чем преимущества хранения текстов в файлах по сравнению с бумажным способом хранения?
2. Что такое гипертекст? Какие возможности предоставляет гипертекст пользователю?
3. Каков размер алфавита, используемого в компьютерах для представления текстов?
4. Сколько места в памяти занимает код одного символа?
5. Что такое таблица кодировки? Как называется таблица кодировки, используемая в большинстве современных персональных компьютеров?
6. Закодируйте в двоичной форме свою фамилию, записанную латинскими буквами, используя табл. 3.1.
7. Познакомьтесь с альтернативной частью кода АSCII, используемой в школьных компьютерах. Выясните, соблюдается ли принцип последовательного кодирования алфавита из русских букв (их называют кириллицей).
8. Закодируйте короткую фразу на русском языке. Обменяйтесь полученными кодами с соседом по парте и декодируйте тексты друг друга.
Домашнее задание Тексты в компьютерной памяти
Редактировалось Дата:Единицы хранения — бит, байт, полубайт — Byte-Notes
Бит
Наименьшая единица данных в компьютере называется бит (двоичная цифра). Бит имеет одно двоичное значение: 0 или 1. В большинстве компьютерных систем байт состоит из восьми бит. Значение бита обычно сохраняется как выше или ниже заданного уровня электрического заряда в одном конденсаторе в запоминающем устройстве.
полубайт
Полубайт (четыре бита) называется полубайтом .
Байт
В большинстве компьютерных систем байт — это единица данных, состоящая из восьми двоичных цифр. Байт — это единица, которую большинство компьютеров используют для представления символа, такого как буква, цифра или типографский символ (например, «g», «5» или «?»). Байт также может содержать строку битов, которая должна использоваться в некоторой более крупной единице приложений (например, поток битов, составляющих визуальное изображение для программы, которая отображает изображения, или строка битов, составляющая машинный код. компьютерной программы).
В некоторых компьютерных системах четыре байта составляют слово — блок, который компьютерный процессор может быть разработан для эффективной обработки при чтении и обработке каждой инструкции. Некоторые компьютерные процессоры могут обрабатывать двухбайтовые или однобайтовые инструкции.
Байт обозначается буквой «B». (Бит обозначается маленькой буквой «b»). Объем памяти компьютера обычно измеряется в байтах. Например, жесткий диск емкостью 820 МБ вмещает 820 миллионов байтов — или мегабайт — данных. Кратные байты основаны на степенях двойки и обычно выражаются как «округленное» десятичное число.Например, один мегабайт («один миллион байтов») на самом деле равен 1 048 576 (десятичным) байтам.
Октет
В некоторых системах термин октет используется для восьмибитового блока вместо байта. Во многих системах четыре восьмибитовых байта или октета образуют 32-битное слово. В таких системах длины команд иногда выражаются как полное слово (длина 32 бита) или полуслова (длина 16 бит).
Килобайт
килобайт (кбайт или килобайт) составляет приблизительно тысячу байтов (фактически, 2 в 10-й степени -й степени или 1024 байта в десятичной системе).
Мегабайт
В качестве меры памяти процессора компьютера, реальной и виртуальной памяти, мегабайт (сокращенно МБ) составляет от 2 до 20 -го байта мощности, или 1 048 576 байтов в десятичной системе счисления.
гигабайт
Gigabyte (произносится как Gig-a-bite с жесткими буквами G) — это мера емкости хранения компьютерных данных, которая составляет «примерно» миллиард байт. Гигабайт равен двум в степени 30 , или 1 073 741 824 в десятичной системе счисления.
Терабайт
Терабайт — это мера емкости памяти компьютера, которая составляет от 2 до 40 th мощности 1024 гигабайт.
Петабайт
A петабайт (PB) — это мера памяти или емкости хранилища, которая составляет от 2 до 50 -х байтов мощности или, в десятичной форме, приблизительно тысячи терабайт (1024 терабайт).
Эксабайт
Exabyte (EB) — это большая единица хранения компьютерных данных, от двух до шестидесятой степени.Префикс exa означает один миллиард миллиардов или квинтиллион, что является десятичным числом. Два в шестидесятой степени на самом деле составляют 1 152 921 504 606 846 976 байт в десятичной системе счисления или несколько больше квинтиллиона (или десяти в восемнадцатой степени) байтов. Обычно говорят, что экзабайт составляет приблизительно один квинтиллион байтов. В десятичном выражении эксабайт — это миллиард гигабайт.
Зеттабайт
Зеттабайт (ZB) равен одному секстиллиону байтов. Обычно это сокращенно ZB.В настоящее время ни у одного компьютера нет ни одного зеттабайта памяти. Его размер составляет 1024 эксабайта.
Йоттабайт
Yottabyte равен одному септиллиону байтов. Обычно это сокращенно YB. В настоящее время ни у одного компьютера нет ни одного зеттабайта памяти. Его размер — 1024 зеттабайта.
Машинный код— восьмибитная компьютерная документация
Компьютер напрямую управляется машинным кодом. Он хранится в программе объем памяти. Машинный код хранится в виде 8-битных байтов.
Машинный код состоит из байтов команд и байтов констант. Байты инструкций кодировать конкретную инструкцию (например, копирование значения в регистре A в регистр B), константные байты кодируют значение, которое может потребоваться для операции (например, установив регистр A на 42).
Возможны 256 байтов инструкций, большая часть которых занята набор инструкций. Они организованы с использованием описанной ниже группировки. Этот очень вдохновлен тем, как Джеймс Бейтс организовал свой машинный код.
См. Языковую таблицу (или скачать ) для получения полного списка
всего машинного кода и операций с их аргументами. Таблица
можно сортировать, нажимая на заголовки (но это немного медленно).
Группы инструкций
Первые два байта байта инструкции всегда представляют инструкцию группа. Всего 4 группы:
| Битовое значение | Название группы |
|---|---|
00...... | Копия |
01 ...... | нагрузка |
10 ...... | Магазин|
11 ...... | ALU |
Источники и направления
Для инструкций копирования, загрузки и сохранения с третьего по пятый и с шестого по восьмой байты — это источник и место назначения соответственно.
В таблице ниже для краткости показаны только исходные коды.Биты назначения
это последние 3 бита, например: ..... 000 и имеют то же имя и значение.
| Битовое значение | Имя | Значение |
|---|---|---|
..000 ... | ACC | Регистр аккумулятора. |
.,001 ... | А | Регистр A. |
..010 ... | B | Регистр B. |
..011 ... | С | Регистр C. |
. 100 ... | СП | Указатель стека. |
..101 ... | ПК | Счетчик программ |
. 110 ... | SP +/- | Указатель стека, перед которым или за которым следует его увеличение или уменьшение. |
..111... | КОНСТ | Постоянное значение. |
Операции ALU
Имеется 16 операций ALU, и они идентифицируются битами 3-6 байт инструкции, когда группа операций — ALU. Операции и коды:
| Битовое значение | Имя | Значение |
|---|---|---|
110000 .. | НУЛЬ | АЛУ выдаст ноль. |
110001 .. | INCR | Указанный аргумент будет увеличен на 1. |
110010 .. | ОВОС | Указанный аргумент будет уменьшен на 1. |
110011 .. | ДОБАВИТЬ | Аргумент будет добавлен в аккумулятор. |
110100 .. | ADDC | Аргумент будет добавлен в аккумулятор, и один будет добавлен, если последнее добавление привело к переносу. |
110101 .. | ПОД | Аргумент будет вычтен из аккумулятора. |
110110 .. | ПОДБ | Аргумент будет вычтен из аккумулятора, и будет вычтена единица, если последнее вычитание привело к заимствованию. |
110111 .. | И | Аргумент будет соединен оператором AND с аккумулятором. |
111000.. | NAND | Аргумент будет NAND с аккумулятором. |
111001 .. | ИЛИ | Аргумент будет объединен с аккумулятором по ИЛИ. |
111010 .. | НОР | Аргумент будет ИЛИ с аккумулятором. |
111011 .. | XOR | Аргумент будет обработан операцией XOR с аккумулятором. |
111100.. | NXOR | Аргумент будет обработан NXOR с аккумулятором. |
111101 .. | НЕ | В аргументе будут перевернуты все биты |
111110 .. | LSHIFT | Все биты в аргументе переместятся на одну позицию влево (в сторону самого старшего бита) |
111111 .. | LSHIFTC | Все биты в аргументе переместятся на одну позицию влево (в сторону самого старшего бита).Если последний сдвиг привел к переносу, то младший бит устанавливается в 1. |
| 128 | 200 | 80 | 1000 0000 | Ç | заглавная буква c с седилем |
| 129 | 201 | 81 | 1000 0001 | ü | буква U с тремой |
| 130 | 202 | 82 | 1000 0010 | é | буква е с острым ударением |
| 131 | 203 | 83 | 1000 0011 | â | буква А с циркумфлексом |
| 132 | 204 | 84 | 1000 0100 | ä | буква А с тремой |
| 133 | 205 | 85 | 1000 0101 | – | буква А с могилой |
| 134 | 206 | 86 | 1000 0110 | å | буква А с кольцом сверху |
| 135 | 207 | 87 | 1000 0111 | ç | буква c с седилем |
| 136 | 210 | 88 | 1000 1000 | ê | буква е с циркумфлексом |
| 137 | 211 | 89 | 1000 1001 | ë | буква е с тремой |
| 138 | 212 | 8A | 1000 1010 | и | буква е с могилой |
| 139 | 213 | 8Б | 1000 1011 | • | буква i с тремой |
| 140 | 214 | 8C | 1000 1100 | – | буква i с циркумфлексом |
| 141 | 215 | 8D | 1000 1101 | м | буква i с могилой |
| 142 | 216 | 8E | 1000 1110 | Ä | заглавная буква А с тремой |
| 143 | 217 | 8F | 1000 1111 | Å | заглавная буква А с кольцом над |
| 144 | 220 | 90 | 1001 0000 | É | заглавная буква е с острым ударением |
| 145 | 221 | 91 | 1001 0001 | æ | письмо ае |
| 146 | 222 | 92 | 1001 0010 | Æ | заглавная буква ае |
| 147 | 223 | 93 | 1001 0011 | ô | буква o с циркумфлексом |
| 148 | 224 | 94 | 1001 0100 | ö | буква o с тремой |
| 149 | 225 | 95 | 1001 0101 | шт | буква О с могилой |
| 150 | 226 | 96 | 1001 0110 | û | буква U с циркумфлексом |
| 151 | 227 | 97 | 1001 0111 | ù | буква U с могилой |
| 152 | 230 | 98 | 1001 1000 | ÿ | буква у с тремой |
| 153 | 231 | 99 | 1001 1001 | Ö | заглавная буква o с тремой |
| 154 | 232 | 9A | 1001 1010 | Ü | заглавная буква U с тремой |
| 155 | 233 | 9Б | 1001 1011 | ¢ | буква o со штрихом |
| 156 | 234 | 9C | 1001 1100 | £ | знак фунта |
| 157 | 235 | 9D | 1001 1101 | ¥ | знак йены |
| 158 | 236 | 9E | 1001 1110 | ₧ | знак песета |
| 159 | 237 | 9F | 1001 1111 | ƒ | буква f с крючком |
| 160 | 240 | A0 | 1010 0000 | á | буква А с острым углом |
| 161 | 241 | A1 | 1010 0001 | – | буква i с острым ударением |
| 162 | 242 | A2 | 1010 0010 | — | буква О с острым ударением |
| 163 | 243 | A3 | 1010 0011 | ú | буква U с острым ударением |
| 164 | 244 | A4 | 1010 0100 | — | буква n с тильдой |
| 165 | 245 | A5 | 1010 0101 | Ñ | заглавная буква n с тильдой |
| 166 | 246 | A6 | 1010 0110 | ª | женский порядковый указатель |
| 167 | 247 | A7 | 1010 0111 | º | мужской порядковый показатель |
| 168 | 250 | A8 | 1010 1000 | ¿ | перевернутый вопросительный знак |
| 169 | 251 | A9 | 1010 1001 | ⌐ | перевернутый без знака |
| 170 | 252 | AA | 1010 1010 | ¬ | не подписывать |
| 171 | 253 | AB | 1010 1011 | ½ | половина |
| 172 | 254 | AC | 1010 1100 | ¼ | четверть |
| 173 | 255 | н.э. | 1010 1101 | ¡ | перевернутый восклицательный знак |
| 174 | 256 | AE | 1010 1110 | « | двойная угловая кавычка левая |
| 175 | 257 | AF | 1010 1111 | » | двойная угловая кавычка правая |
| 176 | 260 | B0 | 1011 0000 | ░ | светлый оттенок |
| 177 | 261 | B1 | 1011 0001 | ▒ | средний оттенок |
| 178 | 262 | B2 | 1011 0010 | ▓ | темный оттенок |
| 179 | 263 | B3 | 1011 0011 | │ | одинарный вертикальный |
| 180 | 264 | B4 | 1011 0100 | ┤ | одинарный вертикальный и левый |
| 181 | 265 | B5 | 1011 0101 | ╡ | одинарный вертикальный и двойной левый |
| 182 | 266 | B6 | 1011 0110 | ╢ | двойной вертикальный и одинарный левый |
| 183 | 267 | B7 | 1011 0111 | ╖ | двойное вниз и одинарное левое |
| 184 | 270 | B8 | 1011 1000 | ╕ | одинарный вниз и двойной левый |
| 185 | 271 | B9 | 1011 1001 | ╣ | двойной вертикальный и левый |
| 186 | 272 | BA | 1011 1010 | ║ | двойной вертикальный |
| 187 | 273 | BB | 1011 1011 | ╗ | удвоить вниз и влево |
| 188 | 274 | до н.э. | 1011 1100 | ╝ | удвоение и влево |
| 189 | 275 | BD | 1011 1101 | ╜ | двойной и одинарный левый |
| 190 | 276 | BE | 1011 1110 | ╛ | одинарный верхний и двойной левый |
| 191 | 277 | BF | 1011 1111 | ┐ | одинарное вниз и влево |
| 192 | 300 | C0 | 1100 0000 | └ | одинарное вверх и вправо |
| 193 | 301 | C1 | 1100 0001 | ┴ | одинарное вверх и горизонтальное |
| 194 | 302 | C2 | 1100 0010 | ┬ | одинарное вниз и горизонтальное |
| 195 | 303 | C3 | 1100 0011 | ├ | одинарный вертикальный и правый |
| 196 | 304 | C4 | 1100 0100 | ─ | одинарный горизонтальный |
| 197 | 305 | C5 | 1100 0101 | ┼ | одинарные вертикальные и горизонтальные |
| 198 | 306 | C6 | 1100 0110 | ╞ | одинарный вертикальный и двойной правый |
| 199 | 307 | C7 | 1100 0111 | ╟ | двойной вертикальный и одинарный правый |
| 200 | 310 | C8 | 1100 1000 | ╚ | двойная и правая |
| 201 | 311 | C9 | 1100 1001 | ╔ | двойной вниз и вправо |
| 202 | 312 | CA | 1100 1010 | ╩ | двойной и горизонтальный |
| 203 | 313 | CB | 1100 1011 | ╦ | двойной вниз и горизонтальный |
| 204 | 314 | CC | 1100 1100 | ╠ | двойной вертикальный и правый |
| 205 | 315 | CD | 1100 1101 | = | двойной горизонтальный |
| 206 | 316 | CE | 1100 1110 | ╬ | двойной вертикальный и горизонтальный |
| 207 | 317 | CF | 1100 1111 | ╧ | одинарный вверх и двойной горизонтальный |
| 208 | 320 | D0 | 1101 0000 | ╨ | двойной и одинарный горизонтальный |
| 209 | 321 | D1 | 1101 0001 | ╤ | одинарный вниз и двойной горизонтальный |
| 210 | 322 | D2 | 1101 0010 | ╥ | двойной вниз и одинарный горизонтальный |
| 211 | 323 | D3 | 1101 0011 | ╙ | двойной и одинарный правый |
| 212 | 324 | D4 | 1101 0100 | ╘ | одинарный верхний и двойной правый |
| 213 | 325 | D5 | 1101 0101 | ╒ | одинарный вниз и двойной правый |
| 214 | 326 | D6 | 1101 0110 | ╓ | двойной вниз и одинарный правый |
| 215 | 327 | D7 | 1101 0111 | ╫ | двойной вертикальный и одинарный горизонтальный |
| 216 | 330 | D8 | 1101 1000 | ╪ | одинарный вертикальный и двойной горизонтальный |
| 217 | 331 | D9 | 1101 1001 | ┘ | одиночный вверх и влево |
| 218 | 332 | DA | 1101 1010 | ┌ | одинарное вниз и вправо |
| 219 | 333 | DB | 1101 1011 | █ | полный блок |
| 220 | 334 | DC | 1101 1100 | нижняя половина блока | |
| 221 | 335 | DD | 1101 1101 | ▌ | левый полублок |
| 222 | 336 | DE | 1101 1110 | ▐ | правый полублок |
| 223 | 337 | DF | 1101 1111 | ▀ | полублок верхний |
| 224 | 340 | E0 | 1110 0000 | α | греческая буква альфа |
| 225 | 341 | E1 | 1110 0001 | ß | четкая буква s |
| 226 | 342 | E2 | 1110 0010 | Γ | греческая заглавная буква гамма |
| 227 | 343 | E3 | 1110 0011 | π | греческая буква пи |
| 228 | 344 | E4 | 1110 0100 | Σ | греческая заглавная буква сигма |
| 229 | 345 | E5 | 1110 0101 | σ | греческая буква сигма |
| 230 | 346 | E6 | 1110 0110 | µ | микроподпись |
| 231 | 347 | E7 | 1110 0111 | τ | греческая буква тау |
| 232 | 350 | E8 | 1110 1000 | Φ | греческая заглавная буква фи |
| 233 | 351 | E9 | 1110 1001 | Θ | греческая заглавная буква тета |
| 234 | 352 | EA | 1110 1010 | Ом | греческая заглавная буква омега |
| 235 | 353 | EB | 1110 1011 | δ | греческая буква дельта |
| 236 | 354 | EC | 1110 1100 | ∞ | бесконечность |
| 237 | 355 | ED | 1110 1101 | φ | греческая буква фи |
| 238 | 356 | EE | 1110 1110 | ε | греческая буква эпсилон |
| 239 | 357 | EF | 1110 1111 | ∩ | перекресток |
| 240 | 360 | F0 | 1111 0000 | ≡ | идентичен |
| 241 | 361 | F1 | 1111 0001 | ± | знак плюс-минус |
| 242 | 362 | F2 | 1111 0010 | ≥ | больше или равно |
| 243 | 363 | F3 | 1111 0011 | ≤ | меньше или равно |
| 244 | 364 | F4 | 1111 0100 | ⌠ | интегральная верхняя половина |
| 245 | 365 | F5 | 1111 0101 | ⌡ | нижняя половина интегральная |
| 246 | 366 | F6 | 1111 0110 | ÷ | делительный знак |
| 247 | 367 | F7 | 1111 0111 | ≈ | почти равно |
| 248 | 370 | F8 | 1111 1000 | ° | знак градуса |
| 249 | 371 | F9 | 1111 1001 | ∙ | оператор пули |
| 250 | 372 | FA | 1111 1010 | · | средняя точка |
| 251 | 373 | FB | 1111 1011 | √ | корень квадратный |
| 252 | 374 | FC | 1111 1100 | ⁿ | надстрочный индекс n |
| 253 | 375 | FD | 1111 1101 | ² | надстрочный 2 |
| 254 | 376 | FE | 1111 1110 | ■ | черный квадрат |
| 255 | 377 | FF | 1111 1111 | беспрерывное пространство |
индекс | TIOBE — Компания по качеству программного обеспечения
Индекс TIOBE на декабрь 2020 г.
Декабрь Заголовок: Python в четвертый раз становится языком года TIOBE
В следующем месяце TIOBE объявит о своем языке программирования 2020 года.Этот титул получит язык программирования, получивший самый высокий рост рейтингов за год. Python далеко впереди с положительной дельтой + 1,90% на данный момент. Второе место заняли C ++ (+ 0,71%), R (+ 0,60%) и Groovy (+ 0,69%). Вероятность того, что какой-либо язык приблизится к Python в последний месяц года, очень мала. Это означает, что Python, вероятно, выиграет титул в четвертый раз, что является рекордом в истории индекса TIOBE. В этом месяце также произошли некоторые интересные изменения среди 5 языков с высоким потенциалом: Rust переместился с 25 на 21 место, Julia с 30 на 26, Dart с 27 на 31, Kotlin с 36 на 40 и TypeScript с № 43 по № 42.- Пол Янсен — генеральный директор TIOBE Software
Индекс сообщества программистов TIOBE является показателем популярности программирования. языков. Индекс обновляется раз в месяц. Рейтинги основаны на количестве квалифицированные инженеры со всего мира, курсы и сторонние поставщики. Популярные поисковые системы, такие как Google, Bing, Yahoo !, Википедия, Amazon, YouTube и Baidu используются для расчета рейтингов. Важно отметить, что индекс TIOBE — это не лучший язык программирования или язык программирования. в котором написано наибольшее количество строк кода .
Индекс можно использовать, чтобы проверить, актуальны ли ваши навыки программирования, или сделать стратегическое решение о том, какой язык программирования следует принять при создании нового программная система. Определение индекса TIOBE можно найти здесь.
Другие языки программирования
Полные 50 лучших языков программирования перечислены ниже. Этот обзор публикуется неофициально, потому что может случиться так, что мы пропустили язык.Если у вас сложилось впечатление, что отсутствует язык программирования, сообщите нам на [email protected]. Также ознакомьтесь с обзором всех языков программирования, которые мы отслеживаем.
| Положение | Язык программирования | Рейтинги | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21 | Rust | 0,78% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 22 | SAS | 9014 Classic9014 9014 9014 0.71% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 24 | Царапина | 0,67% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 25 | Transact-SQL | 0,59% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 26 | Julia | 0,56% 0,55% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 28 | Логотип | 0,51% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 29 | D | 0,50% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 30 | ABAP | 0,414% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 32 | Фортран | 0,45% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 33 | COBOL | 0,43% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 34 | 4 9014 9014 | 4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 36 | Схема | 0,37% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 37 | Scala | 0,36% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 38 | VHDL | 0,314% | 34%||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 40 | Kotlin | 0,32% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 41 | (Visual) FoxPro | 0,30% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 42 | 0,30% | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 44 | Алиса | 0,28% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 45 | LabVIEW | 0,26% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 46 | ML | 9014 9014 9014 9014 9014 9014 9014 901 .На 25%
| Язык программирования | 2020 | 2015 | 2010 | 2005 | 2000 | 1995 | 1990 | 1985 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | 9014 1 2 | 9014 1 2 9014 1 | 1 | 1 | 1 | |||||||||||||
| Java | 2 | 1 | 1 | 2 | 3 | 29 | — | 4 | 9014 9014 9014 9014 9014 9014 9014 | 6 | 7 | 22 | 13 | — | — | |||
| C ++ | 4 | 3 | 3 | 3 | 41 2 | 2 | 2 | 9014C # | 5 | 4 | 5 | 6 | 10 | — | — | — | ||
| JavaScript 901 44 | 6 | 8 | 10 | 10 | 7 | — | — | — | ||||||||||
| PHP | 7 | 6 | 4 | 4 | 4 | 4 9014 | — | |||||||||||
| SQL | 8 | — | — | — | — | — | — | — | ||||||||||
| 4 R | 9014 9014 9014 9014 9014 9— | — | — | — | ||||||||||||||
| Swift | 10 | 15 | — | — | — | — | — | 9014 9014 9014 9014 9014 9014 9014 9014 9014 9014 9014 9014 9014 9014 26 | 14 | 13 | 9 | 6 | 4 | 2 | ||||
| Фортран | 31 | 21 | 24 | 14 | 13 9 0144 | 14 | 3 | 5 | ||||||||||
| Ada | 34 | 23 | 21 | 16 | 17 | 3 | 9 | Язык 3 | 982 9
| Раздел на 2 | Частное | остаток | Бит # |
|---|---|---|---|
| 13/2 | 6 | 1 | 0 |
| 6/2 | 3 | 0 | 1 |
| 3/2 | 1 | 1 | 2 |
| 1/2 | 0 | 1 | 3 |
Итак 13 10 = 1101 2
Пример # 2
Преобразование 174 10 в двоичное:
| Раздел на 2 | Частное | остаток | Бит # |
|---|---|---|---|
| 174/2 | 87 | 0 | 0 |
| 87/2 | 43 | 1 | 1 |
| 43/2 | 21 | 1 | 2 |
| 21/2 | 10 | 1 | 3 |
| 10/2 | 5 | 0 | 4 |
| 5/2 | 2 | 1 | 5 |
| 2/2 | 1 | 0 | 6 |
| 1/2 | 0 | 1 | 7 |
Итак 174 10 = 10101110 2
Таблица преобразования десятичных чисел в двоичные
| Десятичное Число | Двоичное Число | Hex Число |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | А |
| 11 | 1011 | B |
| 12 | 1100 | С |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
| 16 | 10000 | 10 |
| 17 | 10001 | 11 |
| 18 | 10010 | 12 |
| 19 | 10011 | 13 |
| 20 | 10100 | 14 |
| 21 | 10101 | 15 |
| 22 | 10110 | 16 |
| 23 | 10111 | 17 |
| 24 | 11000 | 18 |
| 25 | 11001 | 19 |
| 26 | 11010 | 1A |
| 27 | 11011 | 1Б |
| 28 | 11100 | 1С |
| 29 | 11101 | 1D |
| 30 | 11110 | 1E |
| 31 | 11111 | 1 этаж |
| 32 | 100000 | 20 |
| 64 | 1000000 | 40 |
| 128 | 10000000 | 80 |
| 256 | 100000000 | 100 |