
Кодирование изображений, звуковой и видеоинформации
Кодирование изображений
Как и все виды информации, изображения в компьютере закодированы в виде двоичных последовательностей. Используют два принципиально разных метода кодирования, каждый из которых имеет свои достоинства и недостатки.
И линия, и область состоят из бесконечного числа точек. Цвет каждой из этих точек нам нужно закодировать. Техника формирования изображений из мелких точек является наиболее распространенной и называется растровой.
Представим себе, что на изображение наложена сетка, которая разбивает его на квадратики. Такая сетка называется растром. Теперь для каждого квадратика определим цвет.
У нас получился так называемый растровый рисунок, состоящий из квадратиков-пикселей.
Определение 1
Пиксель (англ. pixel = picture element, элемент рисунка) – это наименьший элемент рисунка, для которого можно задать свой цвет.
Разбив «обычный» рисунок на квадратики, мы выполнили его дискретизацию – разбили единый объект на отдельные элементы. Действительно, у нас был единый и неделимый рисунок. В результаты мы получили дискретный объект – набор пикселей.
Чтобы уменьшить потери информации, нужно уменьшать размер пикселя, то есть увеличивать разрешение.
Определение 2
Разрешение – это количество пикселей, приходящихся на дюйм размера изображения.
Разрешение обычно измеряется в пикселях на дюйм (используется английское обозначение ppi = pixels per inch). Например, разрешение $254$ ppi означает, что на дюйм ($25,4$ мм) приходится $254$ пикселя, так что каждый пиксель «содержит» квадрат исходного изображения размером $0,1×0,1$ мм. Чем больше разрешение, тем точнее кодируется рисунок (меньше информации теряется), однако одновременно растет и объем файла.
Но кроме растровой графики, в компьютерах используется еще и так называемая векторная графика.
Векторные изображения создаются только при помощи компьютера и формируются не из пикселей, а из графических примитивов (линий, многоугольников, окружностей и др.).
Векторная графика — это чертежная графика. Она очень удобна для компьютерного «рисования» и широко используется дизайнерами при графическом оформлении печатной продукции, в том числе создании огромных рекламных плакатов, а также в других подобных ситуациях. Векторное изображение в двоичном коде записывается как совокупность примитивов с указанием их размеров, цвета заливки, места расположения на холсте и некоторых других свойств.
Пример 1
Например, чтобы записать на запоминающем устройстве векторное изображение круга, компьютеру достаточно в двоичный код закодировать тип объекта (окружность), координаты его центра на холсте, длину радиуса, толщину и цвет линии, цвет заливки.
В растровой системе пришлось бы кодировать цвет каждого пикселя. И если размер изображения большой, для его хранения понадобилось бы значительно больше места на запоминающем устройстве.
Тем не менее, векторный способ кодирования не позволяет записывать в двоичном коде реалистичные фото. Поэтому все фотокамеры работают только по принципу растровой графики. Рядовому пользователю иметь дело с векторной графикой в повседневной жизни приходится не часто.
Кодирование звуковой информации
Определение 3
Любой звук, слышимый человеком, является колебанием воздуха, которое характеризируется двумя основными показателями: частотой и амплитудой. Амплитуда колебаний — это степень отклонения состояния воздуха от начального при каждом колебании. Она воспринимается нами как громкость звука. Частота колебаний — это количество отклонений состояний воздуха от начального за единицу времени. Она воспринимается как высота звука.
Пример 2
Так, тихий комариный писк — это звук с высокой частотой, но с небольшой амплитудой. Звук грозы наоборот имеет большую амплитуду, но низкую частоту.
Схему работы компьютера со звуком в общих чертах можно описать так. Микрофон превращает колебания воздуха в аналогичные по характеристикам электрических колебаний.
Микрофон превращает колебания воздуха в аналогичные по характеристикам электрических колебаний.
Звуковая карта компьютера преобразовывает электрические колебания в двоичный код, который записывается на запоминающем устройстве. При воспроизведении такой записи происходит обратный процесс (декодирование) — двоичный код преобразуется в электрические колебания, которые поступают в аудиосистему или наушники.
Динамики акустической системы или наушников имеют противоположное микрофону действие. Они превращают электрические колебания в колебания воздуха.
Принцип разделения звуковой волны на мелкие участки лежит в основе двоичного кодирования звука. Аудиокарта компьютера разделяет звук на очень мелкие временные участки и кодирует степень интенсивности каждого из них в двоичный код. Такое дробление звука на части называется дискретизацией.
Одной из важных характеристик процесса кодирования звука является частота дискретизации, которая представляет собой количество измерений уровня сигнала за $1$ секунду. Чем выше частота дискретизации, тем точнее фиксируется геометрия звуковой волны и тем качественней получается запись.
Чем выше частота дискретизации, тем точнее фиксируется геометрия звуковой волны и тем качественней получается запись.
В процессе кодирования звуковой информации непрерывный сигнал заменяется дискретным, то есть преобразуется в последовательность электрических импульсов, состоящих из двоичных нулей и единиц.
Качество записи зависит также от количества битов, используемых компьютером для кодирования каждого участка звука, полученного в результате дискретизации. Количество битов, используемых для кодирования каждого участка звука, полученного при дискретизации, называется глубиной звука.
Замечание 1
Чем выше частота и глубина дискретизации звука, тем более качественно будет звучать оцифрованный звук. Самое низкое качество оцифрованного звука, которое соответствует качеству телефонной связи, получается, когда частота дискретизации равна $8000$ раз в секунду, глубина дискретизации $8$ битов, что соответствует записи одной звуковой дорожки (режим «моно»). Самое высокое качество оцифрованного звука, которое соответствует качеству аудио-CD, достигается, когда частота дискретизации равна $48000$ раз в секунду, глубина дискретизации $16$ битов, что соответствует записи двух звуковых дорожек (режим «стерео»).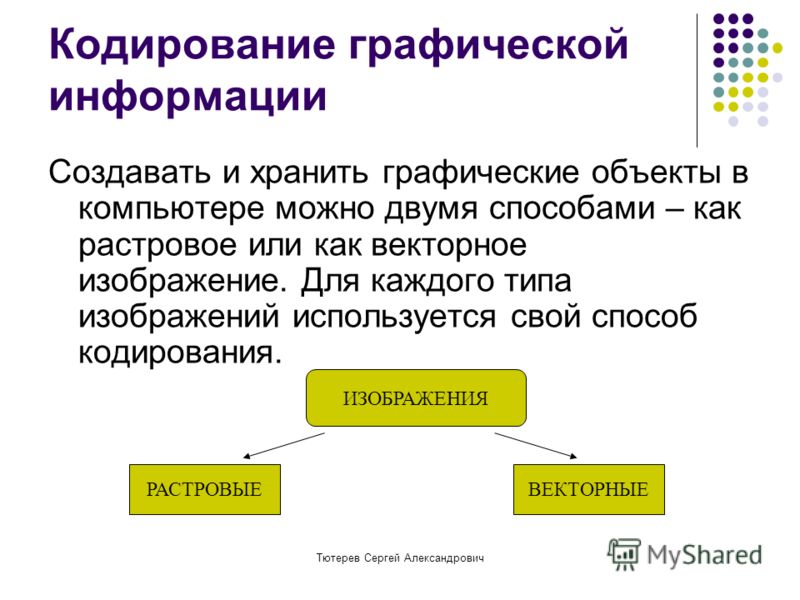
Кодирование видеозаписи
Поскольку видеоинформация состоит из звуковой и графической компоненты, то и для обработки видеоматериалов требуется очень мощный персональный компьютер. Под обработкой видеоматериалов понимается процесс оцифровки, то есть кодирования видеоинформации.
Пример 3
Представим, что в нашем распоряжении есть какая-либо видеоинформация. Любую видеоинформацию можно дифференцировать, то есть разложить на две ключевые составляющие: звуковую и графическую. Следовательно, операция кодирования видеоинформации будет заключаться в сочетании операций кодирования звуковой информации и кодирования графической информации.
Кодирование звуковой дорожки видеофайла в двоичный код осуществляется по тем же алгоритмам, что и кодирование обычных звуковых данных. Принципы кодирования видеоизображения схожи с кодированием растровой графики, хотя и имеют некоторые особенности.
Как известно, видеозапись — это последовательность быстро меняющихся статических изображений (кадров).
Учитывая эту особенность, алгоритмы кодирования видео, как правило, предусматривают запись лишь первого (базового) кадра. Каждый же последующий кадр формируются путем записи его отличий от предыдущего.
После проведения операции цифрования звука и изображений на выходе получается бинарный, двоичный код, который будет понятен процессору персонального компьютера. Именно в формате двоичного кода наша видеоинформация и будет храниться на электронных носителях.
Если мы захотим проиграть видеоконтент на нашем персональном компьютере или другом устройстве, то нам придется провести операцию восстановления информации, то есть осуществить преобразование информации, записанной в двоичном коде в формат понятный человеку.
Замечание 2
Единственное, на чем хотелось бы акцентировать внимание, это на том, что при просмотре видеоинформации мы одновременно и видим «картинку» и слышим звук.
Чтобы добиться синхронного исполнения звука и смены графических изображений, процессор персонального компьютера выполняет эти операции в различных потоках. За счет этого происходит запараллеливание двух сигналов: звукового и графического, которые в совокупности образуют видеопоток.
Кодирование ⚠️ информации: виды, кто кодирует, зачем
Что такое кодирование информации
Кодирование – это процесс преобразования данных из исходной формы представления в коды.
Код – это набор условных символов для представления информации.
К целям использования кодирования относятся:
- компактное хранение, удобство при обработке и передаче информации через автоматические устройства с программным обеспечением;
- удобство при обмене данными между субъектами;
- четкое отображение информации;
- распознавание объектов и субъектов;
- шифровка конфиденциальной информации.


Виды кодирования информации, какие бывают способы изменения вида
Перевести в систему кодов можно текст, цвета, графическое изображение, числа, звук, видео и т.д.
Кодирование текстовой информации
Выделяют 3 основных вида кодирования текста:
- графический – текст переводится в рисунки;
- символьный – преобразование происходит с помощью знаков алфавита, в котором представлен исходный текст;
- числовой – текст кодируется в числа.
Поскольку вся информация представлена в памяти компьютера в двоичной системе, для работы с текстом в ЭВМ используют числовой способ кодирования.
Изначально кодирование символов осуществлялось по 7-битному стандарту. В этой системе вычислительная машина записывала в свою память 128 разных состояний. Каждому из них соответствовала определенная буква, знак или символ.
7-битной системы было недостаточно для записи всех мировых языков. По этой причине создатели программ перешли на 8-битный стандарт, который позволил преобразовать 256 разных знаков.
По этой причине создатели программ перешли на 8-битный стандарт, который позволил преобразовать 256 разных знаков.
Двоичное кодирование предполагает, что каждый знак соответствует уникальному двоичному коду. В стандартном коде информационного обмена ASCII регламентируется присвоение символу такой последовательности. Первые 33 кода – это операции, такие как пробел, ввод и т.п. Коды 33 – 127 соответствуют буквам латинского алфавита, цифрам, арифметическим символам и знакам препинания. Коды 128 – 255 – это буквы национального алфавита.
Впервые русские буквы были закодированы в стандарте КОИ-8 на вычислительных машинах с операционной системой UNIX. На сегодняшний день более широко используется стандартная кодировка Microsoft Windows с обозначением «Кириллица». Русские буквы для операционной системы MS-DOS преобразуются в стандарте СР866. В устройствах серии Macintosh компании Apple – это кодировка Мас. Еще один стандарт для представления русского алфавита – ISO 8859-5.
Неудобство существования разных кодовых языков состоит в том, что они не адаптированы. Следовательно, текст, созданный в одном стандарте, не будет отображаться в другой кодовой системе. Разработчики нашли решение этой проблемы и предусмотрели автоматическую перекодировку текстовой информации при работе с разными кодовыми стандартами.
Следовательно, текст, созданный в одном стандарте, не будет отображаться в другой кодовой системе. Разработчики нашли решение этой проблемы и предусмотрели автоматическую перекодировку текстовой информации при работе с разными кодовыми стандартами.
Для работы в интернете применяют международную кодировку Unicode. В отличие от 8-битного стандарта, для преобразования символов использует 2 байта, а не 1. Это позволяет закодировать 65536 различных символов.
Кодирование цвета
Основой всех цветов являются красный, зеленый и синий. На этом свойстве базируется одна из моделей представления цветового разнообразия, названная по первым буквам данных цветов RGB (red, green, blue). Этот стандарт использует всего 3 байта, по одному на каждый цвет. При единице цвет включен, при нуле – выключен. Из трех базовых цветов можно составить 8 двоичных кодов , значит, 8 разных цветов: красный, зеленый синий, желтый, белый, голубой, лиловый, черный.
Для управления яркостью вводят еще один бит, и получается модель IRGB (от английского Intensity – интенсивность). При этом образуются 8 дополнительных кодов, соответственно, цветовая гамма расширяется до 16 оттенков. Добавляются серый, ярко-синий, ярко-зеленый, ярко-голубой, ярко-красный, ярко-лиловый, ярко-желтый, ярко-белый.
При этом образуются 8 дополнительных кодов, соответственно, цветовая гамма расширяется до 16 оттенков. Добавляются серый, ярко-синий, ярко-зеленый, ярко-голубой, ярко-красный, ярко-лиловый, ярко-желтый, ярко-белый.
Создание более богатой палитры осуществляется в 6-битной системе, называемой RrGgBb. Код 00 означает, что цвет выключен, 01 – это слабый цвет, 10 – обычный оттенок и 11 – интенсивный. В этом случае можно закодировать 64 цвета. Несмотря на это, на экране параллельно могут отражаться до 16 оттенков, поскольку кодирование в кадровом буфере происходит в 4-битной системе. Представление цвета в RrGgBb применяется на видеоадаптерах EGA.
Еще более широкая гамма доступна в видеоинтерфейсе VGA. Благодаря отведению 6 байт на шифровку каждого основного цвета, количество тонов увеличилось до 256 тыс. Из них на экране одновременно отражается максимум 256 оттенков, так как видеобуфер использует 8-битное преображение информации.
В принтерах используется иная цветовая модель – CMYK. Она базируется на голубом, фиолетовом, желтом и черном цветах (Cyan, Magenta, Yellow, Key color – обозначение черного цвета). Так как эти тона получены при вычитании из белого основных цветов, модель называется субстрактивной.
Она базируется на голубом, фиолетовом, желтом и черном цветах (Cyan, Magenta, Yellow, Key color – обозначение черного цвета). Так как эти тона получены при вычитании из белого основных цветов, модель называется субстрактивной.
Выбор такой цветовой модели для полиграфии объясняется техническим удобством. Так как печать производится на бумаге, нужно учитывать свойство поверхности отражать. В этом случае проще считать, сколько света отразилось, чем поглотилось.
Кодирование графической информации
Представление графической информации в компьютерах подразделяется на два формата:
- растровая графика;
- векторная графика.
Растровый формат можно назвать точечным. Расположенные строго по строкам и столбцам точки имеют отдельные координаты нахождения на дисплее, цвет и уровень интенсивности. Качество изображения напрямую зависит от количества точек – чем их больше, тем картинка качественнее. Растровый способ кодирования подходит для фотографий.
Векторная графика опирается на закодированные геометрические фигуры. В числовой формат приведены размеры объектов, координаты вершин, толщина контуров цвет заливки. Векторное кодирование удобно применять при создании рекламной продукции.
Кодирование числовой информации
Числа в памяти вычислительных машин хранятся в двоичной системе счисления. Выделяют два способа представления чисел:
- форма с фиксированной точкой – для целых чисел;
- форма с плавающей точкой – для действительных чисел.
Целочисленные значения в компьютере представлены с фиксированной запятой.
Целое положительное число переводят в двоичную систему счисления. К полученному коду приписывают 2 нуля слева. Крайний разряд слева в положительном числе равен 0.
Целое отрицательное число преобразуется следующим образом. Число без минуса переводят в двоичную систему, дополняют его нулями слева. Образовавшийся код переводят в обратный, заменяя нули единицами, а единицы – нулями. К полученной комбинации чисел прибавляют 1.
К полученной комбинации чисел прибавляют 1.
Порядок кодирования действительного или вещественного числа выглядит следующим образом. Число десятичной системы счисления переводят в двоичную. Определяют так называемую мантиссу числа: перемещают запятую в нужную сторону, чтобы слева не было ни одной единицы. Далее определяют значение порядка – количество знаков, на которое перемещена запятая для определения мантиссы.
Кодирование звуковой информации
Звук – это волны с постоянно меняющейся частотой и интенсивностью, вызванные колебанием частиц. Человек распознает звук благодаря меняющемуся давлению акустической волны на препятствия. Громкость звука зависит от акустики звуковой волны, а тон – от частоты.
При оцифровке непрерывная акустическая волна временно превращается в прерывистую. Дискретная форма представляет собой короткие отрезки с неизменным сигналом.
Частота дискретизации – количество измерений громкости в секунду.
Глубина кодирования звука – количество данных, необходимое для преобразования прерывистых уровней громкости звукового сигнала.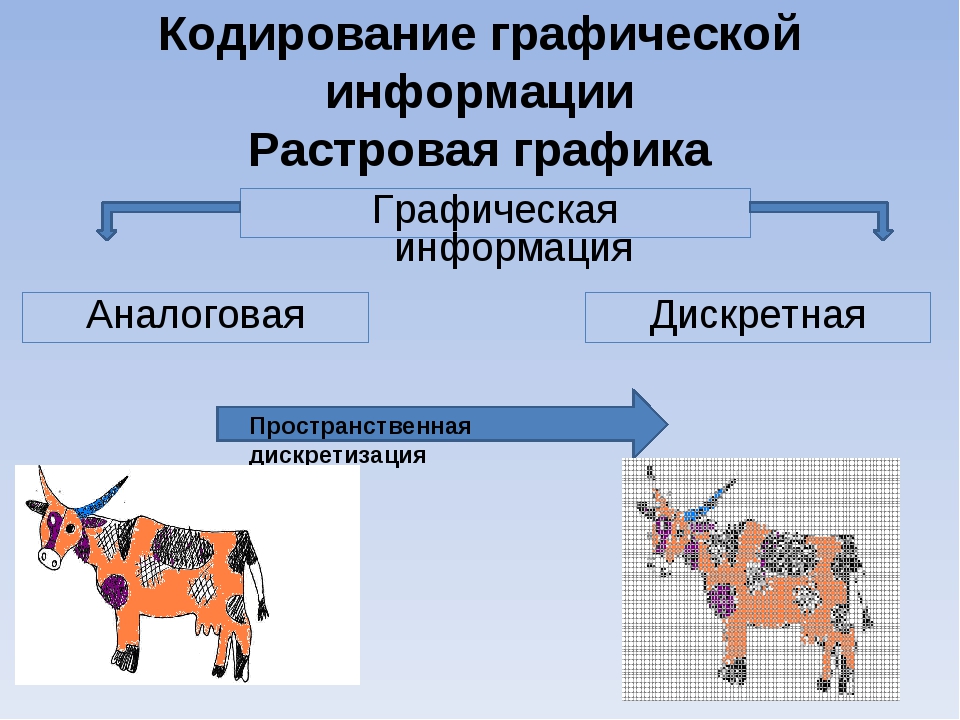
От частоты дискретизации глубины кодирования звука зависит точность воспроизведения оригинального звука. Чем выше эти показатели, тем корректнее представление звуковой информации.
Кодирование видеозаписи
Видеофайл состоит из звукового элемента и графического изображения, поэтому эти составляющие подвергаются раздельной кодировке.
Принципы преобразования звука видеозаписи в двоичную систему аналогичны с кодированием обычной звуковой информации.
Последовательность кодирования графики также схожа с переводом обычного изображения в двоичный код. В случае с видео шифруется лишь первый кадр. Последующие изображения преобразуются относительно предыдущей картинки посредством записи изменений.
По завершении процесса кодирования звуковой дорожки и графики получается двоичный код для хранения в памяти ПК и других электронных носителях. Синхронность воспроизведения видеозаписи осуществляется путем разделения этих операций.
Кодирование графической и мультимедийной информации | Презентация к уроку по информатике и икт (9 класс) на тему:
Слайд 1
Кодирование графической информации Орлова Елена Альбертовна учитель информатики и ИКТ ГОУ СОШ №451 Санкт-ПетербургСлайд 2
Графическая информация может быть представлена в аналоговой и дискретной форме живописное полотно цифровая фотография
Слайд 3
Примером аналогового представления информации может служить живописное полотно, цвет которого изменяется непрерывно
Слайд 4
Дискретное изображение состоит из отдельных точек лазерный принтер струйный принтер
Слайд 5
Преобразование изображения из аналоговой (непрерывной) в цифровую (дискретную) форму называется пространственной дискретизацией Аналоговая форма Дискретная форма сканирование
Слайд 6
В процессе пространственной дискретизации изображение разбивается на отдельные маленькие фрагменты, точки — пиксели пиксель
Слайд 7
Пиксель – минимальный участок изображения, для которого независимым образом можно задать цвет.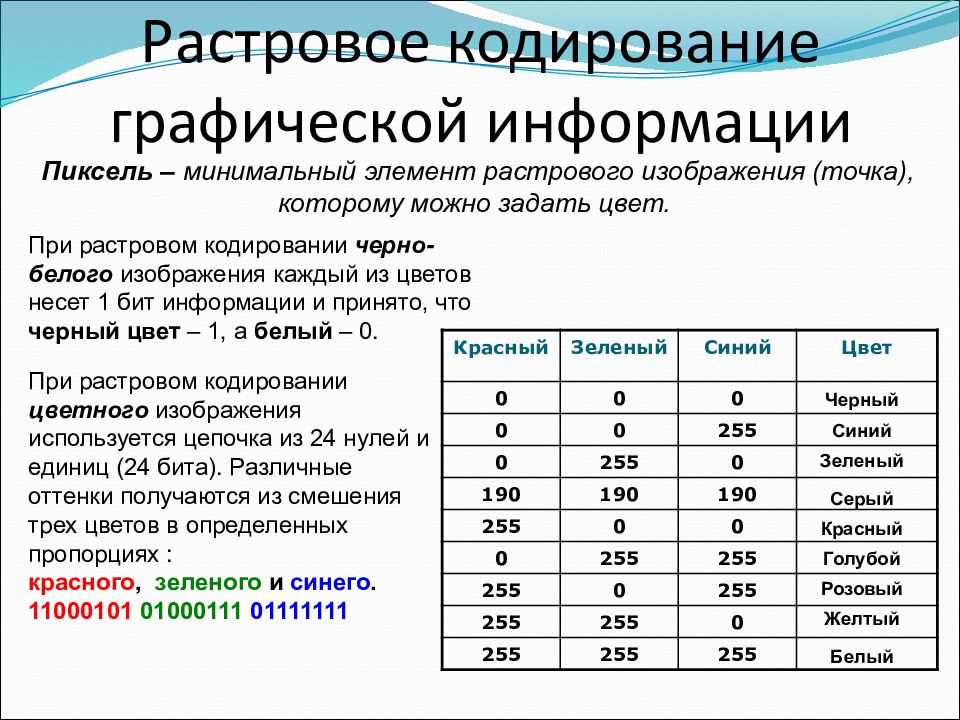 В результате пространственной дискретизации графическая информация представляется в виде растрового изображения.
В результате пространственной дискретизации графическая информация представляется в виде растрового изображения.
Слайд 8
Разрешающая способность растрового изображения определяется количеством точек по горизонтали и вертикали на единицу длины изображения.
Слайд 9
Чем меньше размер точки, тем больше разрешающая способность, а значит, выше качество изображения. Величина разрешающей способности выражается в dpi ( dot per inch – точек на дюйм), т.е. количество точек в полоске изображения длиной один дюйм (1 дюйм=2,54 см.)
Слайд 10
В процессе дискретизации используются различные палитры цветов (наборы цветов, которые могут принять точки изображения). Количество информации, которое используется для кодирования цвета точки изображения, называется глубиной цвета . Количество цветов N в палитре и количество информации I , необходимое для кодирования цвета каждой точки, могут быть вычислены по формуле: N = 2 I
Слайд 11
Пример: Для кодирования черно-белого изображения (без градации серого) используются всего два цвета – черный и белый. По формуле N=2 можно вычислить, какое количество информации необходимо, чтобы закодировать цвет каждой точки: I 2=2 I 2=2 1 I = 1 бит Для кодирования одной точки черно-белого изображения достаточно 1 бита.
По формуле N=2 можно вычислить, какое количество информации необходимо, чтобы закодировать цвет каждой точки: I 2=2 I 2=2 1 I = 1 бит Для кодирования одной точки черно-белого изображения достаточно 1 бита.
Слайд 12
Зная глубину цвета, можно вычислить количество цветов в палитре. Глубина цвета, I (битов) Количество цветов в палитре, N 8 2 = 256 16 2 = 65 536 24 2 = 16 777 216 8 16 24 Глубина цвета и количество цветов в палитре
Слайд 13
1. Растровый графический файл содержит черно-белое изображение с 16 градациями серого цвета размером 10х10 пикселей. Каков информационный объем этого файла? Задачи: Решение: 16 = 2 ; 10*10*4 = 400 бит 2. 256-цветный рисунок содержит 120 байт информации. Из скольких точек он состоит? Решение : 120 байт = 120*8 бит; 265 = 2 (8 бит – 1 точка). 120*8/8 = 120 8 4
Слайд 14
Качество растровых изображений, полученных в результате сканирования, зависит от разрешающей способности сканера. Оптическое разрешение – количество светочувствительных элементов на одном дюйме полоски Аппаратное разрешение – количество « микрошагов » светочувствительной полоски на 1 дюйм изображения например, 1200 dpi например, 2400 dpi
Слайд 15
Растровые изображения на экране монитора Качество изображения на экране монитора зависит от величины пространственного разрешения и глубины цвета. определяется как произведение количества строк изображения на количество точек в строке характеризует количество цветов, которое могут принимать точки изображения (измеряется в битах)
определяется как произведение количества строк изображения на количество точек в строке характеризует количество цветов, которое могут принимать точки изображения (измеряется в битах)
Слайд 16
Формирование растрового изображения на экране монитора 1 2 3 4 ………………………………….. 800 2 3 600 ….………. Всего 480 000 точек Видеопамять Номер точки Двоичный код цвета точки 1 01010101 2 10101010 ….. 800 11110000 ….. 480 000 11111111
Слайд 17
Белый свет может быть разложен при помощи природных явлений или оптических приборов на различные цвета спектра: — красный — оранжевый — желтый — зеленый — голубой — синий — фиолетовый
Слайд 18
Человек воспринимает цвет с помощью цветовых рецепторов (колбочек), находящихся на сетчатке глаза. Колбочки наиболее чувствительны к красному , зеленому и синему цветам.
Слайд 19
Палитра цветов в системе цветопередачи RGB В системе цветопередачи RGB палитра цветов формируется путём сложения красного , зеленого и синего цветов.
Слайд 20
Цвет палитры Color можно определить с помощью формулы: Color = R + G + В При этом надо учитывать глубину цвета — количество битов, отводимое в компьютере для кодирования цвета. Для глубины цвета 24 бита (8 бит на каждый цвет ): 0 ≤ R ≤ 255, 0 ≤ G ≤ 255, 0 ≤ B ≤ 255
Для глубины цвета 24 бита (8 бит на каждый цвет ): 0 ≤ R ≤ 255, 0 ≤ G ≤ 255, 0 ≤ B ≤ 255
Слайд 21
Формирование цветов в системе цветопередачи RGB Цвета в палитре RGB формируются путём сложения базовых цветов, каждый из которых может иметь различную интенсивность. Цвет Формирование цвета Черный Black = 0 + 0 + 0 Белый While = R max + G max + B max Красный Red = R max + 0 +0 Зеленый Green = 0 + G max + 0 Синий Blue = 0 + 0 + B max Голубой Cyan = 0+ G max + B max Пурпурный Magenta = R max + 0 + B max Желтый Yellow = R max + G max + 0
Слайд 22
Система цветопередачи RGB применяется в мониторах компьютеров, в телевизорах и других излучающих свет технических устройствах.
Слайд 23
Палитра цветов в системе цветопередачи CMYK В системе цветопередачи CMYK палитра цветов формируется путём наложения голубой , пурпурной , жёлтой и черной красок .
Слайд 24
Формирование цветов в системе цветопередачи С MYK Цвет Формирование цвета Черный Black = C + M + Y = W – G – B – R = K Белый While = (C = 0, M = 0, Y = 0) Красный Red = Y + M = W – G – B = R Зеленый Green = Y + C = W – R – B = G Синий Blue = M + C = W – R – G = B Голубой Cyan = C = W – R = G + B Пурпурный Magenta = M = W – G = R + B Желтый Yellow = Y = W – B = R + G Цвета в палитре CMYK формируются путем вычитания из белого цвета определенных цветов.
Слайд 25
Цвет палитры Color можно определить с помощью формулы: Color = С + M + Y Интенсивность каждой краски задается в процентах: 0% ≤ С ≤ 100%, 0% ≤ М ≤ 100%, 0% ≤ Y ≤ 100% Смешение трех красок – голубой, желтой и пурпурной – должно приводить к полному поглощению света, и мы должны увидеть черный цвет. Однако на практике вместо черного цвета получается грязно-бурый цвет. Поэтому в цветовую модель добавляют еще один, истинно черный цвет – bla К. Расширенная палитра получила название CMYK .
Слайд 26
Система цветопередачи CMYK применяется в полиграфии.
Слайд 27
Задачи: Рассчитайте объём памяти, необходимый для кодирования рисунка, построенного при графическом разрешении монитора 800х600 с палитрой 32 цвета. 2. Какой объем видеопамяти необходим для хранения четырех страниц изображения при условии, что разрешающая способность дисплея 640х480 точек, а глубина цвета 32? Решение : 800*600*5 бит = 2400000 бит : 8 : 1024 = 293 Кбайт Решение: 640*480*5*4 = 6144000 бит : 8 : 1024 = 750 Кбайт
Слайд 28
Домашнее задание: Учебник Н. Д.Угринович , 9 класс § 1.1.1, § 1.1.2 , § 1.1.3 задания 1.1 – 1.7
Д.Угринович , 9 класс § 1.1.1, § 1.1.2 , § 1.1.3 задания 1.1 – 1.7
Кодирование графической информации
Помогаю школьникам подготовиться к экзамену ОГЭ и ЕГЭ по информатике
Всем привет! Меня зовут Александр. Я — репетитор по информатике, математике, программированию, базам данных, а также автор данной статьи.
Ключевой профиль моей педагогической деятельности — подготовка школьников $9$-х — $11$-х классов к успешной сдаче ОГЭ и ЕГЭ по информатике.
Возникли проблемы с заданием, ориентированным на кодирование графической информации? Записывайтесь ко мне на индивидуальный урок по информатике и ИКТ. На занятии мы с вами погрузимся в область, связанную с кодированием графической информации, и прорешаем колоссальное количество всевозможных тематических примеров.
Свои частные уроки я провожу в различных территориальных форматах:
Но настоятельно рекомендую остановить свой выбор на дистанционном формате, посредством программы «Skype«. Это очень удобно, недорого и крайне эффективно.
Это очень удобно, недорого и крайне эффективно.
Звоните и записывайтесь на «пробник» прямо сейчас! Мой контактный номер телефона можно заметить в шапке данного сайта. Количество ученических мест ограниченно, еще $2-3$ человека смогу взять в этом месяце, но не больше.
Общие сведения о графической информации
Графическая информация изучена специалистами вдоль и поперек. Данная тема очень глубокая и достаточно сложная, следовательно, мы коснемся лишь самых фундаментальных понятий, которые пригодятся вам при решений заданий на ЕГЭ по информатике и ИКТ.
| Под графической информацией следует понимать всю совокупность информации, которая нанесена на всевозможные носители – бумагу, стену, кальку, холст, полотно (список можно продолжать практически до бесконечности) |
Если оглянуться и посмотреть на объекты, расположенные вокруг себя, то становится очевидным тот факт, что каждый предмет в той или иной степени имеет определенный цвет. В мире существует огромное количество графических носителей и различных видов изображений.
В мире существует огромное количество графических носителей и различных видов изображений.
В мире графической информации есть одна очень неприятная неопределенность. Например, посмотрите на стену своей комнаты. Если на стене наклеены обои, то они имеют определенный цвет, если плитка, то она также имеет какую-то цветовую палитру, если стена голая, то есть без какого-либо покрытия, то она также имеет цвет, присущий материалу, из которого она сделана.
Подумайте, а можно ли каким-либо образом охарактеризовать графическую информацию, которую мы видим, выделить какие-либо универсальные элементы, из которых создана это графическая информация? Очевидно, что нет!
В противовес примеру с графической информацией давайте рассмотрим абсолютно произвольный фрагмент текста. Например, текущий абзац. Сразу становится очевидным, что текст можно разбить на универсальные элементы, которые являются отдельными символами. И что очень важно – количество этих элементов конечно.
Все используемые символы в текстовых материалах кодируются при помощи специальных кодировочных таблиц. С графической информацией все гораздо сложнее, ее сложно разбить на отдельное количество универсальных составляющих, из которых можно получить абсолютно любое изображение.
С графической информацией все гораздо сложнее, ее сложно разбить на отдельное количество универсальных составляющих, из которых можно получить абсолютно любое изображение.
Свойства графической информации
Дать характеристику свойствам графической информации не совсем просто, как может показаться на первый взгляд. Чтобы лучше понять данные свойства посмотрите на произвольный объект в комнате или в любом другом месте.
Наличие палитры цветов. На какой бы предмет не упал ваш взор графическая информация, которая «нанесена» на данный предмет, обладает каким-либо цветом. Цветовая палитра – фиксированный набор цветов и оттенков, который имеет физическую реализацию в том или ином представлении.
Наличие занимаемой площади. Любой предмет в нашем мире имеет $3$ измерения. Это означает, что мы живем в трехмерном мире, который характеризуется тремя измерениями: длиной, шириной и высотой. Любая графическая информации при нанесении занимает определенную площадь, будь то чертеж, пейзаж или наскальный рисунок.
Наличие поверхности. Данное свойство вытекает из свойства под номером $2$. Физически не получится скомпилировать графическое изображение, если под данное изображение не будет выделена какая-либо поверхность. Поверхности бывают различной конфигурации: плоские и пространственные. Если мы проведем линию определенного цвета, то даже этот геометрический примитив в физическом мире будет обладать длиной и шириной.

Я думаю, что у вас есть контраргументы относительно выше приведенных $3$-х свойств графической информации.
Вы скажите, что черная дыра является невидимой. На самом деле черная дыра – абсолютно черное тело, следовательно, ее поверхность не отражает световые волны. Черная дыра поглощает безвозвратно абсолютно любую, падающую на ее поверхность волну.
Очень часто в различных научных источниках приводятся обобщенные свойства информации:
| объективность | актуальность | адекватность |
| полнота | достоверность | полезность |
И данные свойства начинают приписывать графической информации. Но правильно ли это? Давайте разберемся!
Но правильно ли это? Давайте разберемся!
Допустим, вы берете белый чистый лист бумаги и рисуете на поверхности листа фигуру, похожую на треугольник синего цвета. Также вы заливаете внутреннюю поверхность отрисованной фигуры синим цветом.
Является ли данная графическая информация объективной? Этого мы не можем оценить. Автор просто воплотил свою идею.
Является ли данная графическая информация полезной? Кому как, чисто индивидуально будет оцениваться пользователями.
Обладает ли синяя фигура свойством адекватности? Сказать сложно, чисто индивидуально будет оцениваться.
И так можно пройтись по каждому свойству. Как видите, общепринятые свойства информации не распространяются на графическую информацию в полной степени.
Виды компьютерной графики
Компьютерная графика — это одно из направлений информатики, которая изучает методы и способы создания и редактирования изображений при помощи специализированных программ, а также позволяет оцифровать визуальную информацию, взятую из реального мира. |
Для успешной сдачи ЕГЭ по информатике, конечно, нет большой необходимости погружаться во все тонкости этой сферы. Особое внимание лишь стоит уделить кодированию растровых изображений.
Растровая графика (используется в заданиях ЕГЭ по информатике)
Часто можно услышать фразу: «Растровое изображение» или «Картинка в растре». Что это значит? Все достаточно просто!
Если мы имеем в наличии растровое изображение, то по факту нам предстоит работать с двухмерным массивом точек (графическая матрица), называемых пикселями. То есть растровое изображение — мозаика, каждый элемент которой закрашен определенным цветом. Также каждый пиксель изображения, помимо цвета, еще имеет координты.
Файлы, хранящие растровые изображения, имеют следующие расширения:
| *.bmp | *.tif | *.jpg | *.gif | *.png |
Как видите, все графические файлы, с которыми вы сталкивайтесь в повседневной жизни, оказывается имеют растровую природу.
Самый громадный недостаток растровой графики заключается в том, что при изменении габаритов картинки, как правило, при увеличении, существенно падает качество отображения.
Связано это с тем, что при увеличении габаритов, нужно добавлять новые пиксели, а поскольку их цвет точно неизвестен, то при помощи аппроксимации им назначаются схожие цвета. Изображение резко теряет в качестве, появляются «ступеньки» и угловатости.
Векторная графика
Во-первых, с векторной графикой, с вероятностью $99.9\%$, на официальном экзамене ЕГЭ по информатике вы не столкнетесь. Практически все задания на кодирование графической информации ориентированы на растровую графику.
Во-вторых, анатомия изображений «в векторе» кардинально отличается от анатомии изображений «в растре».
В векторной графике изображения состоят из простейших графических примитивов, таких как:
| точка | линия | окружность | сплайн | кривая Безье | многоугольник |
Иногда векторную графику называют математической графикой! Думаю, что теперь вы знаете, почему.
Векторная графика обладает рядом преимуществ по сравнению с растровой графикой:
Картинка «в векторе» занимает незначительный объем памяти на жестком диске.
При масштабировании векторного изображения его качество остается неизменно высоким.
Используя специальные компьютерные программы, достаточно легко вносить правки в структуру векторного изображения.
Думаю, что для общего введения, этой информации про векторную графику достаточно. В любом случае на ЕГЭ вам не придется иметь дело с кодированием изображения «в векторе», менять формулу, описывающую сплайн, или наклон и ширину прямой линии.
Фрактальная графика
Напишу буквально несколько слов лишь для повышения вашего «графического» кругозора. На ЕГЭ по информатике вы $100\%$ не столкнетесь с кодированием этого типа графики.
Фрактальная графика в настоящий момент времени очень быстро развивается и является одной из самых перспективных видов компьютерной графики. Этот тип графики сумел объединить математику и искусство, математику и красоту живой природы.
Этот тип графики сумел объединить математику и искусство, математику и красоту живой природы.
Логично предположить, что фрактальная графика состоит из фракталов.
| Фрактал — это структура гомотетичных/подобных объектов. |
То есть изображение состоит из одинаковых фигур разного размера, наклона, ширины. Но математически описываются они все одинаково. То есть, если мы рассмотрим один элемент изображения, какой-то один фрактал и изучим его, то мы получим информацию обо всем изображении.
Главное направление фрактальной графики — создание красивейших абстрактных композиций живой/неживой природы.
Посмотрите, какая красота! На самом деле все лепестки этого цветка описываются одной и той же формулой. Просто подставляются разные коэффициенты. В это трудно поверить, не правда ли…
Принцип кодирования изображений растровой графики
Любая информация, которую способна обрабатывать электронно-вычислительная система, должна быть представлена в двоичном виде, наборе. Двоичный набор, код – цепочки различной длины, состоящие исключительно из $0$ и $1$.
Двоичный набор, код – цепочки различной длины, состоящие исключительно из $0$ и $1$.
Наша задача – понять, какие действия производит персональный компьютер над графическим изображением для того, чтобы на выходе получались наборы из $0$ и $1$.
Представим, что компьютеру на вход подано какое-либо изображение. В данном примере под «компьютером» следует понимать некое подобие сканера. В первую очередь необходимо провести операцию, называемую дискретизацией.
| Дискретизация – разбивка изображения на одинаковые элементы, которые не являются универсальными. В качестве разбивочного элемента принимается обыкновенный квадрат. |
Если очень грубо, то на поверхность исследуемого изображения накладывается матричная сетка, ячейками которой являются квадраты. Чем мельче сетка, тем точнее в будущем можно будет закодировать графическую информацию. В данном процессе «миллионы» деталей, но необходимо дополнительно понимать, что каждый элемент матричной сетки будет иметь уникальные координаты на плоскости.
Дискретизация при кодировании графической информации
Во вторую очередь необходимо осуществить операцию, называемую квантованием.
| Квантование — операция оценки каждого элемента матричной сетки с некоторой заранее заданной шкалой. |
Что выступает в качестве подобной шкалы? Ответ: под шкалой следует понимать таблицу, которая состоит из конечного набора различных цветов и их бинарных соответствий.
Модель RGB и глубина цвета
Как известно, абсолютно любой цвет можно получить сочетанием в некоторых пропорциях трех базовых цветов: красного, зеленого и синего. Аббревиатуру RGB можно расшифровать как:
Минимальный неделимый элемент графического изображения на экране пользователя называется пикселем. |
Под разрешением монитора персонального компьютера следует понимать величину, которая определяет, сколько пикселей можно разместить на площади данного монитора. Чем больше пикселей вмещается на площадь экрана, тем четче и качественнее будет графическое отображение.
В настоящий момент времени различными профессиональными сообществами ведется статистика (на $2019$ год), отражающая, наиболее популярные разрешения экранов у пользователей, пользующихся Интернетом.
В таблице ниже я приведу лишь ТОП-$3$ самых популярных разрешений мониторов:
| № | Разрешение в пикселях | % пользователей |
| $1$ | $360 • 640$ | $18.11\%$ |
| $2$ | $1366 • 768$ | $15.66\%$ |
| $3$ | $1920 • 1080$ | $12. 32\%$ 32\%$ |
P.S. Разрешение моего экрана настроено на размер $1920 • 1080$. Чего и вам рекомендую.
| Глубина цвета – величина, отвечающая за объем памяти, который необходим при кодировании одного пикселя. |
Очень важно понимать, что влияет на глубину цвета. На глубину цвета влияет возможное количество различных цветов, которые может принимать пиксел при кодировании графической информации.
А от чего зависит количество различных цветов? Это количество в модели RGB зависит от того, сколько бит памяти выделяется на кодирование базового цвета. Напомню, что базовыми являются три цвета: красный, зеленый и синий.
Допустим, что на кодирование одного базового цвета отводится $1$ байт или $8$ бит информации.
| R (красный) | G (зеленый) | B (синий) |
| $8$ бит ($1$ байт) | $8$ бит ($1$ байт) | $8$ бит ($1$ байт) |
Говорят, что мы работаем с $24$-х битной моделью RGB при кодировании графической информации.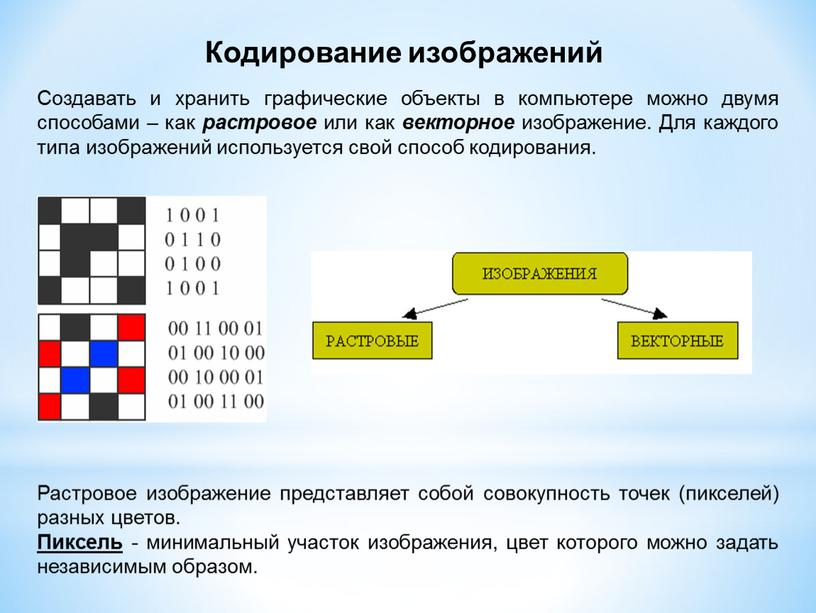 8 = 16\ 777\ 216$ различных оттенков цвета.
8 = 16\ 777\ 216$ различных оттенков цвета.
| При кодировании графической информации абсолютно каждому цвету из набора, состоящего из $16\ 777\ 216$ различных цветов, ставится в соответствии некий уникальный бинарный код, длина которого составляет $24$ бита. |
Итак, мы производим кодирование графической информации на уровне $24$-х битной RGB модели. Допустим, что происходит анализ идеально красного изображения. Все пикселы данного изображения будут красного цвета и будут кодироваться идентичным бинарным кодом.
Давайте посмотрим битовое представление пиксела идеально красного цвета.
Цвет для кодирования | Цвет, преобразованный в бинарный код |
| 11111111 00000000 00000000 |
В полученном двоичном коде первые $8$ бит отвечает за красную составляющую, средние $8$ бит – за зеленую составляющую, последние $8$ бит – за синюю составляющую.
Поскольку мы рассматриваем кодирование графической информации, выраженной идеально красным цветом, то биты, отвечающие за красный цвет имеют значение равное $1$, а остальные – равное $0$.
Вернемся к операции квантования, которую начали рассматривать выше. Мы провели операцию дискретизации, то есть наложили сетку. Далее производим анализ каждого элемента, ячейки данной сетки.
Анализ заключается в том, чтобы цвету, находящемуся в данной ячейки сопоставить соответствующее бинарное значение, которое хранится в специальной шкале.
На этом процедура кодирования графической информации считается завершенной.
Хочу обратить пристальное внимание на тот факт, что задания на кодирование графической информации, встречающиеся на ЕГЭ, оперирует зачастую именно $24$-х битной RGB моделью.
Цветовая палитра
Цветовая палитра – строго определенный набор цветов и оттенков, имеющий цифровую реализацию в том или ином виде.
Существует три основных палитры цветов:
RAL
NCS
Pantone
RAL — самая популярная цветовая палитра. Данную палитру используют при создании программного обеспечения. Палитра NCS нашла свое применение в промышленности для описания цвета продукции. Палитра Pantone в основном используется в полиграфической промышленности.
Задачи на кодирование графической информации, встречающиеся на ЕГЭ по информатике
Рассмотрим решение задачи из ДЕМО-варианта ЕГЭ по информатике $2020$ года. Это задание под $№9$.
Условие задачи. Для хранения произвольного растрового изображения размером $128 • 320$ пикселей отведено $40$ Кбайт памяти без учета размера заголовка файла. Для кодирования цвета каждого пикселя используется одинаковое количество бит, коды пикселей записываются в файл один за другим без промежутков. Вопрос. |
 Какое максимальное количество цветов можно использовать в изображении?
Какое максимальное количество цветов можно использовать в изображении?Решение. Как я и говорил выше, практически все задания из ЕГЭ по информатике ориентированы на кодирование растровой графики. Известно, чем больше памяти отводится на кодирование $1$-го пиксела, тем большим количеством цветов его можно закрасить.
Поэтому, наша задача — определить, сколько памяти отводится на кодирование $1$-го пиксела заданного изображения.
Из условия задачи мы знаем общее количество пикселов, из которого состоит исходное изображение: $128 • 320$. Также из условия задачи мы знаем общий размер памяти, который отводится под исходное изображение: $40$ Кбайт.
Поэтому, давайте найдем, сколько бит памяти отводится под один конкретный пиксель, то есть найдем глубину цвета $I$. Очень желательно получить результат именно в битах, а не байтах, килобайтах и т.п.
$<Память,\ занимаемая\ $1$-им\ битом>\ =\ \frac{<Общий\ размер\ памяти>}{<Общее\ количество\ пикселей>}$, [бит]
Чтобы упростить последующие математически рассчеты:
Разложим все заданные натуральные числа на простые множители;
Переведем единицы измерения информации из [Кбайт] в [бит].
8 = 256$, различных цветов. А ведь это уже ответ!Мы нашли именно максимальное количество различных цветов, так как задействовали всю возможную глубину цвета $I = 8$. В качестве ответа нужно выписать только полученное натуральное число $256$ без каких-либо единиц измерения.
Ответ: $256$.
А сейчас я предлагаю вам на рассмотрение следущие задания из темы «Кодирование графической информации«. Чтобы закрепить пройденный материал постарайтесь самостоятельно решить эти примеры и сравнить полученные ответы с моими.
Пример $№1$
Автоматическая камера производит растровые изображения размером $200 × 256$ пикселей. Для кодирования цвета каждого пикселя используется одинаковое количество бит, коды пикселей записываются в файл один за другим без промежутков. Объём файла с изображением не может превышать $65$ Кбайт без учёта размера заголовка файла.
Какое максимальное количество цветов можно использовать в палитре?
Перейти к текстовому решению
Пример $№2$
Какой минимальный объём памяти (в Кбайт) нужно зарезервировать, чтобы можно было сохранить любое растровое изображение размером $64 × 64$ пикселов при условии, что в изображении могут использоваться $256$ различных цветов?
Перейти к текстовому решению
Пример $№3$
После преобразования растрового $256$-цветного графического файла в $4$-цветный формат его размер сократился на $18$ [Кбайт].
Каков был размер исходного файла? Ответ получить в [Кбайтах].
Перейти к текстовому решению
Остались вопросы по кодированию графической информации?
Если у вас остались какие-либо вопросы по теме «Кодирование графической информации», то звоните и записывайтесь ко мне на индивидуальный урок.
Очень много полезной информации не раскрыто в данной статье, которую мы сможем детально разобрать на репетиторском уроке по информатике и ИКТ.
Также на уроке мы сможем обсудить различия растровой и фрактальной графики. Прошу предварительно вас ознакомиться с моим расписанием и подобрать наиболее удобное для вас время.
Руководство по NVIDIA NVENC OBS
Кодирование — это сжатие изображений. Чем меньше размер изображения, тем меньше мы должны его сжимать и тем более высокое качество оно сохраняет. Хотя то же самое относится и к частоте кадров, зритель действительно может заметить падение FPS, но не так сильно, как разрешение, поэтому мы всегда будем пытаться транслировать со скоростью 60 FPS.
Сначала запустите тест скорости, чтобы определить скорость загрузки (например, тест скорости). Мы хотим использовать около 75% вашей скорости загрузки, поскольку игра и другие программы, такие как Discord, также будут бороться за пропускную способность.
Затем мы определим разрешение и FPS, которые мы можем использовать для такого битрейта. На большинстве потоковых сайтов есть рекомендации (Twitch, Mixer, Youtube) о том, что использовать. Это наши:
Скорость загрузки
Битрейт
Разрешение
Частота кадров
3 Мбит / с
2,500
1024×576
30
4 Мбит / с
3,500
1280×720
30
6 Мбит / с
5 000
1280×720
60
8-10 Мбит / с
6 000
1920×1080 *
60
12+ Мбит / с
10,000 (Смеситель)
1920×1080
60
15+ Мбит / с
12 000 (Youtube)
1920×1080
60
20+ Мбит / с
15 000+ (Youtube)
2560×1440
60
40+ Мбит / с
30 000+ (Youtube)
3840×2160
60
* Важное примечание для содержимого High Motion .
Если вы собираетесь транслировать сцены с высоким движением (например, гоночные игры, некоторые игры Battle Royale и т. Д.), Мы настоятельно рекомендуем уменьшить разрешение. Контент с высоким движением нельзя сжимать так сильно, и он может страдать от большего количества артефактов (ошибок кодирования), из-за которых ваш поток выглядит «блочным». Если вы уменьшите разрешение, вы уменьшите кодируемые данные, и в результате качество просмотра будет выше. Например, для Fortnite многие стримеры решают стримить с разрешением 1600×900 60 FPS.Примечание для новых и будущих стримеров на Twitch .Транскодирование позволяет зрителю просматривать ваше видео в другом разрешении, что требует меньшей полосы пропускания. Twitch предлагает Партнерам только гарантированное перекодирование; лица, не являющиеся партнерами, могут получать транскодирование, но это не гарантируется. Это важно, если ваши зрители пользуются мобильными телефонами или у них не такая быстрая скорость интернета. Вы можете рассмотреть возможность потоковой передачи с более низким битрейтом и разрешением, чтобы уменьшить полосу пропускания, необходимую для просмотра вашего канала.
Примечание для стримеров к микшеру. Mixer позволяет передавать потоки через стандартный протокол (RTMP) или улучшенный протокол, называемый Faster Than Light (FTL).FTL обеспечивает очень низкую задержку. Однако, когда вы его используете, Mixer рекомендует ограничить битрейт до 7 Мбит / с и не использовать B-кадры. Вы выбираете это в настройках OBS> Stream в разделе service.
- Если вы хотите получить максимальное качество, используйте RTMP со скоростью до 10 Мбит / с и B-кадрами.
- Если вам нужна минимально возможная задержка, используйте FTL.
Кодировок символов для начинающих
Во-первых, какое мне дело?
Если вы используете что-либо, кроме самого основного текста на английском языке, люди могут не прочитать созданный вами контент. если вы не укажете, какую кодировку символов вы использовали.
Например, вы можете сделать так, чтобы текст выглядел так:
, но на самом деле он может отображаться так:
Отсутствие информации о кодировке символов не только ухудшает читаемость отображаемого текста, но также может означать, что ваши данные не могут быть найдены поисковой системой или надежно обрабатывается машинами другими способами.
Так что за кодировка символов?
Слова и предложения в тексте состоят из символа .Примеры символов включают латинскую букву á, китайскую идеограмму 請 или символ деванагари ह.
Возможно, вы не сможете увидеть некоторые символы на этой странице, потому что у вас нет необходимых шрифтов. Если вы нажмете на то место, где вы ожидали увидеть персонажа, вы перейдете к графической версии. Эта страница закодирована в UTF-8.
Персонажи, необходимые для определенной цели, сгруппированы в набор символов (также называемый репертуаром ).(Чтобы однозначно обозначать символы, каждый символ связан с числом, называемым кодовой точкой .)
Символы хранятся в компьютере как один или несколько байтов .
В принципе, вы можете визуализировать это, предположив, что все символы хранятся в компьютерах с использованием специального кода, как шифры, используемые в шпионаже. Кодировка символов предоставляет ключ для разблокировки (т. Е. Взлома) кода. Это набор соответствий между байтами в компьютере и символами в наборе символов.Без ключа данные выглядят как мусор.
Вводящий в заблуждение термин кодировка часто используется для обозначения того, что на самом деле является кодировкой символов. Вам следует помните об этом использовании, но всегда старайтесь использовать термины кодировки символов.
Итак, когда вы вводите текст с клавиатуры или каким-либо другим способом, кодировка символов сопоставляет выбранные вами символы с конкретными байтами в памяти компьютера, а затем для отображения текста считывает байты обратно в символы.
К сожалению, существует множество различных наборов символов и кодировок символов, т.е. множество различных способов сопоставления байтов, кодовые точки и символы. В разделе «Дополнительная информация» для тех, кому интересно, чуть подробнее.
Однако в большинстве случаев вам не нужно знать подробности. Вам просто нужно быть уверенным, что вы прислушиваетесь к советам в раздел Как это влияет на меня? ниже.
Как в это вписываются шрифты?
Шрифт — это набор определений глифов, т.е.определения форм, используемых для отображения символов.
Как только ваш браузер или приложение определит, с какими символами имеет дело, оно будет искать в шрифте глифы, которые можно использовать для отображения. или распечатайте эти символы. (Конечно, если информация о кодировке была неправильной, она будет искать глифы для неправильных символов.)
Данный шрифт обычно охватывает один набор символов или, в случае большого набора символов, например Unicode, только подмножество всех персонажей в наборе.Если в вашем шрифте нет глифа для определенного символа, некоторые браузеры или программные приложения будут искать отсутствующие глифы в других шрифты в вашей системе (это будет означать, что глиф будет отличаться от окружающего текста, как записка с требованием выкупа). В противном случае вы обычно вместо этого увидите квадратную рамку, вопросительный знак или какой-либо другой символ. Например:
Как это повлияет на меня?
Как автор или разработчик контента, в настоящее время вы всегда должны выбирать UTF-8 кодировка символов для вашего контента или данных.Эта кодировка Unicode — хороший выбор, поскольку вы можете использовать односимвольную кодировку для обработки любого символа, который вам может понадобиться. Это значительно упрощает работу. Использование Unicode во всей вашей системе также устраняет необходимость отслеживать и преобразовывать между различными кодировками символов.
Авторы контента должны узнать, как объявить персонажа кодировка, используемая для формата документа, с которым они работают.
Обратите внимание, что просто объявление другой кодировки на вашей странице не изменит байты; вам нужно сохранить текст в этой кодировке.
Как автор контента, вам необходимо проверить, в какой кодировке ваш редактор или скрипты сохраняют текст и как сохранять текст в UTF-8. (В наши дни это обычно используется по умолчанию.) Вам также может потребоваться проверить, что ваш сервер обслуживает документы с правильным HTTP декларации.
Разработчикам необходимо убедиться, что различные части системы могут взаимодействовать друг с другом, понимать, какие кодировки символов используются и поддерживают все необходимые кодировки и символы.(В идеале вы должны использовать UTF-8 повсюду и избавиться от этой проблемы.)
По ссылкам ниже можно найти дополнительную информацию по этим темам.
Этот раздел предоставляет небольшую дополнительную информацию о сопоставлении байтов, кодовых точек и символов для тех, кому это интересно. Не стесняйтесь просто перейти к разделу Дополнительная литература.
Обратите внимание, что номера кодовых точек обычно выражаются в шестнадцатеричной системе счисления, т.е. основание 16. Например, 233 в шестнадцатеричной форме — это E9.Значения кодовой точки Unicode обычно записываются в форме U + 00E9.
В наборе кодированных символов под названием ISO 8859-1 (также известном как Latin1) значение десятичной кодовой точки для буквы é равно 233. Однако в ISO 8859-5, та же самая кодовая точка представляет кириллический символ щ.
Эти наборы символов содержат менее 256 символов и напрямую сопоставляют кодовые точки с байтовыми значениями, поэтому кодовая точка со значением 233 представлена одним байтом со значением 233.Обратите внимание, что только контекст определяет, представляет ли этот байт либо é, либо щ.
Есть и другие способы работы с символами из ряда сценариев. Например, с набором символов Unicode вы можете представить оба символа в одном наборе. Фактически, Unicode содержит в одном наборе, вероятно, все символы, которые вам когда-либо понадобятся. Хотя буква é по-прежнему представлена значением кодовой точки 233, кириллический символ щ теперь имеет значение кодовой точки 1097.
С другой стороны, 1097 — слишком большое число, чтобы его можно было представить одним байт*. Итак, если вы используете кодировку символов для текста Unicode под названием UTF-8, щ будет представлен двумя байтами. Тем не менее значение кодовой точки не просто выводится из значения двух байтов, соединенных вместе — требуется более сложное декодирование.
Другой Unicode символы отображаются в один, три или четыре байта в кодировке UTF-8.
Кроме того, обратите внимание, что буква é также представлена двумя байтами в UTF-8, а не одним байтом, используемым в ISO 8859-1. (Только символы ASCII кодируются одним байтом в UTF-8.)
UTF-8 — это наиболее широко используемый способ представления текста Unicode на веб-страницах, и вы всегда должны использовать UTF-8 при создании веб-страниц и баз данных. Но, в принципе, UTF-8 — лишь один из возможных способов кодирования. Символы Юникода. Другими словами, одна кодовая точка в наборе символов Unicode может фактически отображаться в разные последовательности байтов, в зависимости от какая кодировка использовалась для документа.Кодовые точки Unicode могут быть сопоставлены с байтами с использованием любой из кодировок, называемых UTF-8, UTF-16 или UTF-32. Символ деванагари क с кодовой точкой 2325 (что составляет 915 в шестнадцатеричной системе счисления) будет представлен двумя байтов при использовании кодировки UTF-16 (09 15), трех байтов с UTF-8 (E0 A4 95) или четырех байтов с UTF-32 (00 00 09 15).
Могут быть и другие сложности помимо описанных в этом разделе (например, порядок байтов и escape-последовательности), но детали описанное здесь показывает, почему важно, чтобы приложение, с которым вы работаете, знало, какая кодировка символов подходит для ваших данных, и знает, как обрабатывать эту кодировку.
URL Decode and Encode — Online
About
Встречайте URL Decode and Encode, простой онлайн-инструмент, который делает именно то, что написано; декодирует из кодировки URL и кодирует в нее быстро и легко. URL-адрес кодирует ваши данные простым способом или декодирует их в удобочитаемый формат. Кодирование URL-адреса, также известное как процентное кодирование, представляет собой механизм кодирования информации в унифицированном идентификаторе ресурса (URI) при определенных обстоятельствах. Хотя это называется кодировкой URL, на самом деле она используется в более общем плане в основном наборе универсальных идентификаторов ресурсов (URI), который включает как универсальный указатель ресурса (URL), так и универсальное имя ресурса (URN).Как таковой он также используется при подготовке данных типа носителя «application / x-www-form-urlencoded», как это часто бывает при отправке данных HTML-формы в HTTP-запросах.
Дополнительные параметры
- Набор символов: В случае текстовых данных схема кодирования не содержит их набор символов, поэтому вы должны указать, какой из них использовался в процессе кодирования. Обычно это UTF-8, но может быть любой другой; если вы не уверены, поиграйте с доступными опциями, включая автоопределение.Эта информация используется для преобразования декодированных данных в набор символов нашего веб-сайта, поэтому все буквы и символы могут отображаться правильно. Обратите внимание, что это не имеет отношения к файлам, поскольку к ним не нужно применять безопасные веб-преобразования.
- Декодировать каждую строку отдельно: Закодированные данные обычно состоят из непрерывного текста, даже символы новой строки преобразуются в их процентно закодированные формы. Перед декодированием все незашифрованные пробелы удаляются из ввода, чтобы обеспечить его целостность.Эта опция полезна, если вы собираетесь декодировать несколько независимых записей данных, разделенных разрывами строки.
- Живой режим: Когда вы включаете эту опцию, введенные данные немедленно декодируются с помощью встроенных функций JavaScript вашего браузера — без отправки какой-либо информации на наши серверы. В настоящее время этот режим поддерживает только набор символов UTF-8.
Все коммуникации с нашими серверами осуществляются через безопасные зашифрованные соединения SSL (https).Загруженные файлы удаляются с наших серверов сразу после обработки, а полученный загружаемый файл удаляется сразу после первой попытки загрузки или 15 минут бездействия. Мы никоим образом не храним и не проверяем содержимое введенных данных или загруженных файлов. Прочтите нашу политику конфиденциальности ниже для получения более подробной информации.
Совершенно бесплатно
Наш инструмент можно использовать бесплатно. Теперь вам не нужно загружать какое-либо программное обеспечение для таких задач.
Подробная информация о кодировке URL-адресов
Типы символов URI
Допустимые символы в URI либо зарезервированы, либо не зарезервированы (или процентный символ как часть процентного кодирования).Зарезервированные символы — это те символы, которые иногда имеют особое значение. Например, символы косой черты используются для разделения различных частей URL-адреса (или, в более общем смысле, URI). Незарезервированные символы не имеют такого значения. При использовании процентного кодирования зарезервированные символы представляются с помощью специальных последовательностей символов. Наборы зарезервированных и незарезервированных символов, а также обстоятельства, при которых определенные зарезервированные символы имеют особое значение, незначительно менялись с каждой версией спецификаций, управляющих URI и схемами URI.
RFC 3986 раздел 2.2 Зарезервированные символы (январь 2005 г.) !*'();:@и=+$,/?#[]RFC 3986 раздел 2.3 незарезервированных персонажа (январь 2005 г.) АВСДEФаксгHяДжКлMNОп.QрSтUВВтхYZбсдиfгчиjклмnилип.qрстuвwхyz0123456789-_.~
Другие символы в URI должны быть закодированы в процентах.Зарезервированные символы с процентным кодированием
Когда символ из зарезервированного набора («зарезервированный символ») имеет особое значение («зарезервированное назначение») в определенном контексте, а схема URI сообщает, что необходимо использовать этот символ для какой-то другой цели, тогда этот символ должен быть закодирован в процентах. Процентное кодирование зарезервированного символа включает преобразование символа в соответствующее ему байтовое значение в ASCII и последующее представление этого значения в виде пары шестнадцатеричных цифр.Цифры, которым предшествует знак процента («%»), затем используются в URI вместо зарезервированного символа. (Для символа, отличного от ASCII, он обычно преобразуется в его последовательность байтов в UTF-8, а затем каждое значение байта представляется, как указано выше.)
Зарезервированный символ «/», например, если он используется в пути « «компонент URI, имеет особое значение как разделитель между сегментами пути. Если в соответствии с заданной схемой URI «/» должен находиться в сегменте пути, тогда в этом сегменте должны использоваться три символа «% 2F» или «% 2f» вместо необработанного «/».
Зарезервированные символы после процентного кодирования !#$и'()*+,/:;=?@[]% 21% 23% 24% 26% 27% 28% 29% 2A% 2B% 2C% 2F% 3A% 3B% 3D% 3F% 40% 5B% 5D
Зарезервированные символы, которые не имеют зарезервированной цели в конкретном контексте, также могут быть закодированы в процентах, но семантически не отличаются от тех, которые не имеют.В компоненте «запрос» URI (часть после символа?), Например, «/» по-прежнему считается зарезервированным символом, но обычно он не имеет зарезервированного назначения, если в конкретной схеме URI не указано иное. Символ не нужно кодировать в процентах, если он не имеет зарезервированной цели.
URI, которые различаются только тем, является ли зарезервированный символ закодированным в процентах или отображается буквально, обычно считаются не эквивалентными (обозначающими один и тот же ресурс), если не может быть определено, что рассматриваемые зарезервированные символы не имеют зарезервированной цели.Это определение зависит от правил, установленных для зарезервированных символов отдельными схемами URI.
Процентное кодирование незарезервированных символов
Символы из незарезервированного набора никогда не нуждаются в процентном кодировании.
URI, которые различаются только тем, является ли незарезервированный символ закодированным в процентах или выглядит буквально, эквивалентны по определению, но процессоры URI на практике не всегда могут распознавать эту эквивалентность. Например, потребители URI не должны трактовать «% 41» иначе, чем «A» или «% 7E» иначе, чем «~», но некоторые это делают.Для максимальной совместимости производителям URI не рекомендуется использовать процентное кодирование незарезервированных символов.
Процентное кодирование символа процента
Поскольку символ процента («%») служит индикатором для октетов, закодированных в процентах, он должен быть закодирован в процентах как «% 25», чтобы этот октет использовался в качестве данных внутри URI.
Процентное кодирование произвольных данных
Большинство схем URI включают представление произвольных данных, таких как IP-адрес или путь файловой системы, в качестве компонентов URI.Спецификации схемы URI должны, но часто этого не делать, предоставлять явное отображение между символами URI и всеми возможными значениями данных, представленными этими символами.
Двоичные данные
С момента публикации RFC 1738 в 1994 году было указано [1], что схемы, которые обеспечивают представление двоичных данных в URI, должны разделять данные на 8-битные байты и кодировать их в процентах. byte таким же образом, как указано выше. Например, байтовое значение 0F (шестнадцатеричное) должно быть представлено как «% 0F», а байтовое значение 41 (шестнадцатеричное) может быть представлено как «A» или «% 41».Использование незакодированных символов для буквенно-цифровых и других незарезервированных символов обычно является предпочтительным, поскольку это приводит к более коротким URL-адресам.
Символьные данные
Процедура процентного кодирования двоичных данных часто экстраполируется, иногда неправильно или не полностью, для применения к символьным данным. В годы становления Всемирной паутины при работе с символами данных в репертуаре ASCII и использовании соответствующих им байтов в ASCII в качестве основы для определения последовательностей, закодированных в процентах, эта практика была относительно безвредной; просто предполагалось, что символы и байты отображаются взаимно однозначно и взаимозаменяемы.Однако потребность в представлении символов вне диапазона ASCII быстро росла, и схемы и протоколы URI часто не обеспечивали стандартных правил подготовки символьных данных для включения в URI. Следовательно, веб-приложения начали использовать различные многобайтовые кодировки, кодировки с отслеживанием состояния и другие несовместимые с ASCII кодировки в качестве основы для процентного кодирования, что привело к неоднозначности и трудностям надежной интерпретации URI.
Например, многие схемы и протоколы URI, основанные на RFC 1738 и 2396, предполагают, что символы данных будут преобразованы в байты в соответствии с некоторой неопределенной кодировкой символов до того, как будут представлены в URI незарезервированными символами или байтами с процентной кодировкой.Если схема не позволяет URI предоставлять подсказку о том, какая кодировка использовалась, или если кодировка конфликтует с использованием ASCII для процентного кодирования зарезервированных и незарезервированных символов, то URI не может быть надежно интерпретирован. В некоторых схемах вообще не учитывается кодирование, и вместо этого просто предлагается, чтобы символы данных отображались непосредственно на символы URI, что оставляет на усмотрение реализации решение, следует ли и как кодировать символы данных в процентах, которые не входят ни в зарезервированные, ни в незарезервированные наборы.
_`{|}~% 0Aили% 0Dили% 0D% 0A% 20% 22% 25% 2D% 2E% 3C% 3E% 5C% 5E% 5F% 60% 7B% 7C% 7D% 7E
Данные произвольных символов иногда кодируются в процентах и используются в ситуациях, не связанных с URI, например, для программ обфускации паролей или других системных протоколов трансляции.Поддерживаемые кодировки
java.io.InputStreamReader,java.io.OutputStreamWriter,java.lang.Stringклассов, а классы вjava.nio.charsetпакет может конвертировать между Unicode и ряд других кодировок символов. Поддерживаемые кодировки различаются между различными реализациями Java SE 8. Описание класса дляjava.nio.charset.Charsetперечисляет кодировки, которые должна поддерживать любая реализация Java SE 8.JDK 8 для всех платформ (Solaris, Linux и Microsoft Windows) и JRE 8 для Solaris и Linux поддерживают все кодировки, показанные на этой странице. JRE 8 для Microsoft Windows может быть установлена как полная международная версия или как европейская языковая версия. По умолчанию установщик JRE 8 устанавливает Версия на европейских языках, если она распознает, что хост, работающий система поддерживает только европейские языки. Если установщик признает, что нужен любой другой язык, или если пользователь запрашивает поддержку для неевропейских языков в индивидуальном при установке устанавливается полная международная версия.В Версия для европейских языков поддерживает только кодировки, указанные в следующую таблицу базового набора кодировок. Международная версия (который включает файл lib / charsets.jar) поддерживает все кодировки, показанные на этой странице.
В следующих таблицах показаны наборы кодировок, поддерживаемые Java SE. 8. Канонические имена, используемые новыми API-интерфейсами
java.nio. во многих случаях не совпадают с используемыми вjava.ioиjava.langAPI.Каноническое имя для java.nio API Каноническое имя для API java.io и API java.lang Псевдоним или псевдонимы Описание ЦЭСУ-8 CESU8 CESU8 CSCESU-8 Юникод CESU-8 IBM00858 Cp858 cp858 858 PC-Multilingual-850 + евро cp00858 ccsid00858 Вариант Cp850 с символом евро IBM437 Cp437 ibm437 437 ibm-437 cspc8codepage437 cp437 windows-437 MS-DOS США, Австралия, Новая Зеландия, Южная Африка IBM775 Cp775 ibm-775 ibm775 775 cp775 PC Балтика IBM850 Cp850 cp850 cspc850 многоязычный ibm850 850 ibm-850 MS-DOS Latin-1 IBM852 Cp852 csPCp852 ibm-852 ibm852 852 cp852 MS-DOS Latin-2 IBM855 Cp855 ibm855 855 ibm-855 cp855 cspcp855 IBM Кириллица IBM857 Cp857 ibm857 857 cp857 csIBM857 ibm-857 IBM Турецкий IBM862 Cp862 csIBM862 cp862 ibm862 862 cspc862latinhebrew ibm-862 PC Еврейский IBM866 Cp866 ibm866 866 ibm-866 csIBM866 cp866 MS-DOS Русский ISO-8859-1 ISO8859_1 819 ISO8859-1 l1 ISO_8859-1: 1987 ISO_8859-1 8859_1 iso-ir-100 latin1 cp819 ISO8859_1 IBM819 ISO_8859_1 IBM-819 csISOLatin1 ISO-8859-1, латинский алфавит No.1 ISO-8859-2 ISO8859_2 ISO8859-2 ibm912 l2 ISO_8859-2 8859_2 cp912 ISO_8859-2: 1987 iso8859_2 iso-ir-101 latin2 912 csISOLatin2 ibm-912 Латинский алфавит № 2 ISO-8859-4 ISO8859_4 8859_4 latin4 l4 cp914 ISO_8859-4: 1988 ibm914 ISO_8859-4 iso-ir-110 iso8859_4 csISOLatin4 iso8859-4 914 ibm-914 Латинский алфавит № 4 ISO-8859-5 ISO8859_5 ISO_8859-5: 1988 csISOLatinCyrillic iso-ir-144 iso8859_5 cp915 8859_5 ibm-915 ISO_8859-5 ibm915 915 кириллица ISO8859-5 Латинский / кириллица ISO-8859-7 ISO8859_7 греческий 8859_7 греческий8 ibm813 ISO_8859-7 iso8859_7 ELOT_928 cp813 ISO_8859-7: 1987 sun_eu_greek csISOLatinGreek iso-ir-126813 iso8859-7 ECMA-118 ibm-813 Латинский / греческий алфавит (ISO-8859-7: 2003) ISO-8859-9 ISO8859_9 ibm-920 ISO_8859-9 8859_9 ISO_8859-9: 1989 ibm920 latin5 l5 iso8859_9 cp920 920 iso-ir-148 ISO8859-9 csISOLatin5 Латинский алфавит No.5 ISO-8859-13 ISO8859_13 iso_8859-13 ISO8859-13 iso8859_13 8859_13 Латинский алфавит № 7 ISO-8859-15 ISO8859_15 ISO8859-15 LATIN0 ISO8859_15_FDIS ISO8859_15 cp923 8859_15 L9 ISO-8859-15 IBM923 csISOlatin9 ISO_8859-15 IBM-923 csISOlatin0 923 LATIN9 Латинский алфавит № 9 КОИ8-Р KOI8_R koi8_r koi8 cskoi8r КОИ8-Р, Россия КОИ8-У КОИ8_У koi8_u КОИ8-У, Украинский US-ASCII ASCII ANSI_X3.4-1968 cp367 csASCII iso-ir-6 ASCII iso_646.irv: 1983 ANSI_X3.4-1986 ascii7 по умолчанию ISO_646.irv: 1991 ISO646-US IBM367 646 us Американский стандартный код для обмена информацией UTF-8 UTF8 юникод-1-1-utf-8 UTF8 Восьмибитный формат преобразования Unicode (или UCS) UTF-16 UTF-16 UTF_16 юникод utf16 UnicodeBig Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов определяется необязательной меткой порядка байтов UTF-16BE UnicodeBigUnmarked X-UTF-16BE UTF_16BE ISO-10646-UCS-2 UnicodeBigUnmarked Шестнадцатиразрядный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов UTF-16LE UnicodeLittleUnmarked UnicodeLittleUnmarked UTF_16LE X-UTF-16LE Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов с прямым порядком байтов UTF-32 UTF_32 UTF_32 UTF32 32-битный формат преобразования Unicode (или UCS), порядок байтов определяется необязательной меткой порядка байтов UTF-32BE UTF_32BE X-UTF-32BE UTF_32BE 32-битный формат преобразования Unicode (или UCS), с прямым порядком байтов заказ UTF-32LE UTF_32LE X-UTF-32LE UTF_32LE 32-битный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов x-UTF-32BE-BOM UTF_32BE_BOM UTF_32BE_BOM UTF-32BE-BOM 32-битный формат преобразования Unicode (или UCS), с прямым порядком байтов порядок, с пометкой порядка байтов x-UTF-32LE-BOM UTF_32LE_BOM UTF_32LE_BOM UTF-32LE-BOM 32-битный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов с меткой порядка байтов окна-1250 Cp1250 cp1250 cp5346 Windows Восточноевропейская окна-1251 Cp1251 cp5347 ansi-1251 cp1251 Окна Кириллица окна-1252 Cp1252 cp5348 cp1252 Windows Latin-1 окна-1253 Cp1253 cp1253 cp5349 Окна Греческая окна-1254 Cp1254 cp1254 cp5350 Окна Турецкая окна-1257 Cp1257 cp1257 cp5353 Окна Балтика Не доступен UnicodeBig Не доступен Шестнадцатиразрядный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов с меткой порядка байтов x-IBM737 Cp737 cp737 ibm737 737 ibm-737 PC Греческий x-IBM874 Cp874 ibm-874 ibm874 874 cp874 IBM Thai x-UTF-16LE-BOM UnicodeLittle UnicodeLittle Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов с прямым порядком байтов, с меткой порядка байтов Каноническое имя для java.nio API Каноническое имя для API java.io и API java.lang Псевдоним или псевдонимы Описание Большой5 Большой5 csBig5 Big5, традиционный китайский Big5-HKSCS Big5_HKSCS big5-hkscs big5hk Big5_HKSCS big5hkscs Big5 с расширениями для Гонконга, традиционный китайский (включая редакцию 2001 г.) EUC-JP EUC_JP csEUCPkdFmtяпонский x-euc-jp eucjis Extended_UNIX_Code_Packed_Format_for_Японский euc_jp eucjp x-eucjp JISX 0201, 0208 и 0212, кодировка EUC, японская EUC-KR EUC_KR ksc5601-1987 csEUCKR ksc5601_1987 ksc5601 5601 euc_kr ksc_5601 ks_c_5601-1987 euckr KS C 5601, кодировка EUC, корейский язык ГБ18030 ГБ18030 гб18030-2000 Китайский упрощенный, стандарт КНР ГБ2312 EUC_CN gb2312 euc-cn x-EUC-CN euccn EUC_CN gb2312-80 gb2312-1980 GB2312, кодировка EUC, упрощенный китайский ГБК ГБК CP936 окна-936 GBK, упрощенный китайский IBM-Thai Cp838 ibm-838 ibm838 838 cp838 IBM Thailand расширенный SBCS IBM01140 Cp1140 cp1140 1140 cp01140 ebcdic-us-037 + евро ccsid01140 Вариант Cp037 с символом евро IBM01141 Cp1141 1141 cp1141 cp01141 ccsid01141 ebcdic-de-273 + евро Вариант Cp273 с символом евро IBM01142 Cp1142 1142 cp1142 cp01142 ccsid01142 ebcdic-no-277 + евро ebcdic-dk-277 + евро Вариант Cp277 с символом евро IBM01143 Cp1143 1143 cp01143 ccsid01143 cp1143 ebcdic-fi-278 + евро ebcdic-se-278 + евро Вариант Cp278 с символом евро IBM01144 Cp1144 cp01144 ccsid01144 ebcdic-it-280 + евро cp1144 1144 Вариант Cp280 с символом евро IBM01145 Cp1145 ccsid01145 ebcdic-es-284 + евро 1145 cp1145 cp01145 Вариант CP284 с символом евро IBM01146 Cp1146 ebcdic-gb-285 + евро 1146 cp1146 cp01146 ccsid01146 Вариант CP285 с символом евро IBM01147 Cp1147 cp1147 1147 cp01147 ccsid01147 ebcdic-fr-277 + евро Вариант Cp297 с символом евро IBM01148 Cp1148 cp1148 ebcdic-international-500 + евро 1148 cp01148 ccsid01148 Вариант Cp500 с символом евро IBM01149 Cp1149 ebcdic-s-871 + евро 1149 cp1149 cp01149 ccsid01149 Вариант Cp871 с символом евро IBM037 Cp037 cp037 ibm037 ibm-037 csIBM037 ebcdic-cp-us ebcdic-cp-ca ebcdic-cp-nl ebcdic-cp-wt 037 cpibm37 cs-ebcdic-cp-wt ibm-37 cs-ebcdic-cp-us cs-ebcdic-cp-ca cs-ebcdic-cp-nl США, Канада (двуязычный, французский), Нидерланды, Португалия, Бразилия, Австралия IBM1026 Cp1026 cp1026 ibm-1026 1026 ibm1026 IBM Latin-5, Турция IBM1047 Cp1047 ibm-1047 1047 cp1047 Набор символов Latin-1 для хостов EBCDIC IBM273 Cp273 ibm-273 ibm273 273 cp273 IBM Австрия, Германия IBM277 Cp277 ibm277 277 cp277 ibm-277 IBM Дания, Норвегия IBM278 Cp278 cp278 278 ibm-278 ebcdic-cp-se csIBM278 ibm278 ebcdic-sv IBM Финляндия, Швеция IBM280 Cp280 ibm280 280 cp280 ibm-280 IBM Италия IBM284 Cp284 csIBM284 ibm-284 cpibm284 ibm284 284 cp284 IBM Каталонский / Испания, испанский Латинская Америка IBM285 Cp285 csIBM285 cp285 ebcdic-gb ibm-285 cpibm285 ibm285 285 ebcdic-cp-gb IBM Великобритания, Ирландия IBM290 Cp290 ibm290 290 cp290 EBCDIC-JP-кана csIBM290 ibm-290 IBM Japanese Katakana Host Extended SBCS IBM297 Cp297 297 csIBM297 cp297 ibm297 ibm-297 cpibm297 ebcdic-cp-fr IBM Франция IBM420 Cp420 ibm420 420 cp420 csIBM420 ibm-420 ebcdic-cp-ar1 IBM Арабский IBM424 Cp424 ebcdic-cp-he csIBM424 ibm-424 ibm424 424 cp424 IBM Еврейский IBM500 Cp500 ibm-500 ibm500 500 ebcdic-cp-bh ebcdic-cp-ch csIBM500 cp500 EBCDIC 500V1 IBM860 Cp860 ibm860 860 cp860 csIBM860 ibm-860 MS-DOS Португальский IBM861 Cp861 cp861 ibm861 861 ibm-861 cp-is csIBM861 MS-DOS Исландский IBM863 Cp863 csIBM863 ibm-863 ibm863 863 cp863 MS-DOS Канадский французский IBM864 Cp864 csIBM864 ibm-864 ibm864 864 cp864 PC Арабский IBM865 Cp865 ibm-865 csIBM865 cp865 ibm865 865 MS-DOS Nordic IBM868 Cp868 ibm868 868 cp868 csIBM868 ibm-868 cp-ar MS-DOS Пакистан IBM869 Cp869 cp869 ibm869 869 ibm-869 cp-gr csIBM869 IBM Новогреческий IBM870 Cp870 870 cp870 csIBM870 ibm-870 ibm870 ebcdic-cp-roece ebcdic-cp-yu IBM Multilingual Latin-2 IBM871 Cp871 ibm871 871 cp871 ebcdic-cp-is csIBM871 ibm-871 IBM Исландия IBM918 Cp918 918 ibm-918 ebcdic-cp-ar2 cp918 IBM, Пакистан (урду) ISO-2022-CN ISO2022CN csISO2022CN ISO2022CN GB2312 и CNS11643 в форме ISO 2022 CN, упрощенной и Традиционный китайский (только преобразование в Unicode) ISO-2022-JP ISO2022JP csjisencoding iso2022jp jis_encoding jis csISO2022JP JIS X 0201, 0208, в форме ISO 2022, японский ISO-2022-JP-2 ISO2022JP2 csISO2022JP2 iso2022jp2 JIS X 0201, 0208, 0212 в форме ISO 2022, японский ISO-2022-KR ISO2022KR csISO2022KR ISO2022KR ISO 2022 KR, корейский ISO-8859-3 ISO8859_3 ISO8859-3 ibm913 8859_3 l3 cp913 ISO_8859-3 iso8859_3 latin3 csISOLatin3 913 ISO_8859-3: 1988 ibm-913 iso-ir-109 Латинский алфавит No.3 ISO-8859-6 ISO8859_6 ASMO-708 8859_6 iso8859_6 ISO_8859-6 csISOLatinArabic ibm1089 арабский ibm-1089 1089 ECMA-114 iso-ir-127 ISO_8859-6: 1987 ISO8859-6 cp1089 Латинский / арабский алфавит ISO-8859-8 ISO8859_8 8859_8 ISO_8859-8 ISO_8859-8: 1988 cp916 iso-ir-138 ISO8859-8 иврит iso8859_8 ibm-916 csISOLatin иврит 916 ibm916 Латинский / еврейский алфавит JIS_X0201 JIS_X0201 JIS0201 csHalfWidthKatakana X0201 JIS_X0201 JIS X 0201 JIS_X0212-1990 JIS_X0212-1990 JIS0212 iso-ir-159 x0212 jis_x0212-1990 csISO159JISX02121990 JIS X 0212 Shift_JIS SJIS shift_jis x-sjis sjis shift-jis ms_kanji csShiftJIS Shift-JIS, Японский ТИС-620 TIS620 тис620 тис620.2533 TIS620, тайский окна-1255 Cp1255 cp1255 Windows Иврит окна-1256 Cp1256 cp1256 Windows Арабский окна-1258 Cp1258 cp1258 Windows Вьетнамский окна-31j MS932 MS932 Windows-932 CSWindows31J Windows Японский x-Big5-Solaris Big5_Solaris Big5_Solaris Big5 с семью дополнительными отображениями иероглифов Hanzi для Solaris zh_TW.BIG5 язык x-euc-jp-Linux EUC_JP_LINUX euc_jp_linux euc-jp-linux JISX 0201, 0208, кодировка EUC, японская x-EUC-TW EUC_TW euctw cns11643 EUC-TW euc_tw CNS11643 (плоскость 1-7,15), кодировка EUC, традиционный китайский x-eucJP-Open EUC_JP_Solaris eucJP-open EUC_JP_Solaris JISX 0201, 0208, 0212, кодировка EUC, японская х-IBM1006 Cp1006 ibm1006 ibm-1006 1006 cp1006 IBM AIX Пакистан (урду) x-IBM1025 Cp1025 ibm-1025 1025 cp1025 ibm1025 IBM Multilingual Cyrillic: Болгария, Босния, Герцеговина, Македония (БЮР) x-IBM1046 Cp1046 ibm1046 ibm-1046 1046 cp1046 IBM Arabic — Windows x-IBM1097 Cp1097 ibm1097 ibm-1097 1097 cp1097 IBM, Иран (фарси) / персидский x-IBM1098 Cp1098 ibm-1098 1098 cp1098 ibm1098 IBM Иран (фарси) / персидский (ПК) х-IBM1112 Cp1112 ibm1112 ibm-1112 1112 cp1112 IBM Латвия, Литва х-IBM1122 Cp1122 cp1122 ibm1122 ibm-1122 1122 IBM Эстония x-IBM1123 Cp1123 ibm1123 ibm-1123 1123 cp1123 IBM Украина x-IBM1124 Cp1124 ibm-1124 1124 cp1124 ibm1124 IBM AIX Украина x-IBM1166 Cp1166 cp1166 ibm1166 ibm-1166 1166 IBM Cyrillic Multilingual с евро для Казахстана х-IBM1364 Cp1364 cp1364 ibm1364 ibm-1364 1364 IBM EBCDIC KS X 1005-1 х-IBM1381 Cp 1381 cp1381 ibm-1381 1381 ibm1381 IBM OS / 2, DOS Китайская Народная Республика (КНР) х-IBM1383 Cp 1383 ibm1383 ibm-1383 1383 cp1383 IBM AIX Китайская Народная Республика (КНР) х-IBM300 Cp300 cp300 ibm300 300 ibm-300 IBM Японский двухбайтовый латинский хост x-IBM33722 Cp33722 33722 ibm-33722 cp33722 ibm33722 ibm-5050 ibm-33722_vascii_vpua IBM-eucJP — японский (расширенный набор 5050) х-IBM833 Cp833 ibm833 cp833 ibm-833 IBM Korean Host Extended SBCS x-IBM834 Cp834 ibm834 834 cp834 ibm-834 IBM EBCDIC DBCS-only Korean x-IBM856 Cp856 ibm856 856 cp856 ibm-856 IBM Еврейский x-IBM875 Cp875 ibm-875 ibm875 875 cp875 IBM Греческий х-IBM921 CP921 ibm921 921 ibm-921 cp921 IBM Латвия, Литва (AIX, DOS) x-IBM922 Cp922 ibm922 922 cp922 ibm-922 IBM Эстония (AIX, DOS) x-IBM930 Cp930 ibm-930 ibm930 930 cp930 Катакана и кандзи (японский), смешанные с 4370 УДК, расширенный набор из 5026 x-IBM933 Cp933 ibm933 933 cp933 ibm-933 Корейский смешанный с 1880 УДК, расширенный набор из 5029 х-IBM935 Cp935 cp935 ibm935 935 ibm-935 Узел на упрощенном китайском, смешанный с 1880 UDC, расширенный набор 5031 x-IBM937 Cp937 ibm-937 ibm937 937 cp937 Традиционный китайский хост, соединенный с 6204 UDC, расширенный набор 5033 x-IBM939 Cp939 ibm-939 cp939 ibm939 939 Японские латинские кандзи, смешанные с 4370 UDC, расширенный набор из 5035 х-IBM942 Cp942 ibm-942 cp942 ibm942 942 IBM OS / 2 Японский, расширенный набор Cp932 x-IBM942C Cp942C ibm942C cp942C ibm-942C 942C Вариант Cp942 x-IBM943 Cp943 ibm943 943 ibm-943 cp943 IBM OS / 2 Японский, расширенный набор Cp932 и Shift-JIS x-IBM943C Cp943C 943C cp943C ibm943C ibm-943C Вариант Cp943 x-IBM948 Cp948 ibm-948 ibm948 948 cp948 OS / 2 Китайский (Тайвань) расширенный набор 938 x-IBM949 Cp949 ibm-949 ibm949 949 cp949 ПК Корейский x-IBM949C Cp949C ibm949C ibm-949C cp949C 949C Вариант Cp949 х-IBM950 CP950 cp950 ibm950 950 ibm-950 ПК Китайский (Гонконг, Тайвань) x-IBM964 Cp964 ibm-964 cp964 ibm964 964 AIX китайский (Тайвань) x-IBM970 CP970 ibm970 ibm-eucKR 970 cp970 ibm-970 AIX корейский x-ISCII91 ISCII91 ISCII91 iso-ir-153 iscii ST_SEV_358-88 csISO153GOST1976874 ISCII91 кодировка индийских скриптов х-ISO2022-CN-CNS ISO2022_CN_CNS Не доступен CNS11643 в форме ISO 2022 CN, традиционный китайский (преобразование только из Unicode) x-ISO2022-CN-GB ISO2022_CN_GB Не доступен GB2312 в форме ISO 2022 CN, упрощенный китайский (преобразование из Только Unicode) x-iso-8859-11 x-iso-8859-11 iso-8859-11 iso8859_11 Латинский / тайский алфавит х-JIS0208 х-JIS0208 JIS0208 JIS_C6226-1983 iso-ir-87 x0208 JIS_X0208-1983 csISO87JISX0208 JIS X 0208 x-JISAutoDetect JISAutoDetect JISAutoDetect Обнаруживает и преобразует Shift-JIS, EUC-JP, ISO 2022 JP (преобразование только в Unicode) x-Johab x-Johab ms1361 ksc5601_1992 johab ksc5601-1992 Корейский, набор символов Джохаб x-Mac Арабский Макарабский Макарабский Macintosh Арабский x-MacCentralEurope MacCentralEurope MacCentralEurope Macintosh Latin-2 х-МакКроат МакКроат МакКроат Macintosh Хорватский х-MacCyrillic MacCyrillic MacCyrillic Macintosh Кириллица х-МакДингбат MacDingbat MacDingbat Macintosh Dingbat x-MacGreek MacGreek MacGreek Macintosh Греческий x-Mac Иврит MacHebrew MacHebrew Macintosh Иврит x-MacIceland MacIceland MacIceland Macintosh Исландия x-MacRoman MacRoman MacRoman Macintosh Roman x-Mac Румыния MacRomania MacRomania Macintosh Румыния x-MacSymbol MacSymbol MacSymbol Macintosh Symbol x-MacThai MacThai MacThai Тайский Macintosh x-Mac Турецкий MacTurkish MacTurkish Macintosh Турецкий x-Mac Украина MacUkraine Mac Украина Macintosh Украина x-MS932_0213 х-MS950-HKSCS MS950_HKSCS Не доступен Shift_JISX0213 Windows MS932 вариант х-MS950-HKSCS MS950_HKSCS MS950_HKSCS Windows (традиционный китайский) с расширениями для Гонконга х-MS950-HKSCS-XP x-mswin-936 MS936 MS950_HKSCS_XP HKSCS Windows XP вариант x-mswin-936 MS936 мс936 мс_936 Windows (упрощенный китайский) x-PCK PCK упаковка Версия Shift_JIS для Solarisx-SJIS_0213 x-SJIS_0213 Не доступен Shift_JISX0213 x-окна-50220 Cp50220 cp50220 ms50220 Кодовая страница Windows 50220 (7-битная реализация) x-windows-50221 Cp50221 cp50221 ms50221 Кодовая страница Windows 50221 (7-разрядная реализация) x-окна-874 MS874 мс-874 мс874 окна-874 Windows тайский x-окна-949 MS949 windows949 ms949 windows-949 ms_949 Windows Корейский x-окна-950 MS950 ms950 windows-950 Windows Традиционный китайский x-windows-iso2022jp x-windows-iso2022jp windows-iso2022jp Вариант ISO-2022-JP (на основе MS932) Методы кодирования функций — Машинное обучение
Как мы все знаем, лучшее кодирование ведет к лучшей модели, и большинство алгоритмов не могут обрабатывать категориальные переменные, если они не преобразованы в числовое значение.
Категориальные признаки обычно делятся на 3 типа:
- Двоичный: Либо / или
Примеры: - Порядковый номер: Специальные заказанные группы.
Примеры:- низкий, средний, высокий
- холодный, горячий, лава горячий
- Номинал: Неупорядоченные группы.
Примеры
- кошка, собака, тигр
- пицца, бургер, кокс
Код:
импортпанд как pdимпортnumpy as npимпортseaborn as snsdf=pd.read_csv ("Encoding Data.csv")df.head (10)Выход:
Набор данных
Давайте рассмотрим столбцы набора данных с помощью различных методов кодирования.
Код: отображение двоичных объектов, присутствующих в наборе данных.df ['bin_1']=df ['bin_1'].применить(лямбдаx:1, еслиx=='T'иначе(00 =='F'иначеНет))df ['bin_2']=df ['bin_2'].применить(лямбдаx:1, еслиx=='Y'иначе(00 =='N'иначеНет))sns.countplot (df ['bin_1'])sns.countplot (df ['bin_2'])Вывод:
Bin_1 после применения сопоставления
bin_2 после применения отображения
Кодирование меток: Алгоритм кодирования меток довольно прост и учитывает порядок кодирования, следовательно, может использоваться для кодирования порядковых данных.
.
Код:изsklearn.preprocessingimportLabelEncoderle=LabelEncoder ()df ['ord_2']=le.fit_transform (df ['ord_2'])снс.набор(стиль="darkgrid")снс.countplot (df ['ord_2'])Выход:
График ord_2 после кодирования этикетки
One-Hot Encoding: Для преодоления недостатков кодирования меток, поскольку оно учитывает некоторую иерархию в столбцах, которая может вводить в заблуждение номинальные характеристики, присутствующие в данных. мы можем использовать стратегию One-Hot Encoding.
Однократное кодирование выполняется в 2 этапа:
- Разделение категорий на разные столбцы.
- Укажите «0» для других и «1» в качестве индикатора для соответствующего столбца.
Код: горячее кодирование с помощью Sklearn libray
изsklearn.preprocessingimportOneHotEncoderкод=OneHotEncoder ()enc=enc.fit_transform (df [['nom_0']]).toarray ()encoded_colm=pd.DataFrame (enc)df=pd.concat ([df, encoded_colm], ось=1)df=df.drop (['nom_0'], ось=1)df.head (10)Выход:
Выход
Код: горячее кодирование с пандами
df=pd.get_dummies (df, префикс=['nom_0'], столбцы=['nom_0'])df.head (10)Выход:
Выход
Этот метод более предпочтителен, поскольку дает хорошие метки.
Примечание: Подход с горячим кодированием устраняет порядок, но приводит к значительному увеличению количества столбцов.Поэтому для столбцов с более уникальными значениями попробуйте использовать другие методы.Кодирование частоты: Мы также можем кодировать с учетом распределения частот. Этот метод иногда может быть эффективным для номинальных характеристик.
Код:
fq=df.groupby ('nom_0') .size ()/len(df)df.loc [:,"{} _freq_encode".формат('nom_0')]=df ['nom_0'].карта(fq)df=df.drop (['nom_0'], ось=1)fq.plot.bar (сложено=True)df.head (10)Выход:
Распределение частот (fq)
Выход
Порядковое кодирование: Мы можем использовать Порядковое кодирование, предоставленное в классе обучения Scikit, для кодирования порядковых функций.Это гарантирует сохранение порядкового характера переменных.
Код: использование Scikit learn.изsklearn.preprocessingimportOrdinalEncoderord1=OrdinalEncoder ()ord1.fit ([df ['ord_2']])df ["ord_2"]=ord1.fit_transform (df [["ord_2"]])df.head (10)Выход:
Выход
Код: ранжирование вручную с помощью словаря
temp_dict={«Холодный»:1,«Теплый»:2,}df ['Ord_2_encod']=df.ord_2.карта(temp_dict)df=df.drop (['ord_2'], ось=1)Выход: </strong>Выход
Двоичное кодирование:
.
Первоначально категории кодируются как целые числа, а затем преобразуются в двоичный код, затем цифры из этой двоичной строки помещаются в отдельные столбцы.
для, например: для 7: 1 1 1
Этот метод предпочтительнее, если количество категорий больше. Представьте, что у вас есть 100 разных категорий. Одно горячее кодирование создаст 100 разных столбцов, но для двоичного кодирования требуется только 7 столбцов.
Код:изcategory_encodersimportBinaryEncoderкодировщик=BinaryEncoder (столбцы=['ord_2'])newdata=энкодер.fit_transform (df ['ord_2'])df=pd.concat ([df, newdata], ось=1)df=df.drop (['ord_2'], ось=1)df.head (10)Выход:
Выход
HashEncoding: Хеширование - это процесс преобразования строки символов в уникальное хеш-значение с применением хеш-функции.Этот процесс весьма полезен, поскольку он может работать с большим количеством категориальных данных и низким потреблением памяти.
Статья о хешировании
Код:изsklearn.feature_extractionimportFeatureHasherh=FeatureHasher (n_features=3, input_type='строка')hashed_Feature=h.fit_transform (df ['nom_0'])hashed_Feature=hashed_Feature.toarray ()df=pd.concat ([df, pd.DataFrame (hashed_Feature)], ось=1)df.head (10)Выход:
Выход
В дальнейшем вы можете удалить преобразованный объект из фрейма данных.
Среднее / целевое кодирование: Целевое кодирование хорошо, потому что оно подбирает значения, которые могут объяснить целевое значение. Его используют большинство каглеров на соревнованиях. Основная идея заменить категориальное значение средним значением целевой переменной.
Код: .Кодирование и декодирование в коммуникации Значение, определение и различия
Процесс связи в основном зависит от следующих
- Кодирование &
- Расшифровка
Значение кодировки при общении
Буквальное кодирование означает преобразование объема информации из одной системы в другую в виде кодов.Код - это система символов, знаков или букв, используемая для представления секретного значения. По словам Джона Фиске, кодирование «состоит из знаков и правил, которые определяют, как и в каком контексте используются эти знаки и как их можно комбинировать для формирования более сложных сообщений».
Кодирование означает полную систему значений для представителей культуры или субкультуры. Также необходимо отметить, что код и система взаимосвязаны друг с другом. Эффективный процесс коммуникации можно легко понять из следующей диаграммы.
В описанном выше процессе кодировщик или источник придает людям форму сообщения, идеи или информации, или мы можем сказать, что он кодирует свое сообщение надлежащим образом в своем уме, а затем отправляет его адресату или получателю. Затем получатель интерпретирует сообщение в соответствии со своим умственным уровнем и опытом. Из приведенного выше утверждения ясно, что без источника нет концепции коммуникации. Так что это самый важный элемент.
Но, тем не менее, он должен быть очень простым и ясным, чтобы получатель мог легко понять утверждения или чувства получателя.
Значение декодирования в коммуникации
Было замечено, что коммуникационный процесс непрерывен. Этому нет конца, потому что один кодирует сообщение, а другой декодирует сообщение.
Успешное декодирование - это навык (например, внимательно читать и слушать сообщение для лучшего понимания). Декодирование означает, что сообщение, которое источник закодировал, затем декодер интерпретирует сообщение в соответствии со своим менталитетом и опытом.Итак, где сообщение простое и понятное. Тогда закодированное сообщение будет легко понято получателем. Так он легко и быстро снова расшифрует свое сообщение на
.Источник. Таким образом, процесс коммуникации будет понятным, и когда его получит, получатель легко поймет простое и ясное сообщение, а затем, используя все свое тонкое чутье, получатель декодирует сообщение для источника.
 8 = 256$, различных цветов. А ведь это уже ответ!
8 = 256$, различных цветов. А ведь это уже ответ!


 Если вы собираетесь транслировать сцены с высоким движением (например, гоночные игры, некоторые игры Battle Royale и т. Д.), Мы настоятельно рекомендуем уменьшить разрешение. Контент с высоким движением нельзя сжимать так сильно, и он может страдать от большего количества артефактов (ошибок кодирования), из-за которых ваш поток выглядит «блочным». Если вы уменьшите разрешение, вы уменьшите кодируемые данные, и в результате качество просмотра будет выше. Например, для Fortnite многие стримеры решают стримить с разрешением 1600×900 60 FPS.
Если вы собираетесь транслировать сцены с высоким движением (например, гоночные игры, некоторые игры Battle Royale и т. Д.), Мы настоятельно рекомендуем уменьшить разрешение. Контент с высоким движением нельзя сжимать так сильно, и он может страдать от большего количества артефактов (ошибок кодирования), из-за которых ваш поток выглядит «блочным». Если вы уменьшите разрешение, вы уменьшите кодируемые данные, и в результате качество просмотра будет выше. Например, для Fortnite многие стримеры решают стримить с разрешением 1600×900 60 FPS.