
Кодирование текстовой информации
Чаще всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.
Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке.
Пример 1
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как:
Стенография
Определение 1
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Пример 2
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
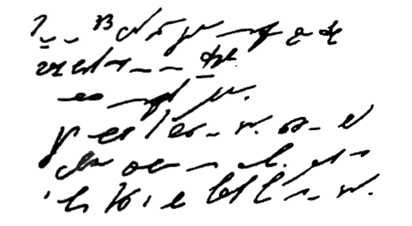
Рисунок 1.
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Замечание 1
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств.
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Пример 3
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.
Замечание 2
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Криптография
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью.
Определение 2
Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Определение 3
Криптография — это наука о методах и принципах передачи и приема зашифрованной с помощью специальных ключей информации.
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ — реализуют региональные языковые особенности.
Замечание 3
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.
Для решения этих проб
spravochnick.ru
ИНФОРМАТИКА | Энциклопедия Кругосвет
Содержание статьиИНФОРМАТИКА – техническая наука, систематизирующая приемы создания, хранения, обработки и передачи информации средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.
В англоязычных странах применяют термин computer science – компьютерная наука.
Теоретической основой информатики является группа фундаментальных наук таких как: теория информации, теория алгоритмов, математическая логика, теория формальных языков и грамматик, комбинаторный анализ и т.д. Кроме них информатика включает такие разделы, как архитектура ЭВМ, операционные системы, теория баз данных, технология программирования и многие другие. Важным в определении информатики как науки является то, что с одной стороны, она занимается изучением устройств и принципов действия средств вычислительной техники, а с другой – систематизацией приемов и методов работы с программами, управляющими этой техникой.
Информационная технология – это совокупность конкретных технических и программных средств, с помощью которых выполняются разнообразные операции по обработке информации во всех сферах нашей жизни и деятельности. Иногда информационную технологию называют компьютерной технологией или прикладной информатикой.
Информация аналоговая и цифровая.
Термин «информация» восходит к латинскому informatio,– разъяснение, изложение, осведомленность.
Информацию можно классифицировать разными способами, и разные науки это делают по-разному. Например, в философии различают информацию объективную и субъективную. Объективная информация отражает явления природы и человеческого общества. Субъективная информация создается людьми и отражает их взгляд на объективные явления.
В информатике отдельно рассматривается аналоговая информация и цифровая. Это важно, поскольку человек благодаря своим органам чувств, привык иметь дело с аналоговой информацией, а вычислительная техника, наоборот, в основном, работает с цифровой информацией.
Человек воспринимает информацию с помощью органов чувств. Свет, звук, тепло – это энергетические сигналы, а вкус и запах – это результат воздействия химических соединений, в основе которого тоже энергетическая природа. Человек испытывает энергетические воздействия непрерывно и может никогда не встретиться с одной и той же их комбинацией дважды. Нет двух одинаковых зеленых листьев на одном дереве и двух абсолютно одинаковых звуков – это информация аналоговая. Если же разным цветам дать номера, а разным звукам – ноты, то аналоговую информацию можно превратить в цифровую.
Музыка, когда ее слушают, несет аналоговую информацию, но если записать ее нотами, она становится цифровой.
Разница между аналоговой информацией и цифровой, прежде всего, в том, что аналоговая информация непрерывна, а цифровая дискретна.
К цифровым устройствам относятся персональные компьютеры – они работают с информацией, представленной в цифровой форме, цифровыми являются и музыкальные проигрыватели лазерных компакт дисков.
Кодирование информации.
Кодирование информации – это процесс формирования определенного представления информации.
В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью компьютерных программ можно преобразовывать полученную информацию, например «наложить» друг на друга звуки от разных источников.
Аналогично на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми.
Единицы измерения информации. Бит. Байт.
Бит – наименьшая единица представления информации. Байт – наименьшая единица обработки и передачи информации.
Решая различные задачи, человек использует информацию об окружающем нас мире. Часто приходится слышать, что сообщение несет мало информации или, наоборот, содержит исчерпывающую информацию, при этом разные люди, получившие одно и то же сообщение (например, прочитав статью в газете), по-разному оценивают количество информации, содержащейся в нем. Это означает, что знания людей об этих событиях (явлениях) до получения сообщения были различными. Количество информации в сообщении, таким образом, зависит от того, насколько ново это сообщение для получателя. Если в результате получения сообщения достигнута полная ясность в данном вопросе (т.е. неопределенность исчезнет), говорят, что получена исчерпывающая информация. Это означает, что нет необходимости в дополнительной информации на эту тему. Напротив, если после получения сообщения неопределенность осталась прежней (сообщаемые сведения или уже были известны, или не относятся к делу), значит, информации получено не было (нулевая информация).
Подбрасывание монеты и слежение за ее падением дает определенную информацию. Обе стороны монеты «равноправны», поэтому одинаково вероятно, что выпадет как одна, так и другая сторона. В таких случаях говорят, что событие несет информацию в 1 бит. Если положить в мешок два шарика разного цвета, то, вытащив вслепую один шар, мы также получим информацию о цвете шара в 1 бит.
Единица измерения информации называется бит (bit) – сокращение от английских слов binary digit, что означает двоичная цифра.
В компьютерной технике бит соответствует физическому состоянию носителя информации: намагничено – не намагничено, есть отверстие – нет отверстия. При этом одно состояние принято обозначать цифрой 0, а другое – цифрой 1. Выбор одного из двух возможных вариантов позволяет также различать логические истину и ложь. Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию. Такой метод представления информации называется двоичным кодированием (binary encoding).
В информатике часто используется величина, называемая байтом (byte) и равная 8 битам. И если бит позволяет выбрать один вариант из двух возможных, то байт, соответственно, 1 из 256 (28). Наряду с байтами для измерения количества информации используются более крупные единицы:
1 Кбайт (один килобайт) = 2\up1210 байт = 1024 байта;
1 Мбайт (один мегабайт) = 2\up1210 Кбайт = 1024 Кбайта;
1 Гбайт (один гигабайт) = 2\up1210 Мбайт = 1024 Мбайта.
Например, книга содержит 100 страниц; на каждой странице – 35 строк, в каждой строке – 50 символов. Объем информации, содержащийся в книге, рассчитывается следующим образом:
Страница содержит 35 × 50 = 1750 байт информации. Объем всей информации в книге (в разных единицах):
1750 × 100 = 175 000 байт.
175 000 / 1024 = 170,8984 Кбайт.
170,8984 / 1024 = 0,166893 Мбайт.
Файл. Форматы файлов.
Файл – наименьшая единица хранения информации, содержащая последовательность байтов и имеющая уникальное имя.
Основное назначение файлов – хранить информацию. Они предназначены также для передачи данных от программы к программе и от системы к системе. Другими словами, файл – это хранилище стабильных и мобильных данных. Но, файл – это нечто большее, чем просто хранилище данных. Обычно файл имеет имя, атрибуты, время модификации и время создания.
Файловая структура представляет собой систему хранения файлов на запоминающем устройстве, например, на диске. Файлы организованы в каталоги (иногда называемые директориями или папками). Любой каталог может содержать произвольное число подкаталогов, в каждом из которых могут храниться файлы и другие каталоги.
Способ, которым данные организованы в байты, называется форматом файла.
Для того чтобы прочесть файл, например, электронной таблицы, нужно знать, каким образом байты представляют числа (формулы, текст) в каждой ячейке; чтобы прочесть файл текстового редактора, надо знать, какие байты представляют символы, а какие шрифты или поля, а также другую информацию.
Программы могут хранить данные в файле способом, выбираемым программистом. Часто предполагается, однако, что файлы будут использоваться различными программами, поэтому многие прикладные программы поддерживают некоторые наиболее распространенные форматы, так что другие программы могут понять данные в файле. Компании по производству программного обеспечения (которые хотят, чтобы их программы стали «стандартами»), часто публикуют информацию о создаваемых ими форматах, чтобы их можно было бы использовать в других приложениях.
Все файлы условно можно разделить на две части – текстовые и двоичные.
Текстовые файлы – наиболее распространенный тип данных в компьютерном мире. Для хранения каждого символа чаще всего отводится один байт, а кодирование текстовых файлов выполняется с помощью специальных таблиц, в которых каждому символу соответствует определенное число, не превышающее 255. Файл, для кодировки которого используется только 127 первых чисел, называется ASCII—файлом (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией), но в таком файле не могут быть представлены буквы, отличные от латиницы (в том числе и русские). Большинство национальных алфавитов можно закодировать с помощью восьмибитной таблицы. Для русского языка наиболее популярны на данный момент три кодировки: Koi8-R, Windows-1251 и, так называемая, альтернативная (alt) кодировка.
Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов. Для экономии места зачастую применяется следующий прием: некоторые символы кодируются с помощью одного байта, в то время как для других используются два или более байтов. Одной из попыток обобщения такого подхода является стандарт Unicode, в котором для кодирования символов используется диапазон чисел от нуля до 65 536. Такой широкий диапазон позволяет представлять в численном виде символы языка любого уголка планеты.
Но чисто текстовые файлы встречаются все реже. Документы часто содержат рисунки и диаграммы, используются различные шрифты. В результате появляются форматы, представляющие собой различные комбинации текстовых, графических и других форм данных.
Двоичные файлы, в отличие от текстовых, не так просто просмотреть, и в них, обычно, нет знакомых слов – лишь множество непонятных символов. Эти файлы не предназначены непосредственно для чтения человеком. Примерами двоичных файлов являются исполняемые программы и файлы с графическими изображениями.
Примеры двоичного кодирования информации.
Среди всего разнообразия информации, обрабатываемой на компьютере, значительную часть составляют числовая, текстовая, графическая и аудиоинформация. Познакомимся с некоторыми способами кодирования этих типов информации в ЭВМ.
Кодирование чисел.
Есть два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, нужно:
1) перевести число N в двоичную систему счисления;
2) полученный результат дополнить слева незначащими нулями до k разрядов.
Например, для получения внутреннего представления целого числа 1607 в 2-х байтовой ячейке число переводится в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке имеет вид: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (–N) нужно:
1) получить внутреннее представление положительного числа N;
2) получить обратный код этого числа, заменяя 0 на 1 и 1 на 0;
3) полученному числу прибавить 1 к полученному числу.
Внутреннее представление целого отрицательного числа –1607. С использованием результата предыдущего примера и записывается внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Обратный код получается инвертированием: 1111 1001 1011 1000. Добавляется единица: 1111 1001 1011 1001 – это и есть внутреннее двоичное представление числа –1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p.
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12,345 = 0,0012345 × 104 = 1234,5 × 10-2 = 0,12345 × 102
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию:
0,1p Ј m p. Иначе говоря, мантисса меньше 1 и первая значащая цифра – не ноль (p – основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12,345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12 345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере – это 2.
Кодирование текста.
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 28 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Все символы такого алфавита пронумерованы от 0 до 255, а каждому номеру соответствует 8-разрядный двоичный код от 00000000 до 11111111. Этот код является порядковым номером символа в двоичной системе счисления.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов.
Кодирование графической информации.
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится – не светится), а для его кодирования достаточно одного бита памяти: 1 – белый, 0 – черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 – черный, 10 – зеленый, 01 – красный, 11 – коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов – красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
| R | R |
| G | G |
| B | B |
| цвет | цвет |
| 0 | 1 |
| 0 | 0 |
| 0 | 0 |
| черный | красный |
| 0 | 1 |
| 0 | 0 |
| 1 | 1 |
| синий | розовый |
| 0 | 1 |
| 1 | 1 |
| 0 | 0 |
| зеленый | коричневый |
| 0 | 1 |
| 1 | 1 |
| 1 | 1 |
| голубой | белый |
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов – К и количество битов для их кодировки – N связаны между собой простой формулой: 2N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
Кодирование звука.
Из физики известно, что звук – это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), то видно плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой – аналоговый – сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Делается это, например, так – измеряется напряжение через равные промежутки времени и полученные значения записываются в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его – аналого-цифровым преобразователем (АЦП).
Чтобы воспроизвести закодированный таким образом звук, нужно сделать обратное преобразование (для этого служит цифро-аналоговый преобразователь – ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук, но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Издавна используется довольно компактный способ представления музыки – нотная запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Есть и другие, чисто компьютерные, форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18–20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200. Одна песня занимает, примерно, 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Компьютер – универсальная информационная машина.
Одно из основных назначений компьютера – обработка и хранение информации. С появлением ЭВМ стало возможным оперировать немыслимыми ранее объемами информации. В электронную форму переводят библиотеки, содержащие научную и художественную литературы. Старые фото- и кино-архивы обретают новую жизнь в цифровой форме.
Анна Чугайнова
www.krugosvet.ru
Информатика — Кодирование
1. Основные понятия
Закодировать текст – значит сопоставить ему другой текст. Кодирование применяется при передаче данных – для того, чтобы зашифровать текст от посторонних, чтобы сделать передачу данных более надежной, потому что канал передачи данных может передавать только ограниченный набор символов (например, — только два символа, 0 и 1) и по другим причинам.
При кодировании заранее определяют алфавит, в котором записаны исходные тексты (исходный алфавит) и алфавит, в котором записаны закодированные тексты (коды), этот алфавит называется кодовым алфавитом. В качестве кодового алфавита часто используют двоичный алфавит, состоящий из двух символов (битов) 0 и 1. Слова в двоичном алфавите иногда называют битовыми последовательностями.
2. Побуквенное кодирование
Наиболее простой способ кодирования – побуквенный. При побуквенном кодировании каждому символу из исходного алфавита сопоставляется кодовое слово – слово в кодовом алфавите. Иногда вместо «кодовое слово буквы» говорят просто «код буквы». При побуквенном кодировании текста коды всех символов записываются подряд, без разделителей.
Пример 1. Исходный алфавит – алфавит русских букв, строчные и прописные буквы не различаются. Размер алфавита – 33 символа.
Кодовый алфавит – алфавит десятичных цифр. Размер алфавита — 10 символов.
Применяется побуквенное кодирование по следующему правилу: буква кодируется ее номером в алфавите: код буквы А – 1; буквы Я – 33 и т.д.
Тогда код слова АББА – это 1221.
Внимание: Последовательность 1221 может означать не только АББА, но и КУ (К – 12-я буква в алфавите, а У – 21-я буква). Про такой код говорят, что он НЕ допускает однозначного декодирования
Пример 2. Исходный и кодовый алфавиты – те же, что в примере 1. Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А – 01, код Б – 02 и т.д.
В этом случае кодом текста АББА будет 01020201. И расшифровать этот код можно только одним способом. Для расшифровки достаточно разбить кодовый текст 01020201 на двойки: 01 02 02 01 и для каждой двойки определить соответствующую ей букву.
Такой способ кодирования называется равномерным. Равномерное кодирование всегда допускает однозначное декодирование.
Далее рассматривается только побуквенное кодирование
3. Неравномерное кодирование
Равномерное кодирование удобно для декодирования. Однако часто применяют и неравномерные коды, т.е. коды с различной длиной кодовых слов. Это полезно, когда в исходном тексте разные буквы встречаются с разной частотой. Тогда часто встречающиеся символы стоит кодировать более короткими словами, а редкие – более длинными. Из примера 1 видно, что (в отличие от равномерных кодов!) не все неравномерные коды допускают однозначное декодирование.
Есть простое условие, при выполнении которого неравномерный код допускает однозначное декодирование.
Код называется префиксным, если в нем нет ни одного кодового слова, которое было бы началом (по-научному, — префиксом) другого кодового слова.
Код из примера 1 – НЕ префиксный, так как, например, код буквы А (т.е. кодовое слово 1) – префикс кода буквы К (т.е. кодового слова 12, префикс выделен жирным шрифтом).
Код из примера 2 (и любой другой равномерный код) – префиксный: никакое слово не может быть началом слова той же длины.
Пример 3. Пусть исходный алфавит включает 9 символов: А, Л, М, О, П, Р, У, Ы, -. Кодовый алфавит – двоичный. Кодовые слова:
А: 00 М: 01 -: 100 Л: 101 У: 1100 Ы: 1101 Р: 1110 О: 11110 П: 11111Кодовые слова выписаны в алфавитном порядке. Видно, что ни одно из них не является началом другого. Это можно проиллюстрировать рисунком
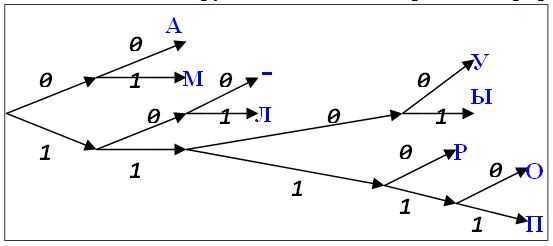 На рисунке изображено бинарное дерево. Его корень расположен слева. Из каждого внутреннего узла выходит два ребра. Верхнее ребро имеет пометку 0, нижнее – пометку 1. Таким образом, каждому узлу соответствует слово в двоичном алфавите. Если слово X является началом (префиксом) слова Y, то узел, соответствующий слову X, находится на пути из корня в узел, соответствующий слову Y. Наши кодовые слова находятся в листьях дерева. Поэтому ни одно из них не является началом другого.
На рисунке изображено бинарное дерево. Его корень расположен слева. Из каждого внутреннего узла выходит два ребра. Верхнее ребро имеет пометку 0, нижнее – пометку 1. Таким образом, каждому узлу соответствует слово в двоичном алфавите. Если слово X является началом (префиксом) слова Y, то узел, соответствующий слову X, находится на пути из корня в узел, соответствующий слову Y. Наши кодовые слова находятся в листьях дерева. Поэтому ни одно из них не является началом другого.
Теорема (условие Фано). Любой префиксный код (а не только равномерный) допускает однозначное декодирование.
Разбор примера (вместо доказательства). Рассмотрим закодированный текст, полученный с помощью кода из примера 3:
0100010010001110110100100111000011100
Будем его декодировать таким способом. Двигаемся слева направо, пока не обнаружим код какой-то буквы. 0 – не кодовое слово, а 01 – код буквы М.
0100010010001110110100100111000011100
Значит, исходный текст начинается с буквы М: код никакой другой буквы не начинается с 01! «Отложим» начальные 01 в сторону и продолжим.
01 00010010001110110100100111000011100 МДалее таким же образом находим следующее кодовое слово 00 – код буквы А.
01 00010010001110110100100111000011100 М АДоведите расшифровку текста до конца самостоятельно. Убедитесь, что он расшифровывается (декодируется) однозначно.
Замечание. В расшифрованном тексте 14 букв. Т.к. в алфавите 9 букв, то при равномерном двоичном кодировании пришлось бы использовать кодовые слова длины 4. Таким образом, при равномерном кодировании закодированный текст имел бы длину 56 символов – в полтора раза больше, чем в нашем примере (у нас 37 символов).
4. Как все это повторять. Задачи на понимание
Знание приведенного выше материала достаточно для решения задачи 5 из демо-варианта и близких к ней (см. здесь). Повторять (учить) этот материал стоит в том порядке, в котором он изложен. При этом нужно решать простые задачи – до тех пор, пока не будет достигнуто полное понимание. Ниже приведены возможные типы таких задач. Опытные учителя легко придумают (или подберут) конкретные задачи таких типов. Если будут вопросы – пишите.
1) Понятие побуквенного кодирования.
Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Закодировать заданный текст в алфавите Ф. Коды могут быть с использованием разных кодовых алфавитов, равномерные и неравномерные.
2) Префиксные неравномерные коды.
2.1) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Построить дерево кода (см. рис.1) и убедиться, что код – префиксный.
2.2) Дан алфавит Ф и двоичный префиксный код для этого алфавита. Декодировать (анализом слева направо) данный текст в кодовом алфавите.
2.3) Дан алфавит Ф и кодовые слова для всех слов в алфавите Ф. Определить, является ли данный код префиксным, или нет. В качестве примеров полезно приводить:
— Равномерный код. — Неравномерный префиксный код (полезно нарисовать депево этого кода как на рис.1). — Различные пополнения данного неравномерного префиксного кода с помощью кода еще одной буквы так, чтобы полученный код либо оставался префиксным, либо переставал им быть. При анализе дополнительной буквы полезно использовать дерево исходного кода. Полезно рассмотреть различные варианты «потери префиксности»: (а) новый код – начало одного из старых; (б) один из старых кодов – начало нового.2.4) Решать задачи для самостоятельного решения, например, отсюда
ege-go.ru
Сценария урока по информатике «Кодирование текста» (9 класс)
Практическая работа «Кодирование текстовой информации. Определение числовых кодов символов и перекодировка русскоязычного текста в текстовом редакторе».
15. Организация деятельности учащихся на уроке:
-самостоятельно выходят на проблему и решают её;
-самостоятельно определяют тему, цели урока;
-рефлектируют.
Приветствие, постановка целей и задач урока, психологический настрой
— Добрый день, ребята! На столах у вас по три смайлика, выберите тот, который соответствует вашему настроению.
— Как много улыбок засветилось. Спасибо!
— А это моё настроение… Я готова продуктивно сотрудничать с вами. Удачи!
2. Актуализация знаний и фиксация затруднений в деятельности.
● ▬ ▬ ●● ▬ ▬ ▬ ● ▬ ● ▬ ▬ ▬ ●● ▬или в двоичном коде: 01100111010111001
Таким образом, получили двоичный код слова «память»
А теперь попробуем расшифровать следующий код: 001010111101
● ● ▬ ● ▬ ●▬ ▬ ▬ ▬ ● ▬
Кто справился? У кого нет ответа?
Учитель:Что вы не смогли сделать?
Учитель:Рассмотрите это задание. Что мешает вам расшифровать его?
С остальными буквами ситуация не легче.
3. Выявление причин затруднения и постановка цели деятельности.
Учитель: Значит в чем причина затруднения?
Учитель: Сформулируйте цель урока.
Учитель: Сформулируйте тему урока.
Запишите в тетрадь число и тему урока.
4.Построение проекта выхода из затруднения.
Учитель: Что вам может помочь в достижении цели?
Учитель: Составьте план действий.
5. Первичное закрепление во внешней речи.
Историческая справка (слайд 3, 4)
Учитель: А что происходит, когда символ выводится на экран монитора?
(слайд 5)
Учитель: А если много символов подряд вводится? Компьютер также как и мы запутается, но мы знаем, что компьютер – бездумный исполнитель алгоритмов. Как же ему помочь?
Учитель: Если мы сделаем длину кода (количество двоичных цифр в коде) постоянной?
Например, код символа “d” – 1100100 (7 цифр)
“я” – 11101111 ( 8 цифр)
Как можно сделать одинаковую длину? Какая длина должна быть?
Почему?
Учитель:Запомнить! Цепочка из 8 «0» и «1» называется БАЙТ. (слайд 6)
Учитель:Что нужно сделать с кодами длина которых меньше 8-ми? Если мы к любому десятичному числу припишем слева «0» или несколько нулей, оно измениться?
Учитель:А код – это тоже число, только двоичное. Можем дописать столько «0», сколько не хватает до 8-ми цифр.
Тогда код символа “d” – 01100100 (8 цифр). (слайд 7, 8)
Учитель:Теперь осталось определить какой код – какому символу соответствует. Для этого была создана кодовая таблица ASCII(American Standard Code for Information Interchange). В таблице каждому символу компьютерного алфавита (т.е. символы, которые можно набрать с помощью клавиатуры ) ставится в соответствие двоичное число. (слайд 9, 10)
Учитель: Кодовая таблица в система Windows (слайд 11)
Учитель:Теперь компьютер может поделить весь двоичный код на группы по 8 символов и бездумно декодировать их.
Учитель:Знакомимся с другими таблицами кодировки: кодировка русского алфавита, таблица кодировки Unicode, таблицы кодировки русскоязычных символов (слайд 12, 13, 14, 15).
Учитель:Кодирования символов в различных таблицах (слайд 16)
6. Первичное закрепление во внешней речи. Самостоятельная работа с самопроверкой.
Учитель: Задание 1. Закодировать с помощью ASCII-таблицы: «Информатике учиться всегда пригодится».
Включение в систему знаний и повторение.
Задание 2. Декодировать с помощью ASCII-таблицы:
11010000 10010100 11010000 10111110 11010001 10000000 11010000 10111110 11010000 10110011 11010001 10000011 100000 11010000 10111110 11010001 10000001 11010000 10111000 11010000 10111011 11010000 10111000 11010001 10000010 100000 11010000 10111000 11010000 10110100 11010001 10000011 11010001 10001001 11010000 10111000 11010000 10111001 101100 100000 11010000 10110000 100000 11010000 10111000 11010000 10111101 11010001 10000100 11010000 10111110 11010001 10000000 11010000 10111100 11010000 10110000 11010001 10000010 11010000 10111000 11010000 10111010 11010001 10000011 100000 101101 100000 11010000 10111100 11010001 10001011 11010001 10000001 11010000 10111011 11010001 10001111 11010001 10001001 11010000 10111000 11010000 10111001
Рефлексия деятельности
— Исследование какой темы вели на уроке?
— Какие понятия разобрали?
— Удалось решить поставленную задачу?
— Каким способом?
— Какие получили результаты?
— Что нужно сделать ещё?
— Где можно применить новые знания?
— Оцените свою работу на уроке. Работу класса
— Выберите смайлик своего настроения. Изменилось ли оно? Почему?
Домашнее задание произвести кодирование стихотворения из 4-х строк (до 100 символов), п. 3.1. (слайд 19)
Технологическая карта урока
Название используемых ЭОР(с указанием порядкового номера из Таблицы 2)
Деятельность учителя
(с указанием действий, например, демонстрация ЭОР)
Деятельность ученика
УУД
Время
(в мин.)
1
Организационный момент (мотивация к учебной деятельности)
1
Приветствие, постановка целей и задач урока, психологический настрой
— Добрый день, ребята! На столах у вас по три смайлика, выберите тот, который соответствует вашему настроению.
— Как много улыбок засветилось. Спасибо!
— А это моё настроение… Я готова продуктивно сотрудничать с вами. Удачи!
Выбирают смайлик и демонстрируют своё настроение
Самоопределение, смыслообразование (Л)
Целеполагание (П)
Планирование учебного сотрудничества (К)
2
2
Актуализация знаний
2
1
Вспомните. Чем мы занимались на последних уроках информатики?
Какие коды мы еще знаем, вспомните, какими способами мы шифровали информацию? (обсуждаем ответы)
На слайде азбука «Морзе» (слайд 2)
Сколько знаков используется в данном коде?
Какие это знаки?
Что это вам напоминает?
Заменим «●» – на «0» , «▬» – на «1»
Давайте зашифруем слово «память»:
● ▬ ▬ ●● ▬ ▬ ▬ ● ▬ ● ▬ ▬ ▬ ●● ▬или в двоичном коде: 01100111010111001
Таким образом, получили двоичный код слова «память»
А теперь попробуем расшифровать следующий код: 001010111101
● ● ▬ ● ▬ ●▬ ▬ ▬ ▬ ● ▬
Кто справился? У кого нет ответа?
Что вы не смогли сделать?
Рассмотрите это задание. Что мешает вам расшифровать его?
С остальными буквами ситуация не легче.
Значит в чем причина затруднения?
Сформулируйте цель урока.
Сформулируйте тему урока.
Запишите в тетрадь число и тему урока.
Что вам может помочь в достижении цели?
Составьте план действий.
Историческая справка (слайд 3, 4)
1.Узнали, что всякая информация в ПК представляется в виде «0» и «1», т.е. в двоичном коде
2. Азбука Морзе, числа.
Два
«точка» и «тире»
Два символа -двоичный код
«урок»
Мы не смогли расшифровать слово одним способом.
Первой буквой может быть Е (● ), И(● ●) , У(● ● ▬ ), Ф(● ● ▬ ● .
Много кодов подходит, потому что не знаем длины кода, она всегда разная, посмотрим таблицу : длина ровна от 1 до 6
узнать как кодируются текстовая информация в памяти компьютера.
Кодирование текстовой информации
Изученное на прошлом уроке.
Чтобы кодировать информацию нужно сделать одинаковую длину кода
Анализ объектов с целью выделения признаков; подведение под понятие; целеполагание (П)
Выполнение пробного учебного действия; фиксирование индивидуального затруднения; саморегуляция в ситуации затруднения (Р)
Выражение своих мыслей; аргументация своего мнения; учёт разных мнений (К)
6
3
Проблемное объяснение нового знания
1
Что происходит в компьютере, когда мы нажимаем какую-либо клавишу на клавиатуре?
А что происходит, когда символ выводится на экран монитора?
(слайд 5)
А если много символов подряд вводится? Компьютер также как и мы запутается, но мы знаем, что компьютер – бездумный исполнитель алгоритмов. Как же ему помочь?
Если мы сделаем длину кода (количество двоичных цифр в коде) постоянной?
Например, код символа “d” – 1100100 (7 цифр)
“я” – 11101111 ( 8 цифр)
Как можно сделать одинаковую длину? Какая длина должна быть?
Почему?
Запомнить! Цепочка из 8 «0» и «1» называется БАЙТ. (слайд 6)
Что нужно сделать с кодами длина которых меньше 8-ми? Если мы к любому десятичному числу припишем слева «0» или несколько нулей, оно измениться?
А код – это тоже число, только двоичное. Можем дописать столько «0», сколько не хватает до 8-ми цифр.
Тогда код символа “d” – 01100100 (8 цифр). (слайд 7, 8)
Теперь осталось определить какой код – какому символу соответствует. Для этого была создана кодовая таблица ASCII(American Standard Code for Information Interchange). В таблице каждому символу компьютерного алфавита (т.е. символы, которые можно набрать с помощью клавиатуры ) ставится в соответствие двоичное число. (слайд 9, 10)
Кодовая таблица в система Windows (слайд 11)
Теперь компьютер может поделить весь двоичный код на группы по 8 символов и бездумно декодировать их.
Знакомимся с другими таблицами кодировки: кодировка русского алфавита, таблица кодировки Unicode, таблицы кодировки русскоязычных символов (слайд 12, 13, 14, 15).
Кодирования символов в различных таблицах (слайд 16)
Задание. Декодировать текст с помощью кодовой таблицы ASCII 111 109 112 117 116 101 114 (слайд 17)
Задание. Работа в текстовом редакторе MS Word (слайд 18)
Происходит кодирование нажатого символа при помощи двоичного кода и запись полученного кода передается в оперативную память.
Происходит обратный процесс – декодирование (в памяти двоичный код , а на экране символ )
Надо выбрать максимальную из возможных длин (8).
Чтобы было возможно закодировать символы код которых имеет длину 8.
Нет.
Обучающимся раздаются соответствующие кодовые таблицы, декодируют текст и получают computer.
Обучающиеся выполняют задание на компьютере в MS Word.
Поиск и выделение информации; синтез как составление целого из частей; подведение под понятие; выдвижение гипотез и их обоснование; самостоятельное создание способа решения проблемы поискового характера (П)
Аргументация своего мнения и позиции в коммуникации; учёт разных мнений (К)
16
Физическая минутка.
4
Закрепление
2
Практическое задание выполняется
Задание 1. Закодировать с помощью ASCII-таблицы: «Информатике учиться всегда пригодится».
Задание 2. Декодировать с помощью ASCII-таблицы:
11010000 10010100 11010000 10111110 11010001 10000000 11010000 10111110 11010000 10110011 11010001 10000011 100000 11010000 10111110 11010001 10000001 11010000 10111000 11010000 10111011 11010000 10111000 11010001 10000010 100000 11010000 10111000 11010000 10110100 11010001 10000011 11010001 10001001 11010000 10111000 11010000 10111001 101100 100000 11010000 10110000 100000 11010000 10111000 11010000 10111101 11010001 10000100 11010000 10111110 11010001 10000000 11010000 10111100 11010000 10110000 11010001 10000010 11010000 10111000 11010000 10111010 11010001 10000011 100000 101101 100000 11010000 10111100 11010001 10001011 11010001 10000001 11010000 10111011 11010001 10001111 11010001 10001001 11010000 10111000 11010000 10111001
выполняется в группах, каждой группе необходимо закодировать слово, затем расставить полученные слова так, чтобы получилось предложение). В группе договариваются кто будет вводить правильный ответ в интеллектуальную карту
Анализ объектов с целью выделения признаков и синтез как составления целого из частей; подведение под понятие; выдвижение гипотез и их обоснование (П)
Выражение своих мыслей с полнотой и точностью; формулирование и аргументация своего мнения; учёт разных мнений (К)
Оценивание усвоенного содержания (Л)
Контроль, коррекция, оценка (Р)
16
5
Итог урока (рефлексия деятельности)
2
1
— Исследование какой темы вели на уроке?
— Какие понятия разобрали?
— Удалось решить поставленную задачу?
— Каким способом?
— Какие получили результаты?
— Что нужно сделать ещё?
— Где можно применить новые знания?
— Оцените свою работу на уроке. Работу класса
— Выберите смайлик своего настроения. Изменилось ли оно? Почему?
Домашнее задание произвести кодирование стихотворения из 4-х строк (до 100 символов), п. 3.1. (слайд 19)
Дают ответы на вопросы
Анализируют работу на уроке через самооценку
Записывают домашнее задание
Рефлексия способов и условий действия; контроль и оценка процесса и результатов деятельности (П)
Самооценка; адекватное понимания причин успеха или неуспеха в УД; следование в поведении моральным нормам и этическим требованиям (Л)
Выражение своих мыслей полно и точно; формулирование и аргументация своего мнения, учёт разных мнений (К)
5
Приложение 1
Организационный момент (мотивация к учебной деятельности) I этап урока
«Покажи своё лицо»
infourok.ru
Кодирование текстовой информации в компьютере :: SYL.ru
Кодирование текстовой информации в компьютере – порой неотъемлемое условие корректной работы устройства или отображения того или иного фрагмента. Как происходит этот процесс в ходе работы компьютера с текстом и визуальной информацией, звуком – все это мы разберем в данной статье.
Вступление

Электронная вычислительная машина (которую мы в повседневной жизни называем компьютером) воспринимает текст весьма специфично. Для нее кодирование текстовой информации очень важно, поскольку она воспринимает каждый текстовый фрагмент в качестве группы обособленных друг от друга символов.
Какие бывают символы?

В роли символов для компьютера выступают не только русские, английские и другие буквы, но и еще знаки препинания, а также другие знаки. Даже пробел, которым мы разделяем слова при печатании на компьютере, устройство воспринимает как символ. Чем-то очень напоминает высшую математику, ведь там, по мнению многих профессоров, ноль имеет двойное значение: он и является числом, и одновременно ничего не обозначает. Даже для философов вопрос пробела в тексте может стать актуальной проблемой. Шутка, конечно, но, как говорится, в каждой шутке есть доля правды.
Какая бывает информация?

Итак, для восприятия информации компьютеру необходимо запустить процессы обработки. А какая вообще бывает информация? Темой этой статьи является кодирование текстовой информации. Мы уделим особенное внимание этой задаче, но разберемся и с другими микротемами.
Информация может быть текстовой, числовой, звуковой, графической. Компьютер должен запустить процессы, обеспечивающие кодирование текстовой информации, чтобы вывести на экран то, что мы, например, печатаем на клавиатуре. Мы будем видеть символы и буквы, это понятно. А что же видит машина? Она воспринимает абсолютно всю информацию – и речь сейчас идет не только о тексте – в качестве определенной последовательности нулей и единиц. Они составляют основу так называемого двоичного кода. Соответственно, процесс, который преобразует поступающую на устройство информацию в понятную ему, имеет название “двоичное кодирование текстовой информации”.
Краткий принцип действия двоичного кода

Почему наибольшее распространение в электронных машинах получило именно кодирование информации двоичным кодом? Текстовой основой, которая кодируется при помощи нулей и единиц, может быть абсолютно любая последовательность символов и знаков. Однако это не единственное преимущество, которое имеет двоичное текстовое кодирование информации. Все дело в том, что принцип, на котором устроен такой способ кодирования, очень прост, но в то же время достаточно функционален. Когда есть электрический импульс, его маркируют (условно, конечно) единицей. Нет импульса – маркируют нулем. То есть текстовое кодирование информации базируется на принципе построения последовательности электрических импульсов. Логическая последовательность, составленная из символов двоичного кода, называется машинным языком. В то же время кодирование и обработка текстовой информации при помощи двоичного кода позволяют осуществлять операции за достаточно краткий промежуток времени.
Биты и байты

Цифра, воспринимаемая машиной, кроет в себе некоторое количество информации. Оно равно одному биту. Это касается каждой единицы и каждого нуля, которые составляют ту или иную последовательность зашифрованной информации.
Соответственно, количество информации в любом случае можно определить, просто зная количество символов в последовательности двоичного кода. Они будут численно равны между собой. 2 цифры в коде несут в себе информацию объемом в 2 бита, 10 цифр – 10 бит и так далее. Принцип определения информационного объема, который кроется в том или ином фрагменте двоичного кода, достаточно прост, как вы видите.
Кодирование текстовой информации в компьютере
Вот сейчас вы читаете статью, которая состоит из последовательности, как мы считаем, букв алфавита русского языка. А компьютер, как говорилось ранее, воспринимает всю информацию (и в данном случае тоже) в качестве последовательности не букв, а нулей и единиц, обозначающих отсутствие и наличие электрического импульса.
Все дело в том, что закодировать один символ, который мы видим на экране, можно при помощи условной единицы измерения, называемой байтом. Как написано выше, у двоичного кода есть так называемая информационная нагрузка. Напомним, что численно она равняется суммарному количеству нулей и единиц в выбранном фрагменте кода. Так вот, 8 бит составляют 1 байт. Комбинации сигналов при этом могут быть самыми разными, как это легко можно заметить, нарисовав на бумаге прямоугольник, состоящий из 8 ячеек равного размера.
Выходит, что закодировать текстовую информацию можно при помощи алфавита, имеющего мощность 256 символов. В чем заключается суть? Смысл кроется в том, что каждый символ будет обладать своим двоичным кодом. Комбинации, “привязываемые” к определенным символам, начинаются от 00000000 и заканчиваются 11111111. Если переходить от двоичной к десятичной системе счисления, то кодировать информацию в такой системе можно от 0 до 255.
Не стоит забывать о том, что сейчас есть различные таблицы, которые используют кодировку букв русского алфавита. Это, например, ISO и КОИ-8, Mac и CP в двух вариациях: 1251 и 866. Легко убедиться в том, что текст, закодированный в одной из таких таблиц, не отобразится корректно в отличной от данной кодировке. Это происходит из-за того, что в разных таблицах к одному и тому же двоичному коду соответствуют различные символы.
Поначалу это было проблемой. Однако в настоящее время в программах уже встроены специальные алгоритмы, которые конвертируют текст, приводя его к корректному виду. 1997 год ознаменовался созданием кодировки под названием Unicode. В ней каждый символ имеет в своем распоряжении сразу 2 байта. Это позволяет закодировать текст, имеющий гораздо большее количество символов. 256 и 65536: есть ведь разница?
Кодирование графики
Кодирование текстовой и графической информации имеет некоторые схожие моменты. Как известно, для вывода графической информации используется периферийное устройство компьютера под названием “монитор”. Графика сейчас (речь идет сейчас именно о компьютерной графике) широко используется в самых разных сферах. Благо, аппаратные возможности персональных компьютеров позволяют решать достаточно сложные графические задачи.
Обрабатывать видеоинформацию стало возможным в последние годы. Но текст при этом значительно “легче” графики, что, в принципе, понятно. Из-за этого конечный размер файлов графики необходимо увеличивать. Преодолеть подобные проблемы можно, зная суть, в которой представляется графическая информация.
Давайте для начала разберемся, на какие группы подразделяется данный вид информации. Во-первых, это растровая. Во-вторых, векторная.
Растровые изображения достаточно схожи с клетчатой бумагой. Каждая клетка на такой бумаге закрашивается тем или иным цветом. Такой принцип чем-то напоминает мозаику. То есть получается, что в растровой графике изображение разбивается на отдельные элементарные части. Их именуют пикселями. В переводе на русский язык пиксели обозначают “точки”. Логично, что пиксели упорядочены относительно строк. Графическая сетка состоит как раз из определенного количества пикселей. Ее также называют растром. Принимая во внимание эти два определения, можно сказать, что растровое изображение является не чем иным, как набором пикселей, которые отображаются на сетке прямоугольного типа.
Растр монитора и размер пикселя влияют на качество изображения. Оно будет тем выше, чем больше растр у монитора. Размеры растра — это разрешение экрана, о котором наверняка слышал каждый пользователь. Одной из наиболее важных характеристик, которые имеют экраны компьютера, является разрешающая способность, а не только разрешение. Оно показывает, сколько пикселей приходится на ту или иную единицу длины. Обычно разрешающая способность монитора измеряется в пикселях на дюйм. Чем больше пикселей будет приходиться на единицу длины, тем выше будет качество, поскольку “зернистость” при этом снижается.
Обработка звукового потока
Кодирование текстовой и звуковой информации, как и другие виды кодирования, имеет некоторые особенности. Речь сейчас пойдет о последнем процессе: кодировании звуковой информации.
Представление звукового потока (как и отдельного звука) может быть произведено при помощи двух способов.
Аналоговая форма представления звуковой информации
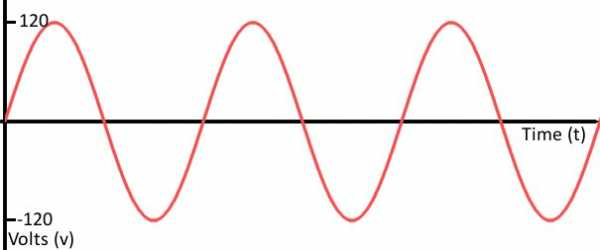
При этом величина может принимать действительно огромное количество различных значений. Причем эти самые значения не остаются постоянными: они очень быстро изменяются, и этот процесс непрерывен.
Дискретная форма представления звуковой информации
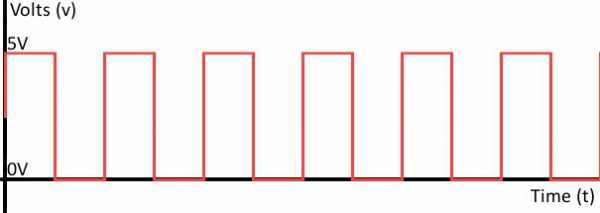
Если же говорить о дискретном способе, то в этом случае величина может принимать только ограниченное количество значений. При этом изменение происходит скачкообразно. Закодировать дискретно можно не только звуковую, но и графическую информацию. Что касается и аналоговой формы, кстати.
Аналоговая звуковая информация хранится на виниловых пластинках, например. А вот компакт-диск уже является дискретным способом представления информации звукового характера.
В самом начале мы говорили о том, что компьютер воспринимает всю информацию на машинном языке. Для этого информация кодируется в форме последовательности электрических импульсов – нулей и единиц. Кодирование звуковой информации не является исключением из этого правила. Чтобы обработать на компьютере звук, его для начала нужно превратить в ту самую последовательность. Только после этого над потоком или единичным звуком могут совершаться операции.
Когда происходит процесс кодирования, поток подвергается временной дискретизации. Звуковая волна непрерывна, она развивается на малые участки времени. Значение амплитуды при этом устанавливается для каждого определенного интервала отдельно.
Заключение
Итак, что же мы выяснили в ходе данной статьи? Во-первых, абсолютно вся информация, которая выводится на монитор компьютера, прежде чем там появиться, подвергается кодированию. Во-вторых, это кодирование заключается в переводе информации на машинный язык. В-третьих, машинный язык представляет собой не что иное, как последовательность электрических импульсов – нулей и единиц. В-четвертых, для кодирования различных символов существуют отдельные таблицы. И, в-пятых, представить графическую и звуковую информацию можно в аналоговом и дискретном виде. Вот, пожалуй, основные моменты, которые мы разобрали. Одной из дисциплин, изучающей данную область, является информатика. Кодирование текстовой информации и его основы объясняются еще в школе, поскольку ничего сложного в этом нет.
www.syl.ru
Презентация к уроку по информатике и икт на тему: Кодирование текста
Слайд 1
Двоичное кодирование текстовой информации Информация и информационные процессыСлайд 2
Двоичное кодирование в компьютере Вся информация, которую обрабатывает компьютер должна быть представлена двоичным кодом с помощью двух цифр: 0 и 1 . Эти два символа принято называть двоичными цифрами или битами . С помощью двух цифр 0 и 1 можно закодировать любое сообщение. Это явилось причиной того, что в компьютере обязательно должно быть организованно два важных процесса: кодирование и декодирование. Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код. Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
Слайд 3
Почему двоичное кодирование С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым, чем применение других способов. Действительно, удобно кодировать информацию в виде последовательности нулей и единиц, если представить эти значения как два возможных устойчивых состояния электронного элемента: 0 – отсутствие электрического сигнала; 1 – наличие электрического сигнала. Эти состояния легко различать. Недостаток двоичного кодирования – длинные коды . Но в технике легче иметь дело с большим количеством простых элементов, чем с небольшим числом сложных. Способы кодирования и декодирования информации в компьютере, в первую очередь, зависит от вида информации, а именно, что должно кодироваться: числа, текст, графические изображения или звук.
Слайд 4
Двоичное кодирование текстовой информации Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации. Традиционно для кодирования одного символа используется количество информации = 1 байту (1 байт = 8 битов).
Слайд 5
1 символ – 1 байт (8 бит) Для кодирования одного символа требуется один байт информации. Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. 2 8 =256
Слайд 6
Двоичное кодирование текстовой информации Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255). Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей.
Слайд 7
Таблица кодировки Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды), называется таблицей кодировки . Для разных типов ЭВМ используются различные кодировки. С распространением IBM PC международным стандартом стала таблица кодировки ASCII ( A merican S tandart C ode for I nformation I nterchange ) – Американский стандартный код для информационного обмена.
Слайд 8
Таблица кодировки ASCII Стандартной в этой таблице является только первая половина, т.е. символы с номерами от 0 (00000000) до 127 (0111111). Сюда входят буква латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов используются в разных вариантах. В русских кодировках размещаются символы русского алфавита. В настоящее время существует 5 разных кодовых таблиц для русских букв (КОИ8, СР1251 , СР866, Mac, ISO ). В настоящее время получил широкое распространение новый международный стандарт Unicode , который отводит на каждый символ два байта. С его помощью можно закодировать 65536 (2 16 = 65536 ) различных символов.
Слайд 11
Информационный объем текста Сегодня очень многие люди для подготовки писем, документов, статей, книг и пр. используют компьютерные текстовые редакторы . Компьютерные редакторы, в основном, работают с алфавитом размером 256 символов . В этом случае легко подсчитать объем информации в тексте. Если 1 символ алфавита несет 1 байт информации , то надо просто сосчитать количество символов; полученное число даст информационный объем текста в байтах. Пусть небольшая книжка, сделанная с помощью компьютера, содержит 150 страниц; на каждой странице — 40 строк, в каждой строке — 60 символов. Значит страница содержит 40×60=2400 байт информации. Объем всей информации в книге: 2400 х 150 = 360 000 байт.
Слайд 12
Обратите внимание! Цифры кодируются по стандарту ASCII в двух случаях – при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в другой двоичных код (см. урок «представление чисел в компьютере»). Возьмем число 57 . При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это – 0011010100110111 . При использовании в вычислениях , код этого числа будет получен по правилам перевода в двоичную систему и получим – 00111001 .
Слайд 13
Вопросы и задания: В чем заключается кодирование текстовой информации в компьютере? Закодируйте с помощью ASCII -кода свою фамилию, имя, номер класса. Какое сообщение закодировано в кодировке Windows-1251: 0011010100100000111000011110000011101011111010111110111011100010 Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинского четверостишия: Певец-Давид был ростом мал, Но повалил же Голиафа!
nsportal.ru
Презентация к уроку (информатика и икт, 10 класс) по теме: Кодирование текстовой информации
Слайд 1
Кодирование текстовой информацииСлайд 2
Кодирование – это процесс представления информации в виде последовательности условных обозначений.
Слайд 3
Код – множество слов (последовательностей символов) из некоторого алфавита, используемых при кодировании информации
Слайд 4
Письменность – способ кодирования устной речи на естественном языке
Слайд 5
Устная речь Код: письменный текст Устная речь Декодирование –чтение текста Кодирование –запись текста Способ кодирования зависит от назначения кода Правило – каждый символ алфавита исходного текста заменяется на комбинацию символов алфавита кодирования
Слайд 6
Телеграфный код ITA2 Буквы знаки символы A R Режим ввода букв
Слайд 7
Кодировка ASCII ( American Standard Code for Information Interchang ) – 1963 год – для компьютерной обработки текстовой информации кодирующая первую половину символов с числовыми кодами от 0 до 127 (коды от 0 до 32 отведены не символам, а функциональным клавишам).
Слайд 8
Код символа – порядковый номер Первые 32 символа – управляющие. На экране не отражаются, определяют некоторое действие.
Слайд 9
Расширение кода ASCII 1 – 127 совпадают с ASCII 128 – 225 – кодовая страница. Размещаются нелатинские алфавиты, символы псевдографики…
Слайд 10
Наиболее распространенной в настоящее время является кодировка Microsoft Windows , обозначаемая сокращением CP1251 («CP» означает » Code Page «, «кодовая страница»).
Слайд 11
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный «). Unix
Слайд 13
В конце 90-ых годов появился новый международный стандарт Unicode , который отводит под один символ не один байт, а два, и поэтому с его помощью можно закодировать не 256, а 65536 различных символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов
Слайд 14
Фрагмент спецификации UNICODE 4.0 для кириллицы
Слайд 15
Пример 1. Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуйтесь компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления
Слайд 16
Ответ Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц: КОИ8-Р: 252 247 237 CP 1251: 221 194 204 CP866: 157 130 140 Mac: 157 130 140 ISO: 205 178 188 Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную: КОИ8-Р: FC F 7 ED CP1251: DD C2 CC CP866: 9D 82 8C Mac: 9D 82 8C ISO: CD B2 BC
Слайд 17
Для преобразования русскоязычных текстовых документов из одной кодировки в другую используются специальные программы-конверторы. Одной из таких программ является текстовый редактор Hieroglyph , который позволяет осуществлять перевод набранного текста из одной кодировки в другую и даже использовать различные кодировки в одном тексте
Слайд 19
Учимся программировать Возвращает символ, соответствующий номеру N в таблице Юникода.
Слайд 20
Возвращает номер символа в таблице КОИ-8r. (стандарт RFC 1489).
nsportal.ru