
Кодирование текстовой информации | Практическая работа 2.1
Планирование уроков на учебный год (по учебнику Н.Д. Угриновича)
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 8 классы | Планирование уроков на учебный год (по учебнику Н.Д. Угриновича) | Кодирование текстовой информации
Содержание урока
Кодирование текстовой информации
Практическая работа 2.1
Практическая работа 2.1
Кодирование текстовой информации
Аппаратное и программное обеспечение. Компьютер с установленной операционной системой Windows или Linux.
Цель работы. Научиться определять числовые коды символов и осуществлять перекодировку русскоязычного текста в текстовом редакторе.
Задание 1. В текстовом редакторе определить числовые (шестнадцатеричные) коды нескольких символов в кодировке Unicode {Юникод).
Задание 2. В текстовом редакторе Hieroglyph представить слово «Кодировка» в пяти различных кодировках: Windows, MS-DOS, КОИ-8, Mac, ISO.
Задание 1. Определение числового кода символа с помощью текстовых редакторов Microsoft Word и OpenOffice.org Writer
1. В операционной системе Windows запустить текстовый редактор Microsoft Word командой [Пуск — Все программы — Microsoft Office — Microsoft Word
Или:
в операционной системе Linux запустить текстовый редактор OpenOffice.org Writer командой [Пуск — Офис — OpenOffice Writer].
Определим числовой код символа в текстовом редакторе Microsoft Word.
2. В текстовом редакторе Microsoft Word ввести команду [Вставка — Символ — Другие символы…]. На экране появится диалоговое окно Символы. Центральную часть диалогового окна занимает фрагмент таблицы символов.
В текстовом редакторе Microsoft Word ввести команду [Вставка — Символ — Другие символы…]. На экране появится диалоговое окно Символы. Центральную часть диалогового окна занимает фрагмент таблицы символов.
3. Для определения числового кода знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица.
4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шести.).
5. В таблице символов выбрать символ (например, заглавную букву «Ё»). В текстовом поле Код знака: появится его шестнадцатеричный числовой код (в данном случае 0401).
Перевод числового кода символа из шестнадцатеричной системы счисления в десятичную систему счисления можно осуществить с помощью программного калькулятора NumLock Calculator.
Определим числовой код символа в текстовом редакторе OpenOffice.org Writer.
6. В текстовом редакторе OpenOffice.org Writer ввести команду [Вставка — Специальные символы…
7. Для определения числового кода знака кириллицы с помощью раскрывающегося списка Набор выбрать пункт Кириллица.
8. В таблице символов выбрать символ (например, заглавную букву «Ё»). В правом нижнем углу диалогового окна появится его шестнадцатеричный числовой код (в данном случае 0401).
Перевод числового кода символа из шестнадцатеричной системы счисления в десятичную систему счисления можно осуществить с помощью программного калькулятора KCalc.
Задание 2. Перекодирование русскоязычного текста в текстовом редакторе Hieroglyph
Перекодирование русскоязычного текста в текстовом редакторе Hieroglyph
Текстовый редактор Иероглиф является на сегодняшний день единственным редактором серьезно ориентированным на работу с русскими текстами с таким обширным набором функций (порядка 30) при совсем небольшом размере (порядка 3 MB в архиве). Иероглиф может использоваться как редактор по умолчанию вместо Notepad и Wordpad. Иероглиф является хорошим дополнением к Microsoft Word. Иероглиф также заменит вам все ваши программы перекодировки, работы с испорченной почтой, работы с UNICODE и решит все проблемы русификации.
Загрузить текстовый редактор Иероглиф:
✑ С сайта Hieroglyph Web Page.
✑ Скачать архив установочных файлов (Hieroglyph.zip) редактора.
1. В операционной системе Windows запустить текстовый редактор Hieroglyph командой [Пуск — Все программы — Hieroglyph].
2. В раскрывающемся списке исходных кодировок выбрать кодировку WIN и ввести текст: «Кодировка Windows».
3. Скопировать текст четыре раза.
Последовательно выделить строки, выбрать для каждой конечную кодировку в раскрывающемся списке (DOS, ISO, KOI и Mac), нажать кнопку Перевод кодировки.
Для каждой кодировки отредактировать ее название.
4. В результате получим пять строк символов в различных кодировках, где первое слово в каждой строке соответствует одной и той же последовательности числовых кодов.
Cкачать материалы урока
Краткое объяснение кодирования текстовой информации. Информатика / Справочник :: Бингоскул
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении.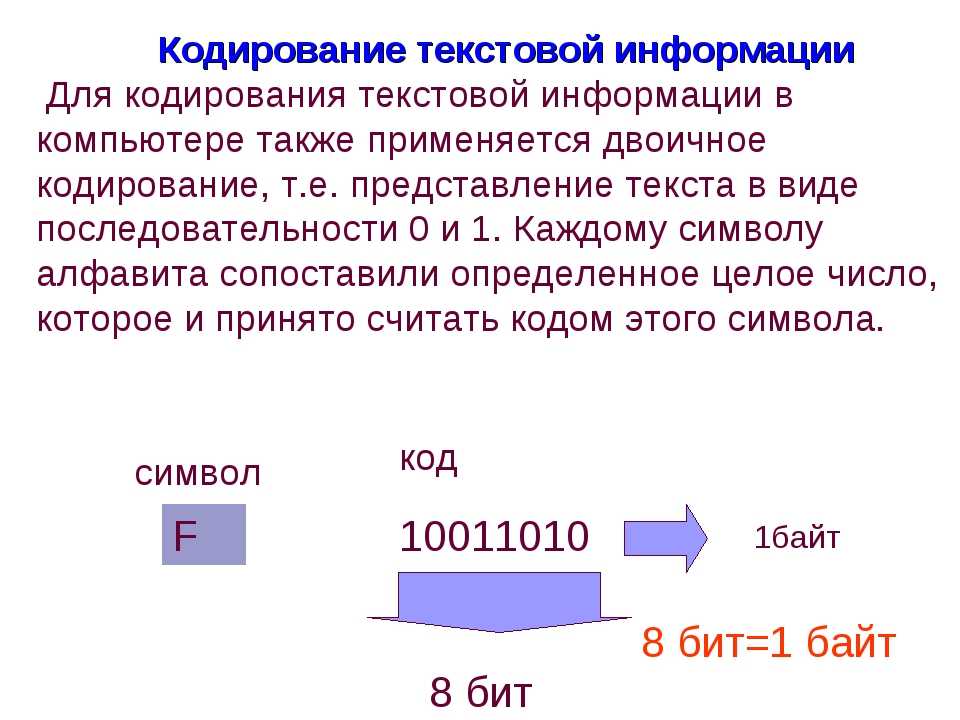 Суть кодировки заключалась в простой последовательности электрических импульсов:
Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов.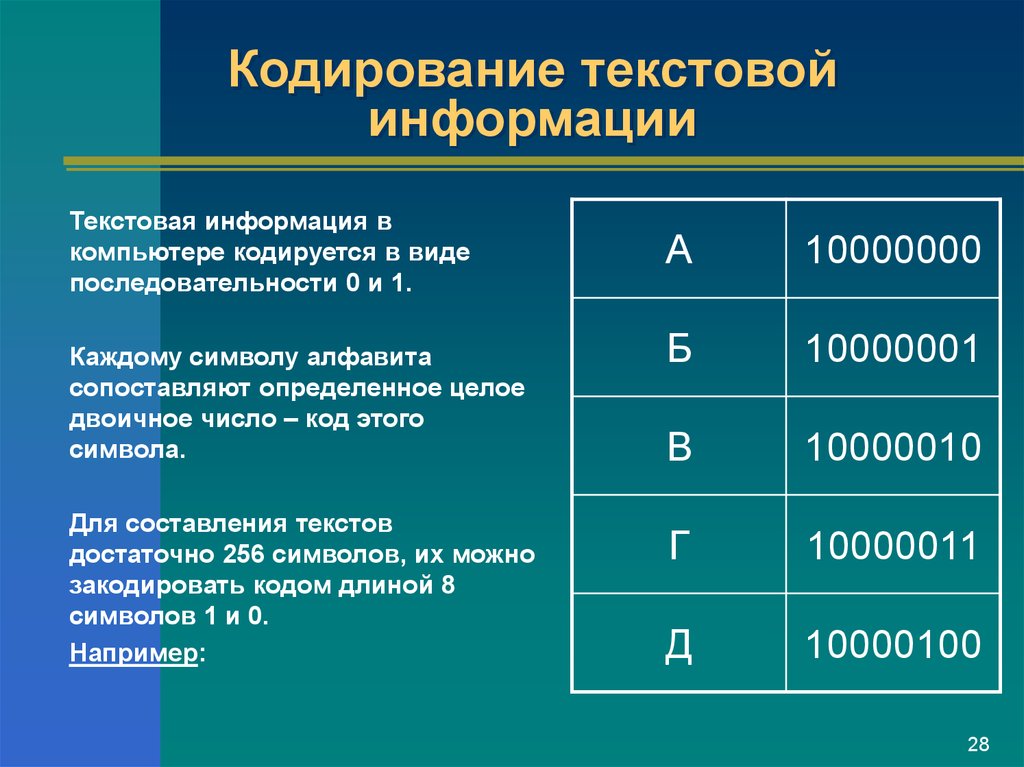 Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
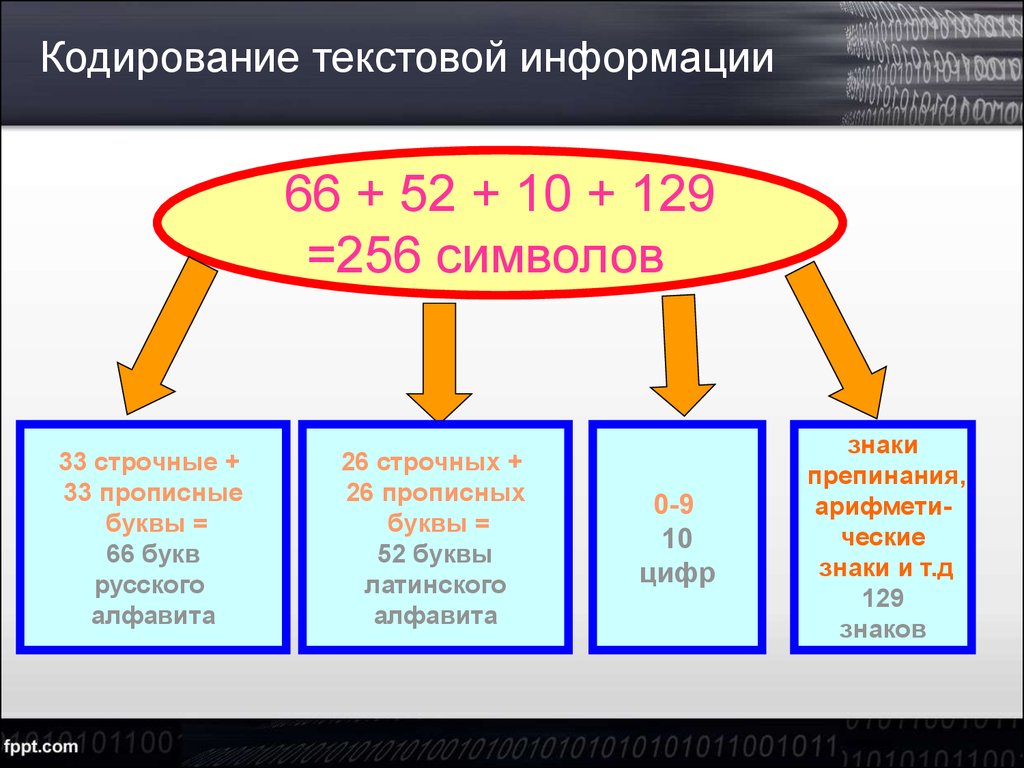
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.
Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Наиболее популярные таблицы кодировки:
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.
Заключение
Кодирование текстовой информации — это обычный и стандартный процесс, который происходит во всех современных компьютерах. Раньше чаще ощущалась проблема с кодировками при переносе одного текста между компьютерами. Теперь таких проблем меньше, потому что во многих устройствах имеются встроенные программы-конверторы, которые автоматически отслеживают кодировки и находят нужную, чтобы пользователь об этом вообще не беспокоился.
Кодировка текста | Электронные тексты в гуманитарных науках: принципы и практика
Фильтр поиска панели навигации Oxford AcademicЭлектронные тексты по гуманитарным наукам: принципы и практикаЛитературоведение (начиная с 20-го века)Теория литературы и культурологияКнигиЖурналы Термин поиска мобильного микросайта
Закрыть
Фильтр поиска панели навигации Oxford AcademicЭлектронные тексты по гуманитарным наукам: принципы и практикаЛитературоведение (начиная с 20-го века)Теория литературы и культурологияКнигиЖурналы Термин поиска на микросайте
Расширенный поиск
Иконка Цитировать Цитировать
Разрешения
- Делиться
- Твиттер
- Подробнее
CITE
Hockey, Susan,
‘Текст Кодирование
,
Электронные тексты в гуманитарных науках: Принципы и практика
(
Oxford,
2000;
Online Edn,
Oxford Academar
, 3 октября 2011 г.
), https://doi.org/10.1093/acprof:oso/9780198711940.003.0003,
по состоянию на 1 ноября 2022 г.
Выберите формат Выберите format.ris (Mendeley, Papers, Zotero).enw (EndNote).bibtex (BibTex).txt (Medlars, RefWorks)
Закрыть
Фильтр поиска панели навигации Oxford AcademicЭлектронные тексты по гуманитарным наукам: принципы и практикаЛитературоведение (начиная с 20-го века)Теория литературы и культурологияКнигиЖурналы Термин поиска мобильного микросайта
Закрыть
Фильтр поиска панели навигации Oxford AcademicЭлектронные тексты по гуманитарным наукам: принципы и практикаЛитературоведение (начиная с 20-го века)Теория литературы и культурологияКнигиЖурналы Термин поиска на микросайте
Advanced Search
Abstract
В этой главе рассматриваются схемы кодирования, необходимые для придания тексту интеллектуального характера. Целью кодирования в тексте является предоставление информации, которая поможет компьютерной программе выполнять функции над этим текстом. Информация, встроенная в текст, по-разному называется кодированием, разметкой или маркировкой, хотя термин «маркировка» также используется несколько более узко в корпусной лингвистике для обозначения кодирования грамматических категорий и, возможно, других лингвистических характеристик. То, какую именно схему разметки использовать, во многом зависит от характера проекта. Для цифровой библиотеки или большого и долгосрочного проекта имеет смысл использовать SGML, а точнее XML, для которого, скорее всего, будет больше поддержки. TEI — очень хорошая отправная точка для материала по гуманитарным наукам, и его можно использовать в качестве основы для разработки специализированной схемы кодирования.
Целью кодирования в тексте является предоставление информации, которая поможет компьютерной программе выполнять функции над этим текстом. Информация, встроенная в текст, по-разному называется кодированием, разметкой или маркировкой, хотя термин «маркировка» также используется несколько более узко в корпусной лингвистике для обозначения кодирования грамматических категорий и, возможно, других лингвистических характеристик. То, какую именно схему разметки использовать, во многом зависит от характера проекта. Для цифровой библиотеки или большого и долгосрочного проекта имеет смысл использовать SGML, а точнее XML, для которого, скорее всего, будет больше поддержки. TEI — очень хорошая отправная точка для материала по гуманитарным наукам, и его можно использовать в качестве основы для разработки специализированной схемы кодирования.
Ключевые слова: кодирование текста, ввод с клавиатуры, разметка, алфавит, HTML, TEI, XML
Предмет
Литературоведение (начиная с 20-го века) Теория литературы и культурология
В настоящее время у вас нет доступа к этой главе.
Войти
Получить помощь с доступом
Получить помощь с доступом
Доступ для учреждений
Доступ к контенту в Oxford Academic часто предоставляется посредством институциональных подписок и покупок. Если вы являетесь членом учреждения с активной учетной записью, вы можете получить доступ к контенту одним из следующих способов:
Доступ на основе IP
Как правило, доступ предоставляется через институциональную сеть к диапазону IP-адресов. Эта аутентификация происходит автоматически, и невозможно выйти из учетной записи с IP-аутентификацией.
Войдите через свое учреждение
Выберите этот вариант, чтобы получить удаленный доступ за пределами вашего учреждения. Технология Shibboleth/Open Athens используется для обеспечения единого входа между веб-сайтом вашего учебного заведения и Oxford Academic.
- Нажмите Войти через свое учреждение.
- Выберите свое учреждение из предоставленного списка, после чего вы перейдете на веб-сайт вашего учреждения для входа.
- При посещении сайта учреждения используйте учетные данные, предоставленные вашим учреждением. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если вашего учреждения нет в списке или вы не можете войти на веб-сайт своего учреждения, обратитесь к своему библиотекарю или администратору.
Войти с помощью читательского билета
Введите номер своего читательского билета, чтобы войти в систему. Если вы не можете войти в систему, обратитесь к своему библиотекарю.
Члены общества
Доступ члена общества к журналу достигается одним из следующих способов:
Войти через сайт сообщества
Многие общества предлагают единый вход между веб-сайтом общества и Oxford Academic. Если вы видите «Войти через сайт сообщества» на панели входа в журнале:
Если вы видите «Войти через сайт сообщества» на панели входа в журнале:
- Щелкните Войти через сайт сообщества.
- При посещении сайта общества используйте учетные данные, предоставленные этим обществом. Не используйте личную учетную запись Oxford Academic.
- После успешного входа вы вернетесь в Oxford Academic.
Если у вас нет учетной записи сообщества или вы забыли свое имя пользователя или пароль, обратитесь в свое общество.
Войти с помощью личного кабинета
Некоторые общества используют личные аккаунты Oxford Academic для предоставления доступа своим членам. Смотри ниже.
Личный кабинет
Личную учетную запись можно использовать для получения оповещений по электронной почте, сохранения результатов поиска, покупки контента и активации подписок.
Некоторые общества используют личные аккаунты Oxford Academic для предоставления доступа своим членам.
Просмотр учетных записей, вошедших в систему
Щелкните значок учетной записи в правом верхнем углу, чтобы:
- Просмотр вашей личной учетной записи и доступ к функциям управления учетной записью.
- Просмотр институциональных учетных записей, предоставляющих доступ.
Выполнен вход, но нет доступа к содержимому
Oxford Academic предлагает широкий ассортимент продукции. Подписка учреждения может не распространяться на контент, к которому вы пытаетесь получить доступ. Если вы считаете, что у вас должен быть доступ к этому контенту, обратитесь к своему библиотекарю.
Ведение счетов организаций
Для библиотекарей и администраторов ваша личная учетная запись также предоставляет доступ к управлению институциональной учетной записью. Здесь вы найдете параметры для просмотра и активации подписок, управления институциональными настройками и параметрами доступа, доступа к статистике использования и т. д.
д.
Покупка
Наши книги можно приобрести по подписке или приобрести в библиотеках и учреждениях.
Информация о покупке
Категория: Кодированный текст — предварительные версии
19.08.2015 0 комментариев
Ланкшир и Нобель утверждают: «Если мы рассматриваем грамотность как «просто чтение и письмо» — будь то в смысле кодирования и декодирования печатного текста, как инструмент, набор навыков, или технологию, или как своего рода психологический процесс – мы не можем осмыслить свой опыт грамотности. Чтение (или письмо) — это всегда чтение чего-то в частности с пониманием… Обучение чтению и написанию определенных видов текстов определенными способами предполагает погружение в социальные практики, где участники «не только читают тексты таким образом, но и говорят о таких текстах определенным образом». , придерживаются определенных взглядов и ценностей по отношению к ним, и социальные взаимодействия в отношении них определенным образом» (2). Кроме того, они подчеркивают, что текст создает смысл, но содержание текста может не иметь буквального значения. «Смысл, заключенный в содержании, может быть гораздо более относительным, чем буквальным» (4). Они также заявляют: «Почти все, что доступно в Интернете, становится ресурсом для различных видов создания смысла» (5). Авторы определяют «новую» грамотность в двух областях: новые технические вещи и новые этносы. «[I] Если в грамотности нет того, что мы называем новым этносом, мы не рассматриваем ее как новую грамотность, даже если в ней есть новые технические детали… Мы думаем, что центральным для новой грамотности является… виды ценностей, приоритетов и чувств, чем грамотность, с которой мы знакомы … Распространение и реализация нового материала этоса становится возможным с новыми технологиями, но сам материал этоса не зависит от них. И наоборот, новые технологии могут быть приняты без и даже в противовес новому этосу» (7, 21). Новые технические средства «представляют собой квантовый сдвиг за пределы типографских средств производства текста, а также за пределы аналоговых форм производства звука и изображения» (8–9). «Таким образом, «новый этнос» включает в себя дух ценностей и приоритетов Web 2.0, таких как включение… активное сотрудничество и участие, использование коллективного разума с помощью таких методов, как получение аннотаций пользователей, распространение и умышленное совместное использование. экспертиза, децентрирование авторства, мобилизация информации для родства, гибридизация и тому подобное» (20). Ключевые термины
|

 ). Новый этос включает в себя разделенное пространство — сосуществование физического пространства и киберпространства — и новое мышление — физически-индустриальное против киберпространственно-постиндустриального. Вот два образа мышления:
). Новый этос включает в себя разделенное пространство — сосуществование физического пространства и киберпространства — и новое мышление — физически-индустриальное против киберпространственно-постиндустриального. Вот два образа мышления: 
