
Симметричные шифры
Симметричные шифрыСимметричные шифры
Симметричные криптосистемы (также симметричное шифрование, симметричные шифры) — способ шифрования, в котором для (за)шифрования и расшифровывания применяется один и тот же криптографический ключ. До изобретения схемы асимметричного шифрования единственным существовавшим способом являлось симметричное шифрование. Ключ алгоритма должен сохраняться в секрете обеими сторонами. Алгоритм шифрования выбирается сторонами до начала обмена сообщениями.
Алгоритмы шифрования и дешифрования данных широко применяются в компьютерной технике в системах сокрытия конфиденциальной и коммерческой информации от злонамеренного использования сторонними лицами. Главным принципом в них является условие, что передатчик и приемник заранее знают алгоритм шифрования, а также ключ к сообщению, без которых информация представляет собой всего лишь набор символов, не имеющих смысла.
- Простая перестановка
- Одиночная перестановка по ключу
- Двойная перестановка
- Перестановка «Магический квадрат»
- Требования
- Общая схема
- Параметры алгоритмов
- Распространенные алгоритмы
- Сравнение с асимметричными криптосистемами
Простая перестановка без ключа — один из самых простых методов шифрования. Сообщение записывается в таблицу по столбцам. После того, как открытый текст записан колонками, для образования шифровки он считывается по строкам. Для использования этого шифра отправителю и получателю нужно договориться об общем ключе в виде размера таблицы. Объединение букв в группы не входит в ключ шифра и используется лишь для удобства записи несмыслового текста.
Сообщение записывается в таблицу по столбцам. После того, как открытый текст записан колонками, для образования шифровки он считывается по строкам. Для использования этого шифра отправителю и получателю нужно договориться об общем ключе в виде размера таблицы. Объединение букв в группы не входит в ключ шифра и используется лишь для удобства записи несмыслового текста.
Более практический метод шифрования, называемый одиночной перестановкой по ключу очень похож на предыдущий. Он отличается лишь тем, что колонки таблицы переставляются по ключевому слову, фразе или набору чисел длиной в строку таблицы.
Для дополнительной скрытности можно повторно шифровать сообщение, которое уже было зашифровано. Этот способ известен под названием двойная перестановка. Для этого размер второй таблицы подбирают так, чтобы длины ее строк и столбцов были другие, чем в первой таблице. Лучше всего, если они будут взаимно простыми. Кроме того, в первой таблице можно переставлять столбцы, а во второй строки. Наконец, можно заполнять таблицу зигзагом, змейкой, по спирали или каким-то другим способом. Такие способы заполнения таблицы если и не усиливают стойкость шифра, то делают процесс шифрования гораздо более занимательным.
Наконец, можно заполнять таблицу зигзагом, змейкой, по спирали или каким-то другим способом. Такие способы заполнения таблицы если и не усиливают стойкость шифра, то делают процесс шифрования гораздо более занимательным.
Магическими квадратами называются квадратные таблицы со вписанными в их клетки последовательными натуральными числами от 1, которые дают в сумме по каждому столбцу, каждой строке и каждой диагонали одно и то же число. Подобные квадраты широко применялись для вписывания шифруемого текста по приведенной в них нумерации. Если потом выписать содержимое таблицы по строкам, то получалась шифровка перестановкой букв. На первый взгляд кажется, будто магических квадратов очень мало. Тем не менее, их число очень быстро возрастает с увеличением размера квадрата. Так, существует лишь один магический квадрат размером 3 х 3, если не принимать во внимание его повороты. Магических квадратов 4 х 4 насчитывается уже 880, а число магических квадратов размером 5 х 5 около 250000.
В квадрат размером 4 на 4 вписывались числа от 1 до 16. Его магия состояла в том, что сумма чисел по строкам, столбцам и полным диагоналям равнялась одному и тому же числу — 34. Впервые эти квадраты появились в Китае, где им и была приписана некоторая «магическая сила».
Шифрование по магическому квадрату производилось следующим образом. Например, требуется зашифровать фразу: «Приезжаю сегодня». Буквы этой фразы вписываются последовательно в квадрат согласно записанным в них числам: позиция буквы в предложении соответствует порядковому числу. В пустые клетки ставится точка.
После этого шифрованный текст записывается в строку (считывание производится слева направо, построчно): .ИРДЗЕГЮСЖАОЕЯНП
При расшифровывании текст вписывается в квадрат, и открытый текст читается в последовательности чисел «магического квадрата» Программа должна генерировать «магические квадраты» и по ключу выбирать необходимый.
Полная утрата всех статистических закономерностей исходного сообщения является важным требованием к симметричному шифру. Для этого шифр должен иметь «эффект лавины» — должно происходить сильное изменение шифроблока при 1битном изменении входных данных (в идеале должны меняться значения 1/2 бит шифроблока).
Также важным требованием является отсутствие линейности (то есть условия f(a) xor f(b) == f(a xor b)), в противном случае облегчается применение дифференциального криптоанализа к шифру.
В настоящее время симметричные шифры — это:
- блочные шифры. Обрабатывают информацию блоками определённой длины (обычно 64, 128 бит), применяя к блоку ключ в установленном порядке, как правило, несколькими циклами перемешивания и подстановки, называемыми раундами. Результатом повторения раундов является лавинный эффект — нарастающая потеря соответствия битов между блоками открытых и зашифрованных данных.

- поточные шифры, в которых шифрование проводится над каждым битом либо байтом исходного (открытого) текста с использованием гаммирования. Поточный шифр может быть легко создан на основе блочного (например, ГОСТ 28147-89 в режиме гаммирования), запущенного в специальном режиме.

Большинство симметричных шифров используют сложную комбинацию большого количества подстановок и перестановок. Многие такие шифры исполняются в несколько (иногда до 80) проходов, используя на каждом проходе «ключ прохода». Множество «ключей прохода» для всех проходов называется «расписанием ключей» (key schedule). Как правило, оно создается из ключа выполнением над ним неких операций, в том числе перестановок и подстановок.
Типичным способом построения алгоритмов симметричного шифрования является сеть Фейстеля. Алгоритм строит схему шифрования на основе функции F(D, K), где D — порция данных, размером вдвое меньше блока шифрования, а K — «ключ прохода» для данного прохода.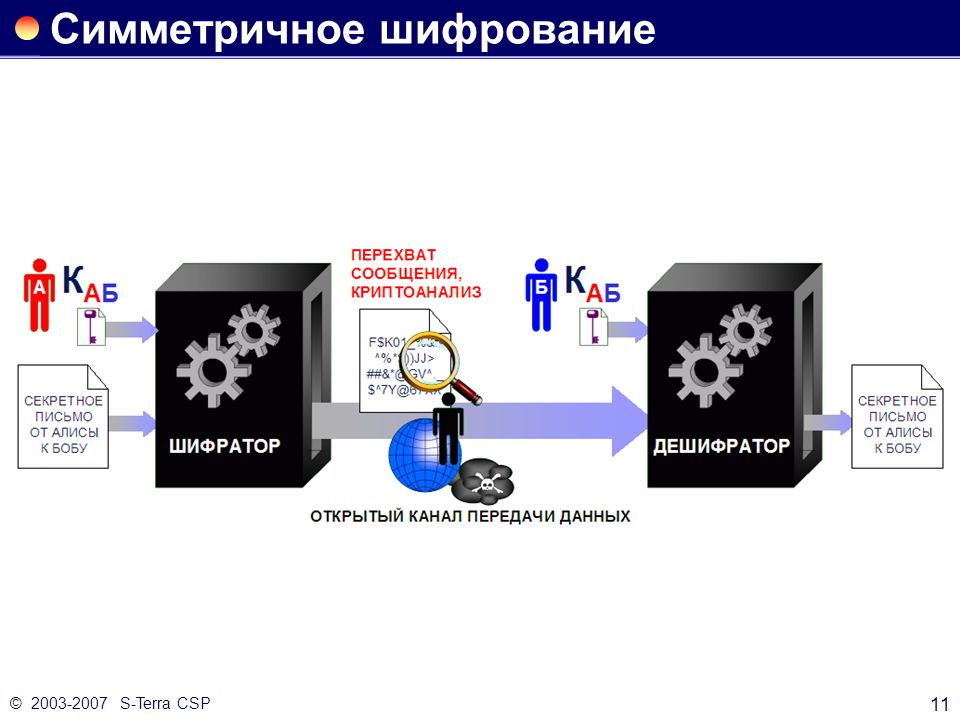 От функции не требуется обратимость — обратная ей функция может быть неизвестна. Достоинства сети Фейстеля — почти полное совпадение дешифровки с шифрованием (единственное отличие — обратный порядок «ключей прохода» в расписании), что сильно облегчает аппаратную реализацию.
От функции не требуется обратимость — обратная ей функция может быть неизвестна. Достоинства сети Фейстеля — почти полное совпадение дешифровки с шифрованием (единственное отличие — обратный порядок «ключей прохода» в расписании), что сильно облегчает аппаратную реализацию.
Операция перестановки перемешивает биты сообщения по некоему закону. В аппаратных реализациях она тривиально реализуется как перепутывание проводников. Именно операции перестановки дают возможность достижения «эффекта лавины». Операция перестановки линейна — f(a) xor f(b) == f(a xor b)
Операции подстановки выполняются как замена значения некоей части сообщения (часто в 4, 6 или 8 бит) на стандартное, жестко встроенное в алгоритм иное число путем обращения к константному массиву. Операция подстановки привносит в алгоритм нелинейность.
Зачастую стойкость алгоритма, особенно к дифференциальному криптоанализу, зависит от выбора значений в таблицах подстановки (S-блоках). Как минимум считается нежелательным наличие неподвижных элементов S(x) = x, а также отсутствие влияния какого-то бита входного байта на какой-то бит результата — то есть случаи, когда бит результата одинаков для всех пар входных слов, отличающихся только в данном бите.
Как минимум считается нежелательным наличие неподвижных элементов S(x) = x, а также отсутствие влияния какого-то бита входного байта на какой-то бит результата — то есть случаи, когда бит результата одинаков для всех пар входных слов, отличающихся только в данном бите.
Существует множество (не менее двух десятков) алгоритмов симметричных шифров, существенными параметрами которых являются:
- стойкость
- длина ключа
- число раундов
- длина обрабатываемого блока
- сложность аппаратной/программной реализации
- сложность преобразования
Блочные шифры:
- AES (англ. Advanced Encryption Standard) — американский стандарт шифрования
- ГОСТ 28147-89 — отечественный стандарт шифрования данных
- DES (англ. Data Encryption Standard) — стандарт шифрования данных в США до AES
- 3DES (Triple-DES, тройной DES)
- RC6 (Шифр Ривеста)
- Twofish
- IDEA (англ. International Data Encryption Algorithm)
- SEED — корейский стандарт шифрования данных
- Camellia — сертифицированный для использовании в Японии шифр
- CAST (по инициалам разработчиков Carlisle Adams и Stafford Tavares)
- XTEA — наиболее простой в реализации алгоритм
 International Data Encryption Algorithm)
International Data Encryption Algorithm)Потоковые шифры:
- RC4 — алгоритм шифрования с ключом переменной длины
- SEAL (Software Efficient Algorithm) — программно-эффективный алгоритм
- WAKE (World Auto Key Encryption algorithm) — всемирный алгоритм шифрования на автоматическом ключе
Достоинства:
- скорость (по данным Applied Cryptography — на 3 порядка выше)
- простота реализации (за счёт более простых операций)
- меньшая требуемая длина ключа для сопоставимой стойкости
- изученность (за счёт большего возраста)
Недостатки:
- сложность управления ключами в большой сети.
>> Следующая статья >>
Самое простое объяснение принципа работы современных алгоритмов симметричного шифрования / Хабр
(Нашёл в твиттере тред с очень крутым объяснением работы симметричных шифров. Его написал Colm MacCárthaigh один из основных контрибьюторов Apache. Я спросил разрешение Колма на перевод, он любезно согласился).
Я объясню вам доступным языком, что происходит при шифровании данных. Надеюсь, что без мистики и сложных штук, которые были придуманы криптографами.
Итак, симметричное шифрование — это именно то, что мы используем в большинстве случаев, когда хотим зашифровать кучу данных. Ваш браузер отправляет и получает данные, используя симметричное шифрование. Если вы шифруете файлы или диск, в этом случае тоже работает симметричное шифрование. iMessage, Signal, WhatsApp — все они используют симметричное шифрование для безопасности вашей переписки.
Если вы думаете, что при шифровании данные перемешиваются так, что их никто не может прочитать без ключа, так оно и происходит на самом деле.
Вот простой пример. Допустим, у меня есть строка «Ovaltine» и я хочу её зашифровать. Я мог бы воспользоваться rot13 — очень простым олдскульным шифром Цезаря, который делает хоровод из букв, где a и z держатся за ручки, и заменяет каждую букву другой буквой алфавита, которая находится от заменяемой буквы на расстоянии 13 символов. Таким образом «O» превращается в «B», а «v» становится «i», в итоге «Ovaltine» превращается в «Binygvar». Конечно, это не очень безопасно. Это наивный пример, который очень легко взломать, так как атакующий может выяснить, какая буква встречается чаще всего (обычно в оригинальном тексте это «e») и найти оставшиеся буквы подобным образом.
Сейчас вы можете представить, что должны существовать более хитрые способы «перемешивания» букв. Например, некая сложная схема, в которой «a» переходит в «p», но при повторном шифровании — в «f».
Может даже иногда эта схема начинает шифровать «a» двумя буквами, например «jd» или в что-нибудь другое. Таким образом эта усложнённая схема может зашифровать «Ovaltine» в строку «FGyswDmweeRq» (заметьте, что она стала длиннее). В прошлом появлялись алгоритмы шифрования, которые работали подобным образом, но это совсем не так, как работает современное шифрование.Вместо «перемешивания» букв современное шифрование берёт вашу секретную строку и хитро комбинирует её со случайными данными. Это похоже на rot13 только в двух моментах: шифрование и расшифровка по сути одна и та же операция, и всё происходит «на месте». Действительно, вы заметили что rot13 является одновременно алгоритмом шифрования и расшифровки? rot13(Ovaltine) -> Binygvar, rot13(Binygvar) -> Ovaltine. Я считаю, что это очень красивая симметрия в симметричном шифровании. Но всё же вернёмся к нашей теме. Хитрость заключается в том, что мы используем побитовую операцию XOR. В криптографии, формальной логике и коде программ XOR может обозначаться по разному, но я буду использовать такую нотацию, с которой вы вероятнее всего знакомы.
7 = 3. Возьмите любое число, которое вам нравится или любые данные, и это всегда будет работать — XOR всегда сможет расшифровать себя.Бит за битом — вот как мы в действительности шифруем и расшифровываем данные, нет никакого перемешивания, только XOR-инг. Трудная часть — поиск данных, к которым мы можем применить XOR. Один из подходов заключается в том, чтобы взять большой кусок секретных данных, лежащих под рукой, и использовать его в качестве второго аргумента XOR. При этом все участники процесса передачи зашифрованных данных должны использовать один и тот же набор секретных данных для шифрования и расшифровки. И это будет работать. Правда есть несколько проблем.
Первая проблема. Секретные данные должны казаться случайными. Вы не можете взять текст из книги или что-то в этом роде. Любые паттерны будут проявляться в зашифрованных данных. Это именно то, благодаря чему союзные войска получили преимущество во Второй мировой войне.
Вторая проблема. Вам нельзя переиспользовать секретные данные, так как паттерны проявятся снова.
Таким образом вы как-то должны предоставлять большие куски секретных данных для всех, кто в них нуждается как в шифре Вернама (One-time pad). Это слишком трудно.В современном шифровании мы «генерируем» нужные нам секретные данные из маленьких ключей. Эти ключи гораздо проще таскать с собой и защищать. Вот чем в действительности являются алгоритмы симметричного шифрования — схемами для детерминированной генерации случайных данных из ключа. Часть про «детерминированность» очень важна: два человека с одним и тем же ключом должны генерировать абсолютно один и тот же набор данных, иначе они не смогут понять друг друга. Вероятно, вы слышали про такие алгоритмы: AES, 3DES, DES, RC4, ChaCha20. Все они делают это.
Оказывается, что математическая задача генерации случайного потока данных (в котором нет паттернов в любом предсказуемом виде) с помощью ключа очень сложна. Из этого списка сегодня считаются безопасными только AES и ChaCha20. Другие алгоритмы были взломаны: люди смогли предсказывать их.
Причём AES имеет немного запятнанную репутацию, потому что криптографы говорят следующее:AES — основной и наиболее проанализированный алгоритм шифрования. Абсолютно золотой стандарт! :dark_sunglasses:
Но при этом добавляют:
Реализации AES в программном обеспечении (не в аппаратном) или небезопасны, или медленны, а иногда и не безопасны, и медленны. Он не был разработан с учётом того, что его взлом можно осуществить с помощью анализа кэша. :facepalm:
Не пугайтесь слишком сильно, если это вам непонятно. Главная мысль заключается в следующем: AES шикарен с точки зрения математики, но очень сложен в программной реализации. Но не надо беспокоиться — у нас почти всегда есть поддержка AES на уровне аппаратного обеспечения (список всех процессоров с аппаратной поддержкой AES можно посмотреть тут https://en.wikipedia.org/wiki/AES_instruction_set, — прим. переводчика).
Как бы то ни было, продолжаем… Как эти алгоритмы работают в действительности? Каким образом мы можем взять ключ и безопасно сгенерировать случайный поток данных? Я буду тут немного упрощать и начну с блоков.
Эти алгоритмы получают на вход три параметра и на выходе отдают зашифрованный текст. Входные параметры — ключ, шифруемый текст и… сюрприз — что-то странное под названием «вектор инициализации» (initialization vector, IV).
AES(key, IV, plaintext) -> encrypted_data.
Ключ и IV комбинируются между собой, чтобы создать набор «стартовых условий» для алгоритма; это подобно начальной перестановке или перемешиванию плиток в игре Скрэббл. Одинаковая комбинация ключа и IV всегда будет создавать одинаковый набор стартовых условий. Спрашиваете, почему нам вообще тогда понадобился IV? Нам нужен IV, чтобы мы могли шифровать множество сообщений, используя одинаковый ключ. Без IV, каждый генерируемый поток данных был бы одинаков, и это плохо. Это бы нарушило одно из правил, про которое мы говорили ранее: мы не можем переиспользовать одни и те же данные при шифровании. Таким образом нам нужен IV для перемешивания результата. Но в отличии от ключа IV может быть публичным.
Итак, когда вы шифруете сообщение и отправляете его кому-нибудь, вы также можете добавить: «Эй, а вот IV, который я использовал».
При этом всё ещё критично, чтобы мы не переиспользовали комбинацию ключа и IV, потому что они дали бы нам повторяющиеся случайные данные. Для достижения этого условия есть два пути: 1) IV это некий счётчик, который мы увеличиваем с каждым новым сообщением. 2) IV генерируется случайно, при этом у него достаточно большое значение, поэтому нам не надо сильно беспокоиться о коллизиях. Как бы то ни было, я упомянул, что я буду говорить о блоках.Ключи и IV «смешиваются» или комбинируются таким образом, чтобы создать набор стартовых условий… эти условия на самом деле являются начальным «блоком» случайных данных. Длина этого блока для AES128 128 бит, для AES256 — 256 бит, для ChaCha20 — 512 бит. И вот тут проявляется настоящая магия и индивидуальность конкретного алгоритма шифрования. В действительности их суть заключается в том, каким образом генерируется последовательность блоков и как каждый блок связан со своими соседями. Отношения между этими блоками остаются предсказуемы даже для тех, у кого нет ключа.
Я не буду глубоко погружаться в то, как именно работают эти алгоритмы, но если вы хотите узнать больше, я советую вам начать изучение этой темы с линейного конгруэнтного метода (linear congruential generators, LCG). LCG представляет собой функцию, которая создаёт «циклические» блоки данных в случайном и неповторяющемся виде. Затем взгляните на cеть Фе́йстеля (Feistel networks) — следующий уровень развития LCG. Затем разберитесь с S-Boxes, а потом посмотрите на то как Salsa20 создаёт чередование в алгоритме ChaCha20. Всё это гораздо доступнее, чем вы можете подумать!
Итак, мы теперь знаем, как случайный поток данных может быть скомбинирован с текстом, чтобы его зашифровать и расшифровать, и мы уже немного в теме того, как эти случайные потоки данных создаются. Разве это не всё, что нам надо? Для шифрования диска, это, действительно, почти всё. Мы можем шифровать каждый блок или сектор хранилища с использованием одного ключа и IV, который может быть получен из «позиции» на диске.
Таким образом мы можем всегда расшифровать любой блок данных в любом месте на диске, до тех пор пока у нас есть ключ. Но тут есть одна проблемка… кто-нибудь может испортить наши зашифрованные данные. Если я изменю значение любого байта, даже если у меня не будет ключа, то в итоге мы не сможем расшифровать блок. И нет защиты против вмешательства такого вида. В случае отправки сообщений и данных по сети, это становится ещё критичнее. Мы не хотим, чтобы кто-нибудь мог испортить наши передаваемые данные. Таким образом нам надо добавить проверку целостности! Есть несколько схем, для того чтобы это сделать.HMAC, GCM и Poly1305 — наиболее распространённые современные схемы для проверки целостности. Эти алгоритмы по большому счёту работают так: им на вход подаются данные и другой ключ (так называемый ключ целостности). После вычислений они выдают на выходе MAC (message authentication code) или тэг, который в свою очередь просто другой кусочек данных, выступающий подписью.
Таким образом для шифрования и защиты наша схема может выглядеть так:
AES(key, IV, "Ovaltine") -> encrypted_output HMAC(key, encrypted_output) -> MAC
и затем по проводам мы отправляем:
IV | encrypted_output | MAC
Для расшифровки мы проверяем MAC, генерируя его снова и сравнивая результат с полученным MAC, а затем расшифровываем данные.
Есть внутренние различия в том, как HMAC, GCM и Poly1305 генерируют эти подписи, но вам не надо об этом беспокоиться. На сегодняшний день эту комбинацию операций обычно оборачивают в функцию с именем «AEAD» (Authenticated Encryption with Additional Data). Под капотом она делает всё то, про что я говорил ранее:AEAD(key, IV, plaintext, additional_data) -> IV_encrypted_data_MAC
Штука под названием «additional_data» — всего лишь данные, с помощью которых вы можете убедиться в том, что эти данные есть у отправляющей стороны, хотя они и не были им отправлены. Это как мета-данные, с помощью которых устанавливаются права доступа. Часто это поле оставляют пустым.
Но тем не менее вы можете поиметь проблемы с AEAD, если будете использовать один и тот же IV. Это плохо! Есть попытки для улучшения этой ситуации: мой коллега, которого зовут Шай, работает над клёвой схемой SIV, добавляющей уровень защиты от этой проблемы. Но если вы используете уникальный IV, современное шифрование очень безопасно.
То есть вы можете опубликовать зашифрованный текст в Нью-Йорк Таймс, и никто не сможет его взломать. Шифр будет оставаться неприступен, даже если «некоторая» часть текста будет известна. Например, в интернет-протоколах большое количество текста известно. HTTP-сервера всегда отвечают одинаково и первые байты всегда известны. Но этот факт совсем не имеет значения — он не поможет атакующему узнать ни кусочка оставшихся данных… Мы прошли долгий путь со времён Второй мировой войны.Но есть атаки, которые работают! Если вы отправляете данные по сети и кто-то отслеживает время и размер сообщений, то зашифрованные данные могут быть взломаны с помощью анализа трафика.
Давайте сначала разберёмся с длиной. Очевидно, что длина — это не скрытая характеристика. И это нормально, если вы пытаетесь защитить свой пароль или номер кредитной карты где-то в середине сообщения. Не очень то и большая проблема. Но это означает, что потенциально любой человек может определить тип контента, который вы отправляете.
Простой пример: если вы отправляете gif с помощью мессенджера и если размер этого изображения уникален, атакующий, перехватывающий ваши данные, может предположить какая именно гифка была только что отправлена. Есть более хитрые версии этой атаки для Google Maps, Netflix, Wikipedia и т.п. Для защиты от этой атаки можно «добивать» отправляемые сообщения дополнительными байтами, таким образом, чтобы все отправляемые сообщения были одинаковой длины несмотря ни на что. Шифрование, которое используется в военных сетях, всегда «добивает» трафик дополнительными данными, то есть для перехватчика он всегда выглядит одинаковым! Ещё одна проблема, связанная с длиной, заключается в том, что если вы используете сжатие и даёте атакующему возможность изменять любую часть контента на странице, которую видит пользователь, то это даёт возможность атакующему разузнать даже самые маленькие секреты. Поищите атаку под названием «CRIME». Она шикарна и страшна.Я ещё говорил о том, что другая проблема — тайминг.
Очевидно, что время отправки каждого сообщения открытая информация. Это может быть проблемой? Может! Например, если вы отправляете сообщение на каждое нажатие клавиши, тогда тривиально выяснить, что именно печатается с помощью анализа времени. Круто! Другой пример — VOIP. Если ваше приложение для звонков отправляет данные только тогда, когда люди говорят, но не во время молчания, этого достаточно для того, чтобы восстановить 70% английской речи. Всего лишь из тишины. Страшно клёво.Эти примеры всего лишь верхушка айсберга. Даже когда вы используете алгоритмы и схемы шифрования, которые улучшались в течение 80 лет, всё равно остаются пробелы, с помощью которых можно взломать защиту. Вот почему про это ценно знать!
Как бы то ни было, это тот уровень объяснения, на котором я хочу сейчас остановиться, но мы рассмотрели самое необходимое, что надо знать. Если вы дочитали до этого момента — спасибо! Сейчас у вас должно быть большее понимание того, что происходит при шифровании и чего следует остерегаться.
Не стесняйтесь задавать вопросы
Перевод публикуется под лицензией CC BY-NC-SA 4.0
Шифры с симметричным ключом · Практическая криптография для разработчиков
Работает на GitBook
Symmetric Key Ciphers (например, AES , Chacha20 , RC6 , Twofish , CAST и многие другие) используют тот же ключ (или пароль) до DECRYPT и DECRYPT . Они часто используются в сочетании с другими алгоритмами в схем симметричного шифрования 9.0008 (например, ChaCha20-Poly1305 и AES-128-GCM и AES-256-CTR-HMAC-SHA256 ), часто с паролем для алгоритмов вывода ключа (например, Argon 0 0 Scrypt и 0 Argon и 0 Argon 0 Scrypt ). Шифры с симметричным ключом являются квантово-устойчивыми , что означает, что мощные квантовые компьютеры не смогут нарушить их безопасность (при использовании достаточно больших длин ключей).
Симметричное шифрование/дешифрование Симметричные шифры могут шифровать данные, поступающие в виде блоков фиксированного размера ( блочных шифров ) или данные, поступающие в виде последовательности байтов (потоковые шифры ). Блочные шифры могут быть преобразованы в потоковые шифры с помощью определенных конструкций, известных как «режимы блочного шифра ».Симметричное шифрование и дешифрование используют секретный ключ или кодовую фразу (для получения ключа из нее). Секретный ключ , используемый для шифрования и дешифрования данных, обычно имеет длину 128 или 256 бит и называется «9».0007 ключ шифрования «. Иногда он задается как шестнадцатеричное или целое число в кодировке base64 или выводится с помощью схемы вывода пароля к ключу .
Когда входные данные зашифрованы, они преобразуются в зашифрованный зашифрованный текст , а когда зашифрованный текст расшифровывается, он преобразуется обратно в исходные входные данные.
Симметричное шифрование использует набор алгоритмовВажно понимать, что алгоритмы шифрования с симметричным ключом обычно не работают автономно. Они работают вместе с другими родственными криптоалгоритмами в схема симметричного шифрования / конструкция симметричного шифрования .
В большинстве схем шифрования шифрование сочетается с паролем к алгоритму получения ключа и схемой аутентификации сообщения (см. шифрование с проверкой подлинности). Обычно процедура симметричного шифрования использует последовательность шагов, включающую различные криптоалгоритмы:
- Получение пароля к ключу Алгоритм (например, Scrypt или Argon2): позволяет использовать пароль вместо ключа и делает взлом пароля трудным и медленным.
- Преобразование блочного шифрования в потоковое алгоритм (режим блочного шифрования, например CBC или CTR ) + заполнение сообщения алгоритм, аналогичный PKCS7 (в некоторых режимах): для обеспечения шифрования данных произвольного размера с использованием алгоритма блочного шифрования (например, AES ).
- Алгоритм блочного шифрования (например, AES ): для надежного шифрования блоков данных фиксированной длины с использованием секретного ключа.
- Аутентификация сообщения 9Алгоритм 0008 (аналогично HMAC ): проверить, совпадает ли полученный результат после расшифровки с исходным сообщением до шифрования.
Позже в этом разделе мы предоставим более подробную информацию и примеры того, как настроить и использовать симметричные блочные шифры (например, AES) вместе со всеми вышеописанными алгоритмами для безопасного шифрования и дешифрования сообщений произвольного размера.
Популярные симметричные алгоритмы — Практическая криптография для разработчиков
Алгоритмы шифрования с симметричным ключом (например, AES ) разработаны математиками и криптографами с идеей, что невозможно расшифровать зашифрованный текст без ключа шифрования.
Это верно для современных алгоритмов безопасного симметричного шифрования (таких как AES и ChaCha20) и может быть спорным или ложным для других, которые считаются небезопасные алгоритмы симметричного шифрования (например, DES и RC4).Some popular symmetric encryption algorithms are: AES , ChaCha20 , CAST , Twofish , IDEA , Serpent , RC5 , RC6 , Camellia and ARIA .
Все эти алгоритмы считаются безопасными (при правильной настройке и использовании).АЕС ( Рейндал)
AES ( A dvanced E ncryption S tandard, также известный как Rijndael ) — самый популярный и широко используемый современный алгоритм симметричного шифрования в ИТ-индустрии.
Это связано с тем, что AES доказал свою высокую безопасность , быструю и хорошо стандартизированную и очень хорошо поддерживаемую практически на всех платформах. AES представляет собой 128-битный блочный шифр и использует 128, 192 или 256-битные секретные ключи. Обычно используется в блочный режим , например AES-CTR или AES-GCM для обработки потоковых данных. В большинстве блочных режимов AES также требуется случайный 128-битный начальный вектор (IV, одноразовый номер).Rijndael стал победителем конкурса AES, организованного NIST (1997-2000), и был официально объявлен под названием « AES » (следующий официальный симметричный блочный шифр после DES).
В 2001 году AES был принят в качестве официальной рекомендации правительством США , и с этого момента не было обнаружено никаких существенных недостатков или атак.Алгоритм Rijndael (AES) бесплатен для любого использования: публичного или частного, коммерческого или некоммерческого.
SALSA20 / Chacha20
Salsa20 , а также улучшенные варианты Chacha ( Chacha8 , Chacha12 , 58, 9028, 9028, 9028, 9028, 9028, 9028, 9028, , , 9028, 9028, , , 9028, , , 9028, , , , 9028, , , 9028, , .
симметричных потоковых шифров , разработанных выдающимся криптографом Даниэлем Бернштейном. 9Шифр 0221 Salsa20 был одним из финалистов конкурса eSTREAM на разработку новых симметричных потоковых шифров (2004-2008) и впоследствии получил широкое распространение вместе с родственной хэш-функцией BLAKE . Salsa20 и его варианты без лицензионных отчислений , не запатентованы.Шифр Salsa20 принимает на вход 128-битный или 256-битный симметричный секретный ключ + случайно сгенерированный 64-битный одноразовый номер (начальный вектор) и поток данных неограниченной длины и выдает на выходе зашифрованный поток данных той же длины, что и входной поток.
Шифр Salsa20 обычно используется в качестве аутентифицированной конструкции шифрования: ЧаЧа20-Поли1305 .Другие популярные симметричные шифры
Другие современные безопасные симметричные шифры , используемые реже, чем EAS и ChaCha20, но все еще популярные в сообществах разработчиков программного обеспечения и информационной безопасности:
- 3 — безопасный блочный шифр с симметричным ключом (размер ключа: 128, 192 или 256 бит), общественное достояние, не запатентован
Twofish 2 или 256 бит), без лицензионных отчислений, не запатентовано — коммерческое использование
RC5 — безопасный блочный шифр с симметричным ключом (размер ключа: от 128 до 2040 бит; размер блока: 32, 64 или 128 бит; раунды: 1 .
.. 255), небезопасный с короткими ключами (56-битный ключ успешно взломан), был запатентован до 2015 года, сейчас не требует лицензионных отчислений RC6 — безопасный блочный шифр с симметричным ключом, аналогичный RC5, но более сложный (размер ключа: от 128 до 2040 бит; размер блока: 32, 64 или 128 бит; раунды: 1 … 255) , был запатентован до 2017 г., теперь безвозмездный (CAST-128/CAST5, CAST-256/CAST6) — семейство безопасных блочных шифров с симметричным ключом (размеры ключей: 40…256 бит), безвозмездная основа для коммерческого и некоммерческого использования
ARIA — безопасный блочный шифр с симметричным ключом, аналогичный AES (размер ключа: 128, 192 или 256 бит), официальный стандарт в Южной Корее, бесплатный для общего пользования
SM4 — безопасный блочный шифр с симметричным ключом, аналогичный AES (размер ключа: 128 бит), официальный стандарт в Китае, бесплатный для общего пользования
теперь считаются небезопасные (сломанные алгоритмы) или имеющие сомнительную безопасность и не рекомендуются больше использовать:
DES — размер ключа 56 бит, практически сломан, может быть взломан 5
3DES (Triple DES) — 64 -битный шифр, считается сломанным
RC2 — 64 -битный шифр, считается сломанным 9005
RC4 — Поток Cipher, Broken, Broken, Broken, Broken, Broken, Broken, Broken, Broken, Broken Practics, Broken Practice, Broken Practice, Broken Practice, Broken Practic продемонстрировал
Blowfish — old 64-bit cipher, broken, practical attacks demonstrated
GOST — Russian 64-bit block cipher, disputable security, considered risky
Symmetric Encryption Schemes / Конструкции
В дополнение к упомянутым выше шифрам с симметричным ключом, криптографы предложили множество симметричных схем шифрования (конструкций), таких как наиболее популярные схемы аутентифицированного шифрования (AEAD):
ChaCha20-Poly1305
The ChaCha20 stream cipher with integrated Poly1305 authenticator (integrated authenticated AEAD encryption)
Requires a 256-bit key and random 96- bit nonce
Исключительно высокая производительность
Реализовано самыми современными криптобиблиотеками
AES-256-GCM
AES-GCM — это блочный шифр AES (Rijndael) в блочном режиме GCM (встроенное шифрование с проверкой подлинности AEAD), ведет себя как потоковый шифр
90 Обязательно 256-битный ключ и случайный 128-битный одноразовый номер (исходный вектор)
Реализован самыми современными криптобиблиотеками


 Может даже иногда эта схема начинает шифровать «a» двумя буквами, например «jd» или в что-нибудь другое. Таким образом эта усложнённая схема может зашифровать «Ovaltine» в строку «FGyswDmweeRq» (заметьте, что она стала длиннее). В прошлом появлялись алгоритмы шифрования, которые работали подобным образом, но это совсем не так, как работает современное шифрование.
Может даже иногда эта схема начинает шифровать «a» двумя буквами, например «jd» или в что-нибудь другое. Таким образом эта усложнённая схема может зашифровать «Ovaltine» в строку «FGyswDmweeRq» (заметьте, что она стала длиннее). В прошлом появлялись алгоритмы шифрования, которые работали подобным образом, но это совсем не так, как работает современное шифрование.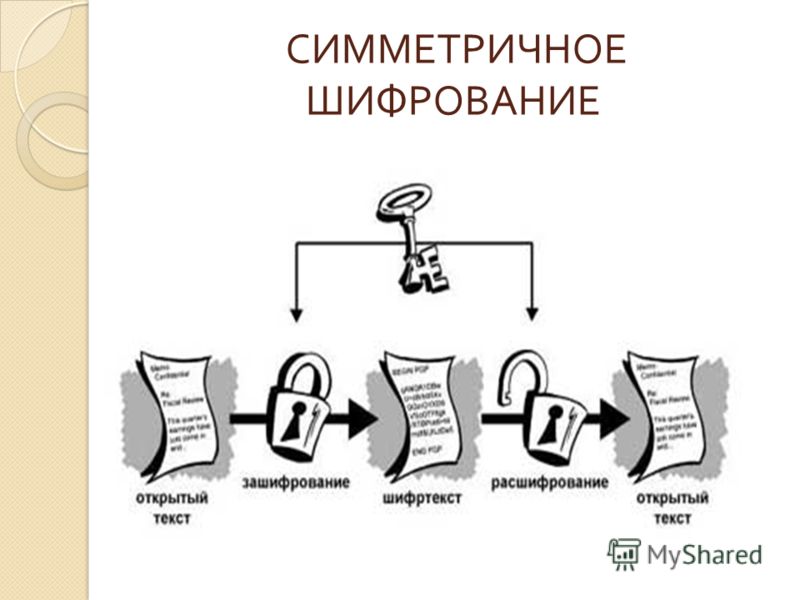 7 = 3. Возьмите любое число, которое вам нравится или любые данные, и это всегда будет работать — XOR всегда сможет расшифровать себя.
7 = 3. Возьмите любое число, которое вам нравится или любые данные, и это всегда будет работать — XOR всегда сможет расшифровать себя. Таким образом вы как-то должны предоставлять большие куски секретных данных для всех, кто в них нуждается как в шифре Вернама (One-time pad). Это слишком трудно.
Таким образом вы как-то должны предоставлять большие куски секретных данных для всех, кто в них нуждается как в шифре Вернама (One-time pad). Это слишком трудно. Причём AES имеет немного запятнанную репутацию, потому что криптографы говорят следующее:
Причём AES имеет немного запятнанную репутацию, потому что криптографы говорят следующее:
 При этом всё ещё критично, чтобы мы не переиспользовали комбинацию ключа и IV, потому что они дали бы нам повторяющиеся случайные данные. Для достижения этого условия есть два пути: 1) IV это некий счётчик, который мы увеличиваем с каждым новым сообщением. 2) IV генерируется случайно, при этом у него достаточно большое значение, поэтому нам не надо сильно беспокоиться о коллизиях. Как бы то ни было, я упомянул, что я буду говорить о блоках.
При этом всё ещё критично, чтобы мы не переиспользовали комбинацию ключа и IV, потому что они дали бы нам повторяющиеся случайные данные. Для достижения этого условия есть два пути: 1) IV это некий счётчик, который мы увеличиваем с каждым новым сообщением. 2) IV генерируется случайно, при этом у него достаточно большое значение, поэтому нам не надо сильно беспокоиться о коллизиях. Как бы то ни было, я упомянул, что я буду говорить о блоках.
 Таким образом мы можем всегда расшифровать любой блок данных в любом месте на диске, до тех пор пока у нас есть ключ. Но тут есть одна проблемка… кто-нибудь может испортить наши зашифрованные данные. Если я изменю значение любого байта, даже если у меня не будет ключа, то в итоге мы не сможем расшифровать блок. И нет защиты против вмешательства такого вида. В случае отправки сообщений и данных по сети, это становится ещё критичнее. Мы не хотим, чтобы кто-нибудь мог испортить наши передаваемые данные. Таким образом нам надо добавить проверку целостности! Есть несколько схем, для того чтобы это сделать.
Таким образом мы можем всегда расшифровать любой блок данных в любом месте на диске, до тех пор пока у нас есть ключ. Но тут есть одна проблемка… кто-нибудь может испортить наши зашифрованные данные. Если я изменю значение любого байта, даже если у меня не будет ключа, то в итоге мы не сможем расшифровать блок. И нет защиты против вмешательства такого вида. В случае отправки сообщений и данных по сети, это становится ещё критичнее. Мы не хотим, чтобы кто-нибудь мог испортить наши передаваемые данные. Таким образом нам надо добавить проверку целостности! Есть несколько схем, для того чтобы это сделать. Есть внутренние различия в том, как HMAC, GCM и Poly1305 генерируют эти подписи, но вам не надо об этом беспокоиться. На сегодняшний день эту комбинацию операций обычно оборачивают в функцию с именем «AEAD» (Authenticated Encryption with Additional Data). Под капотом она делает всё то, про что я говорил ранее:
Есть внутренние различия в том, как HMAC, GCM и Poly1305 генерируют эти подписи, но вам не надо об этом беспокоиться. На сегодняшний день эту комбинацию операций обычно оборачивают в функцию с именем «AEAD» (Authenticated Encryption with Additional Data). Под капотом она делает всё то, про что я говорил ранее: То есть вы можете опубликовать зашифрованный текст в Нью-Йорк Таймс, и никто не сможет его взломать. Шифр будет оставаться неприступен, даже если «некоторая» часть текста будет известна. Например, в интернет-протоколах большое количество текста известно. HTTP-сервера всегда отвечают одинаково и первые байты всегда известны. Но этот факт совсем не имеет значения — он не поможет атакующему узнать ни кусочка оставшихся данных… Мы прошли долгий путь со времён Второй мировой войны.
То есть вы можете опубликовать зашифрованный текст в Нью-Йорк Таймс, и никто не сможет его взломать. Шифр будет оставаться неприступен, даже если «некоторая» часть текста будет известна. Например, в интернет-протоколах большое количество текста известно. HTTP-сервера всегда отвечают одинаково и первые байты всегда известны. Но этот факт совсем не имеет значения — он не поможет атакующему узнать ни кусочка оставшихся данных… Мы прошли долгий путь со времён Второй мировой войны. Простой пример: если вы отправляете gif с помощью мессенджера и если размер этого изображения уникален, атакующий, перехватывающий ваши данные, может предположить какая именно гифка была только что отправлена. Есть более хитрые версии этой атаки для Google Maps, Netflix, Wikipedia и т.п. Для защиты от этой атаки можно «добивать» отправляемые сообщения дополнительными байтами, таким образом, чтобы все отправляемые сообщения были одинаковой длины несмотря ни на что. Шифрование, которое используется в военных сетях, всегда «добивает» трафик дополнительными данными, то есть для перехватчика он всегда выглядит одинаковым! Ещё одна проблема, связанная с длиной, заключается в том, что если вы используете сжатие и даёте атакующему возможность изменять любую часть контента на странице, которую видит пользователь, то это даёт возможность атакующему разузнать даже самые маленькие секреты. Поищите атаку под названием «CRIME». Она шикарна и страшна.
Простой пример: если вы отправляете gif с помощью мессенджера и если размер этого изображения уникален, атакующий, перехватывающий ваши данные, может предположить какая именно гифка была только что отправлена. Есть более хитрые версии этой атаки для Google Maps, Netflix, Wikipedia и т.п. Для защиты от этой атаки можно «добивать» отправляемые сообщения дополнительными байтами, таким образом, чтобы все отправляемые сообщения были одинаковой длины несмотря ни на что. Шифрование, которое используется в военных сетях, всегда «добивает» трафик дополнительными данными, то есть для перехватчика он всегда выглядит одинаковым! Ещё одна проблема, связанная с длиной, заключается в том, что если вы используете сжатие и даёте атакующему возможность изменять любую часть контента на странице, которую видит пользователь, то это даёт возможность атакующему разузнать даже самые маленькие секреты. Поищите атаку под названием «CRIME». Она шикарна и страшна.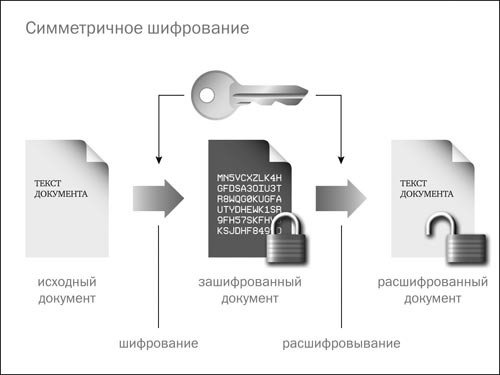 Очевидно, что время отправки каждого сообщения открытая информация. Это может быть проблемой? Может! Например, если вы отправляете сообщение на каждое нажатие клавиши, тогда тривиально выяснить, что именно печатается с помощью анализа времени. Круто! Другой пример — VOIP. Если ваше приложение для звонков отправляет данные только тогда, когда люди говорят, но не во время молчания, этого достаточно для того, чтобы восстановить 70% английской речи. Всего лишь из тишины. Страшно клёво.
Очевидно, что время отправки каждого сообщения открытая информация. Это может быть проблемой? Может! Например, если вы отправляете сообщение на каждое нажатие клавиши, тогда тривиально выяснить, что именно печатается с помощью анализа времени. Круто! Другой пример — VOIP. Если ваше приложение для звонков отправляет данные только тогда, когда люди говорят, но не во время молчания, этого достаточно для того, чтобы восстановить 70% английской речи. Всего лишь из тишины. Страшно клёво.
 Симметричные шифры могут шифровать данные, поступающие в виде блоков фиксированного размера ( блочных шифров ) или данные, поступающие в виде последовательности байтов (потоковые шифры ). Блочные шифры могут быть преобразованы в потоковые шифры с помощью определенных конструкций, известных как «режимы блочного шифра ».
Симметричные шифры могут шифровать данные, поступающие в виде блоков фиксированного размера ( блочных шифров ) или данные, поступающие в виде последовательности байтов (потоковые шифры ). Блочные шифры могут быть преобразованы в потоковые шифры с помощью определенных конструкций, известных как «режимы блочного шифра ».

 Это верно для современных алгоритмов безопасного симметричного шифрования (таких как AES и ChaCha20) и может быть спорным или ложным для других, которые считаются небезопасные алгоритмы симметричного шифрования (например, DES и RC4).
Это верно для современных алгоритмов безопасного симметричного шифрования (таких как AES и ChaCha20) и может быть спорным или ложным для других, которые считаются небезопасные алгоритмы симметричного шифрования (например, DES и RC4). Все эти алгоритмы считаются безопасными (при правильной настройке и использовании).
Все эти алгоритмы считаются безопасными (при правильной настройке и использовании). Это связано с тем, что AES доказал свою высокую безопасность , быструю и хорошо стандартизированную и очень хорошо поддерживаемую практически на всех платформах. AES представляет собой 128-битный блочный шифр и использует 128, 192 или 256-битные секретные ключи. Обычно используется в блочный режим , например AES-CTR или AES-GCM для обработки потоковых данных. В большинстве блочных режимов AES также требуется случайный 128-битный начальный вектор (IV, одноразовый номер).
Это связано с тем, что AES доказал свою высокую безопасность , быструю и хорошо стандартизированную и очень хорошо поддерживаемую практически на всех платформах. AES представляет собой 128-битный блочный шифр и использует 128, 192 или 256-битные секретные ключи. Обычно используется в блочный режим , например AES-CTR или AES-GCM для обработки потоковых данных. В большинстве блочных режимов AES также требуется случайный 128-битный начальный вектор (IV, одноразовый номер).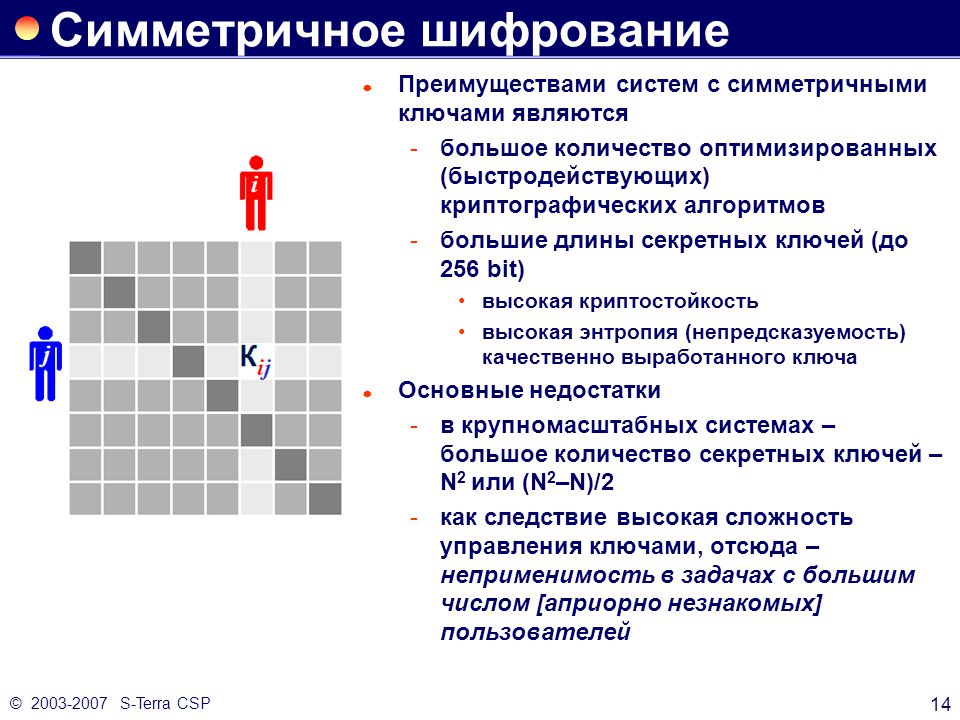 В 2001 году AES был принят в качестве официальной рекомендации правительством США , и с этого момента не было обнаружено никаких существенных недостатков или атак.
В 2001 году AES был принят в качестве официальной рекомендации правительством США , и с этого момента не было обнаружено никаких существенных недостатков или атак. симметричных потоковых шифров , разработанных выдающимся криптографом Даниэлем Бернштейном. 9Шифр 0221 Salsa20 был одним из финалистов конкурса eSTREAM на разработку новых симметричных потоковых шифров (2004-2008) и впоследствии получил широкое распространение вместе с родственной хэш-функцией BLAKE . Salsa20 и его варианты без лицензионных отчислений , не запатентованы.
симметричных потоковых шифров , разработанных выдающимся криптографом Даниэлем Бернштейном. 9Шифр 0221 Salsa20 был одним из финалистов конкурса eSTREAM на разработку новых симметричных потоковых шифров (2004-2008) и впоследствии получил широкое распространение вместе с родственной хэш-функцией BLAKE . Salsa20 и его варианты без лицензионных отчислений , не запатентованы.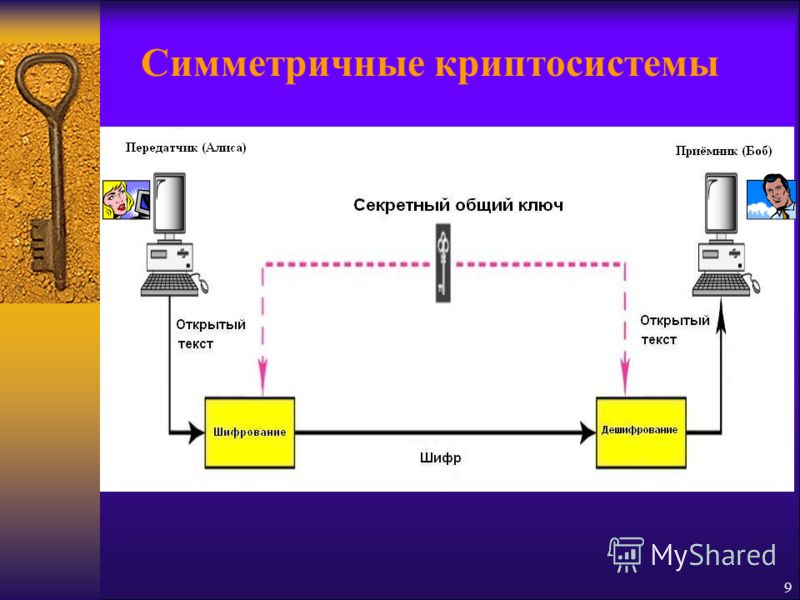 Шифр Salsa20 обычно используется в качестве аутентифицированной конструкции шифрования: ЧаЧа20-Поли1305 .
Шифр Salsa20 обычно используется в качестве аутентифицированной конструкции шифрования: ЧаЧа20-Поли1305 . .. 255), небезопасный с короткими ключами (56-битный ключ успешно взломан), был запатентован до 2015 года, сейчас не требует лицензионных отчислений
.. 255), небезопасный с короткими ключами (56-битный ключ успешно взломан), был запатентован до 2015 года, сейчас не требует лицензионных отчислений Большинство современных приложений должны предпочитать некоторые из вышеперечисленных схем шифрования0008 для симметричного шифрования вместо создания собственной схемы шифрования.